
使用场景-当训练数据不成线性时,多项式回归是给数据进行升维。
测试用例
import numpy as npfrom matplotlib import pyplot as pltx = np.random.uniform(-3, 3, size=100)X = x.reshape(-1, 1)y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)plt.scatter(x, y)

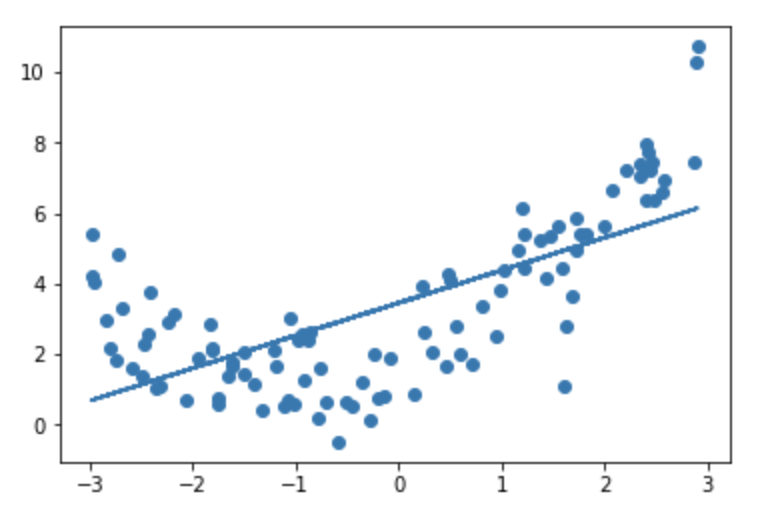
使用线性模型拟合
from sklearn.linear_model import LinearRegressionlin1 = LinearRegression()lin1.fit(X, y)y_p = lin1.predict(X)plt.scatter(x, y)plt.plot(x, y_p)
将数据升维
X2 = np.hstack([X, X**2])lin2 = LinearRegression()lin2.fit(X2, y)plt.scatter(x, y)plt.plot(np.sort(x), lin2.predict(X2)[np.argsort(x)], color='r')

PolynomialFeatures进行封装多项式回归
from sklearn.preprocessing import PolynomialFeaturesdef PolynomiaRegression(X, y, degree):poly = PolynomialFeatures(degree=degree)X2 = poly.fit_transform(X)lin3 = LinearRegression()lin3.fit(X2, y)return lin3poly_reg = PolynomiaRegression(X, y, 2)poly = PolynomialFeatures(degree=2)X3 = poly.fit_transform(X)plt.scatter(x, y)plt.plot(np.sort(x), poly_reg.predict(X3)[np.argsort(x)], color='r')

Pipeline-管道的使用
from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerdef PolynomiaRegression(degree):return Pipeline([('poly', PolynomialFeatures(degree=degree)),('std', StandardScaler()),('line', LinearRegression())])poly_reg = PolynomiaRegression(2)poly_reg.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), poly_reg.predict(X)[np.argsort(x)], color='r')

过拟合和欠拟合
过拟合:训练数据集误差较小,测试集误差较大。
欠拟合:训练集和测试集的误差都大。
# 引入均方误差from sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import train_test_split# 简单线性回归模型训练和预测结果lin1 = LinearRegression()lin1.fit(X_train, y_train)# 训练集误差print("训练集误差:", mean_squared_error(y_train, lin1.predict(X_train)))print("测试集误差:", mean_squared_error(y_test, lin1.predict(X_test)))

# 多项式回归模型poly_reg = PolynomiaRegression(2)poly_reg.fit(X_train, y_train)print("训练集误差:", mean_squared_error(y_train, poly_reg.predict(X_train)))print("测试集误差:", mean_squared_error(y_test, poly_reg.predict(X_test)))

# 多项式过拟合模型poly_reg20 = PolynomiaRegression(30)poly_reg20.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), poly_reg20.predict(X)[np.argsort(x)], color='r')
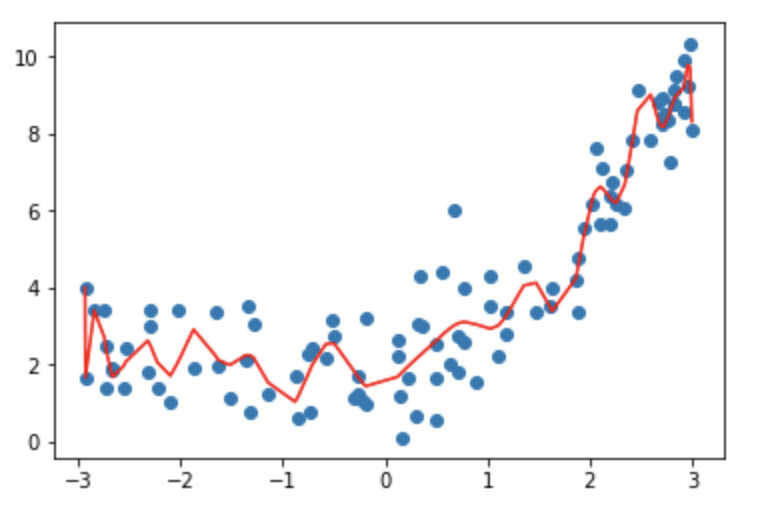
# 过拟合拟合的误差poly_reg30 = PolynomiaRegression(30)poly_reg30.fit(X_train, y_train)print("训练集误差:", mean_squared_error(y_train, poly_reg30.predict(X_train)))print("测试集误差:", mean_squared_error(y_test, poly_reg30.predict(X_test)))

