你可以自己本机安装 redis 或者通过 redis 官网提供的在线 redis 环境。
string
string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(simple dynamic string,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不仅可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
String的数据结构(底层)
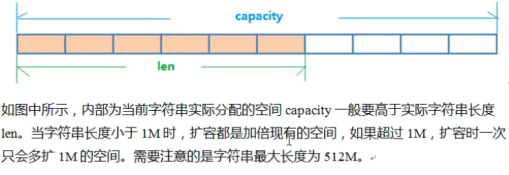
- 常用命令: set,get,strlen,exists,decr,incr,setex 等等。
- 应用场景 :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。 ```bash 127.0.0.1:6379> set key value #设置 key-value 类型的值 OK 127.0.0.1:6379> get key # 根据 key 获得对应的 value “value” 127.0.0.1:6379> exists key # 判断某个 key 是否存在 (integer) 1 127.0.0.1:6379> strlen key # 返回 key 所储存的字符串值的长度。 (integer) 5 127.0.0.1:6379> del key # 删除某个 key 对应的值 (integer) 1 127.0.0.1:6379> get key (nil)
批量设置
127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值 OK 127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value 1) “value1” 2) “value2”
计数器
127.0.0.1:6379> set number 1 OK 127.0.0.1:6379> incr number # 将 key 中储存的数字值增一 (integer) 2 127.0.0.1:6379> get number “2” 127.0.0.1:6379> decr number # 将 key 中储存的数字值减一 (integer) 1 127.0.0.1:6379> get number “1”
<a name="FWLLU"></a># list**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。1. **常用命令:** rpush,lpop,lpush,rpop,lrange、llen 等。1. **应用场景:** 发布与订阅或者说消息队列、慢查询。**通过 rpush/lpop 实现队列:**```bash127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素(integer) 1127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素(integer) 3127.0.0.1:6379> lpop myList # 将 list的尾部(最左边)元素取出"value1"127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end1) "value2"2) "value3"127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一1) "value2"2) "value3"
通过 rpush/rpop 实现栈:
127.0.0.1:6379> rpush myList2 value1 value2 value3
(integer) 3
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
"value3"

hash
hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
Redis为了高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个hash 结构,然后在后续的定时任务中以及 hash 的子指令中,循序渐进地将旧 hash 的内容
一点点迁移到新的 hash 结构中。
hash 也有缺点,hash 结构的存储消耗要高于单个字符串
- 常用命令: hset,hmset,hexists,hget,hgetall,hkeys,hvals 等。
应用场景: 系统中对象数据的存储。
127.0.0.1:6379> hmset userInfoKey name "guide" description "dev" age "24" OK 127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。 (integer) 1 127.0.0.1:6379> hget userInfoKey name # 获取存储在哈希表中指定字段的值。 "guide" 127.0.0.1:6379> hget userInfoKey age "24" 127.0.0.1:6379> hgetall userInfoKey # 获取在哈希表中指定 key 的所有字段和值 1) "name" 2) "guide" 3) "description" 4) "dev" 5) "age" 6) "24" 127.0.0.1:6379> hkeys userInfoKey # 获取 key 列表 1) "name" 2) "description" 3) "age" 127.0.0.1:6379> hvals userInfoKey # 获取 value 列表 1) "guide" 2) "dev" 3) "24" 127.0.0.1:6379> hset userInfoKey name "GuideGeGe" # 修改某个字段对应的值 127.0.0.1:6379> hget userInfoKey name "GuideGeGe"set
set 类似于 Java 中的 HashSet 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
常用命令: sadd,spop,smembers,sismember,scard,sinterstore,sunion 等。
- 应用场景: 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
(integer) 2
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
(integer) 0
127.0.0.1:6379> smembers mySet # 查看 set 中所有的元素
1) "value1"
2) "value2"
127.0.0.1:6379> scard mySet # 查看 set 的长度
(integer) 2
127.0.0.1:6379> sismember mySet value1 # 检查某个元素是否存在set 中,只能接收单个元素
(integer) 1
127.0.0.1:6379> sadd mySet2 value2 value3
(integer) 2
127.0.0.1:6379> sinterstore mySet3 mySet mySet2 # 获取 mySet 和 mySet2 的交集并存放在 mySet3 中
(integer) 1
127.0.0.1:6379> smembers mySet3
1) "value2"
sorted set
和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
zset 内部的排序功能是通过「跳跃列表」数据结构来实现的
- 常用命令: zadd,zcard,zscore,zrange,zrevrange,zrem 等。
- 应用场景: 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
数据结构127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重 (integer) 1 127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素 (integer) 2 127.0.0.1:6379> zcard myZset # 查看 sorted set 中的元素数量 (integer) 3 127.0.0.1:6379> zscore myZset value1 # 查看某个 value 的权重 "3" 127.0.0.1:6379> zrange myZset 0 -1 # 顺序输出某个范围区间的元素,0 -1 表示输出所有元素 1) "value3" 2) "value2" 3) "value1" 127.0.0.1:6379> zrange myZset 0 1 # 顺序输出某个范围区间的元素,0 为 start 1 为 stop 1) "value3" 2) "value2" 127.0.0.1:6379> zrevrange myZset 0 1 # 逆序输出某个范围区间的元素,0 为 start 1 为 stop 1) "value1" 2) "value2"
容器型数据结构的通用规则
list/set/hash/zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则:
1 、create if not exists 如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的,Redis 就会自动创建一个,然后再 rpush 进去新元素。
2 、drop if no elements 如果容器里元素没有了,那么立即删除元素,释放内存。这意味着 lpop 操作到最后一
个元素,列表就消失了。

若有收获,就点个赞吧
0 人点赞
