导包和测试数据
import numpy as npfrom sklearn.neighbors import KNeighborsClassifierfrom matplotlib import pyplot as plt# 测试数据raw_data_X = [[3.393533211, 2.331273381],[3.110073483, 1.781539638],[1.343808831, 3.368360954],[3.582294042, 4.679179110],[2.280362439, 2.866990263],[7.423436942, 4.696522875],[5.745051997, 3.533989803],[9.172168622, 2.511101045],[7.792783481, 3.424088941],[7.939820817, 0.791637231]]raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]# 转换成数组X_train = np.array(raw_data_X)y_train = np.array(raw_data_y)
画图
# 画散点图plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1])plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1])

预测一个数据
# 预测随机点xX=np.array([8.093607318, 3.365731514])# 画图plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1])plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1])plt.scatter(x[0], x[1])
画图
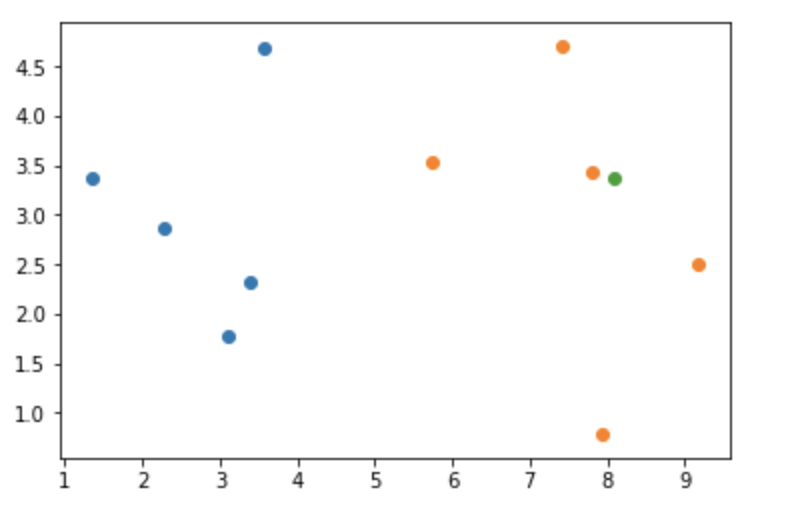
算法过程
# 计算点与所有样本的距离---欧式距离distance = np.sqrt(np.sum((X_train - X) ** 2, axis=1))# 取K值等于6k = 6# 取前6个类别top_k = y_train[distancde_index[:k]]# 统计from collections import Countercount = Counter(top_k)# 预测结果y_prect = count.most_common(1)[0][0]
scikit-learn中的KNN
knn = KNeighborsClassifier(n_neighbors=6)knn.fit(X_train, y_train)knn.predict([X])
实现KNN算法
# 实现KNN算法class KNNClassifier:def __init__(self, k):self.__k = kself.__X_train = Noneself.__y_train = Nonedef fit(self, X_train, y_train):assert 1<= self.__k <= X_train.shape[0]assert X_train.shape[0] == y_train.shape[0]self.__X_train = X_trainself.__y_train = y_trainreturn selfdef predict(self, X_predict):assert self.__X_train.shape[1] == X_predict.shape[1]predicr_res = []for X_predict in X_predict:distance = np.sqrt(np.sum((self.__X_train - X_predict) ** 2, axis=1))distance_index = np.argsort(distance)top_k = Counter(self.__y_train[:self.__k])predict_one = count.most_common(1)[0][0]predicr_res.append(predict_one)return predicr_res
测试
my_knn = KNNClassifier(k=6)my_knn.fit(X_train, y_train)my_knn.predict(np.array([X]))
为什么要有训练集和测试集
答:训练集的数据用来通过算法训练模型,模型的好坏通过没有训练过的数据集来验证,训练集的数据是特征+结果的形式,如果是只有特征没有结果的数据进行预测你并不知道模型是好还是坏。
手动实现测试集和训练集
from sklearn import datasetsiris = datasets.load_iris()y = iris.targetX = iris.data# 为了方便画图取鸢尾花的两个维度new_X = X[:, 2:]new_X.shape# 将原始数据打乱shuffie_index = np.random.permutation(new_X.shape[0])test_ratio = 0.2test_size = int(new_X.shape[0] * test_ratio)test_index = shuffie_index[:test_size]train_index = shuffie_index[test_size:]X_train = new_X[train_index]X_test = new_X[test_index]y_train = y[train_index]y_test = y[test_index]

若有收获,就点个赞吧
0 人点赞