交叉验证-网格搜索
在机器学习中将数据分成,训练集、验证集、测试集,训练集+验证集用来建立模型,测试集来评价模型的好坏,不参与模型的建立。不要训练集+测试集的原因是防止在建立模型的时候对测试数据过拟合。
from sklearn import datasetsfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scoreknn_clf = KNeighborsClassifier()cross_val_score(knn_clf, X_digit_train, y_digit_train,cv=5)

from sklearn.model_selection import GridSearchCVparam_grid = [{'weights': ['distance'],'n_neighbors': [i for i in range(1, 11)],'p': [i for i in range(1, 5)],},]grid = GridSearchCV(KNeighborsClassifier(), param_grid, n_jobs=4, cv=5)grid.fit(X_digit_train, y_digit_train)#最佳参数grid.best_params_best_knn = grid.best_estimator_best_knn.fit(X_digit_train, y_digit_train)best_knn.score(X_digit_test, y_digit_test)
正则化-L1-L2
正则化的目的主要是解决模型的过拟合问题,现在参数的大小。
L1:可以对特征进行选择,L2:将参数尽可能的减小,不会去掉特征。
L2

from sklearn.linear_model import Ridgedef RidgeRegression(degree, alpha):return Pipeline([('poly', PolynomialFeatures(degree=degree)),('std', StandardScaler()),('ridge', Ridge(alpha=alpha))])# 多项式过拟合模型-将alpha=0不加入正则项ridge = RidgeRegression(degree=50, alpha=0)ridge.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), ridge.predict(X)[np.argsort(x)], color='r')

ridge = RidgeRegression(degree=50, alpha=0.1)ridge.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), ridge.predict(X)[np.argsort(x)], color='r')

ridge = RidgeRegression(degree=50, alpha=10)ridge.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), ridge.predict(X)[np.argsort(x)], color='r')

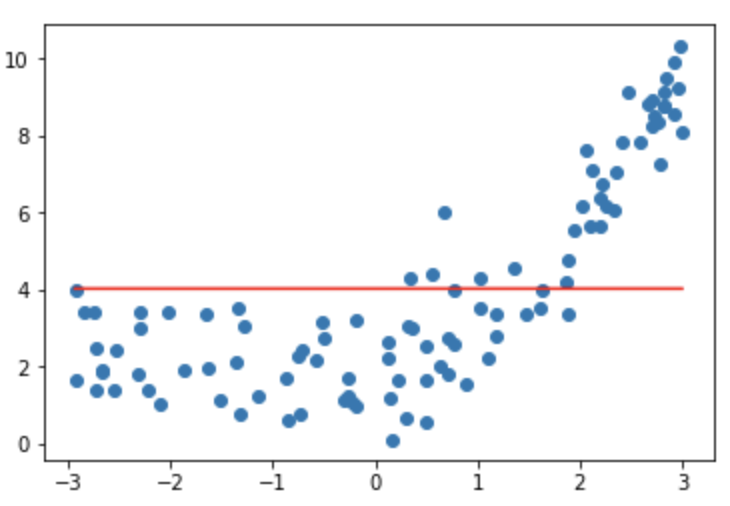
# 当alpha过大时参数都是0误差最小ridge = RidgeRegression(degree=50, alpha=1000000000)ridge.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), ridge.predict(X)[np.argsort(x)], color='r')
L1

from sklearn.linear_model import Lassodef LassoRegression(degree, alpha):return Pipeline([('poly', PolynomialFeatures(degree=degree)),('std', StandardScaler()),('lasso', Lasso(alpha=alpha))])lasso = LassoRegression(degree=50, alpha=0.01)lasso.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), lasso.predict(X)[np.argsort(x)], color='r')

lasso = LassoRegression(degree=50, alpha=0.1)lasso.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), lasso.predict(X)[np.argsort(x)], color='r')

lasso = LassoRegression(degree=50, alpha=10)lasso.fit(X, y)plt.scatter(x, y)plt.plot(np.sort(x), lasso.predict(X)[np.argsort(x)], color='r')


若有收获,就点个赞吧
0 人点赞
