网站建设初期,页面数量有限,团队人数有限,网站各类页面元素变动不大。但到了网站建设中期,网站需求方需求变多,网站更改相比于之前更加频繁,XX部门提的XX需求可能会影响SEO流量,若未及时发现,时间拉长,可能造成较为严重,甚至不可逆转的后果。这个锅,谁来背呢?
这点可以通过完善需求上线流程来解决一部分,比如:任何涉及页面变动的需求(新增页面 & 已有页面元素更改)在提交RD前,需求评审阶段均需要SEO部门介入,确认该需求对SEO渠道的用户拉新无影响后,在正式提交RD。
尴尬的是,有相当比例的公司,SEO因为历史效果种种不可控,或者 SEO并非用户拉新的主要渠道,SEO较难搞定在PM和RD面前话语权的问题,他们可能不怎么care,老忘记评审的时候叫上SEO一起玩耍。这种情况需要具有八卦特征的SEO,没事跟RD、PM扯扯皮,问问最近上了什么新需求…
但是,即便在流程上能够搞定,也是会出现页面元素的改动,却未及时通知到SEO的情况,比如新入职的产品提需求,不知道有这个流程。
此外,由于SEO部门人事变动,出现老员工离职、新员工入职的情况。新入职的SEO不能快速了解网站历史背景,老员工与新员工交接,很多细节会遗漏,导致新入职的SEO,日后会踩到本可避免的一些坑。
一些基层SEO针对爬虫日志,也没有足够的分析能力,或者需要每天手动拿软件或shell等分析一次数据,然后在执行的SEO动作,操作复杂且效率低下。
为解决以上两点问题,需要有一套“及时止损机制”,用于及时发现潜在风险,并提高日常SEO效率。
“及时止损机制”,需要人工设定N个会影响SEO的特征,程序24小时监控这些特征,如出现符合特征的元素,则及时通知SEO,并提示相应建议,程序每次检查都做一次数据备份。并根据网站发展情况,不断添加、删除监控特征。
我把“及时止损机制”分为两部分:“爬虫日志监控”和“页面特征监控”
爬虫日志监控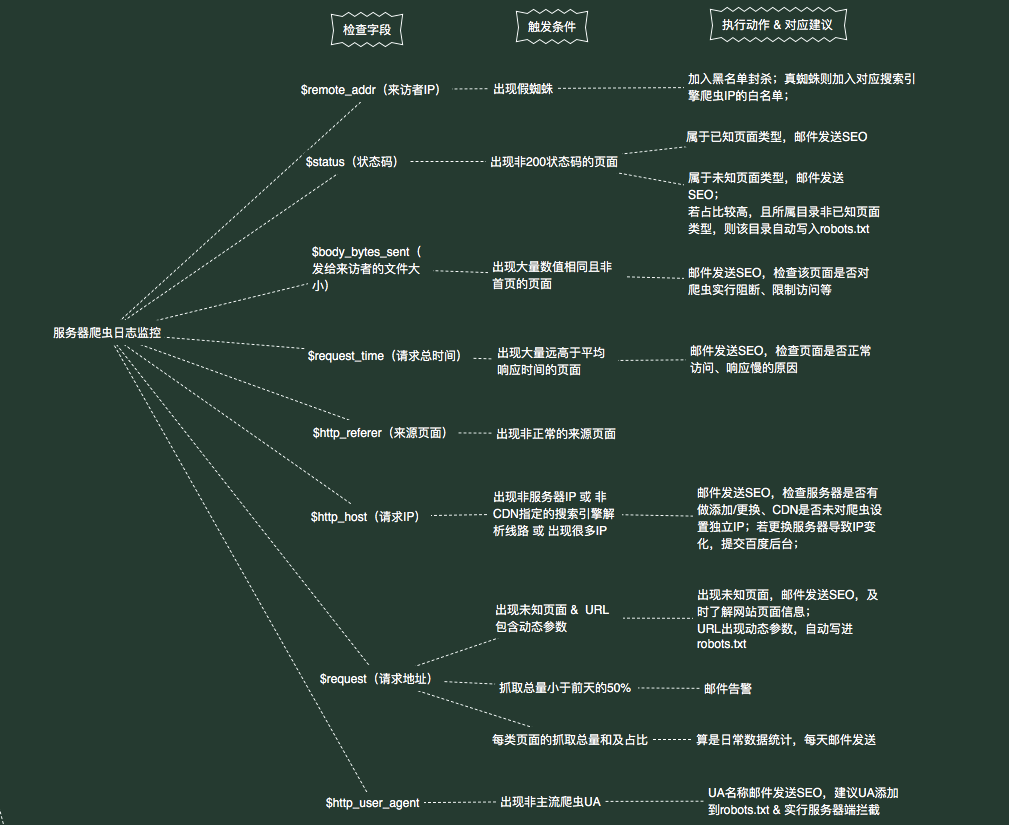
上图为“爬虫日志监控模块”的逻辑,分“检查字段”、“触发条件”、“执行动作”三个步骤。以下是几点可能需要说明的:
- 爬虫IP的黑白名单
根据UA为baiduspider的爬虫,检测IP是否为真实的Baiduspider,若为假spider,则加入黑名单,若为真spider,则加入baiduspider的白名单。
其他主流搜索引擎,则将出现的ip统统加到对应的白名单,后期根据ip段进行排除。
收集白名单IP,可作为日后SEO之用,比如某个SEO的小需求产品不让上,SEO退而求其次,只针对白名单的IP显示该元素,对正常用户访问不显示等。 - 提前整理站内已知页面
提前统计站内所有URL类型,并整理对应URL类型的正则表达式,这些正则均是统计站内已知页面的爬虫情况。
因为大部分SEO包括产品经理,可能都不清除站内到底有多少套URL,所以也有必要通过日志,找到未知的URL,并进行相应的SEO动作。 - 返回内容大小字段统计
为啥要统计“$body_bytes_sent(发给来访者的文件大小)”这个字段呢?
因为之前经历过几次类似情况:某类页面流量逐减少,经排查爬虫日志,360Spider访问部分该页面,返回的文件大小为54k,并不是该页面html文件的正常大小,询问技术,发现不久上线的新反爬虫策略,未把360Spider加入白名单,导致触发反爬虫策略,返回空白页面。
页面特征监控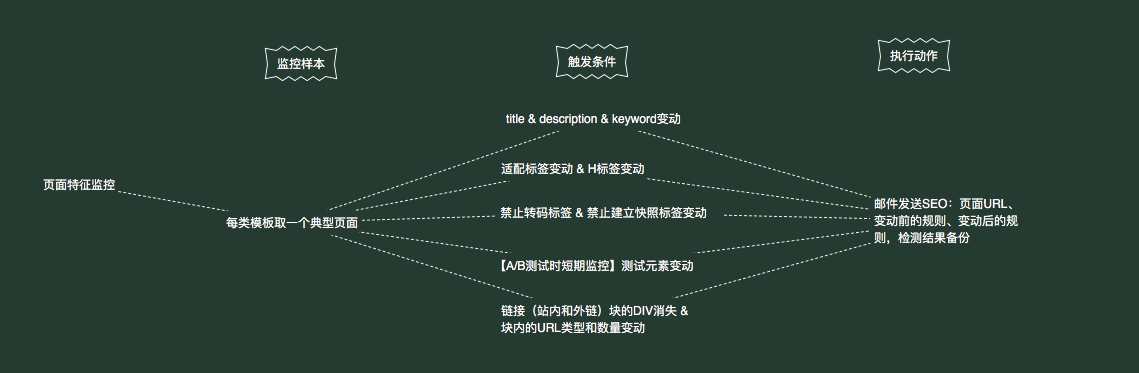
针对模板监控页面,是因为网站可能存在一套URL有N套模板的情况,其他需求方可能只更改了其中一个模板。

若有收获,就点个赞吧
0 人点赞
