书籍信息
书名:走进搜索引擎
作者:梁斌
简介:《走进搜索引擎》是2007年初版的一本书,对于专注于搜索引擎领域的工程师来说,段位太低,因为前5章都是在科普,第6章才切入算法程序这些领域,所以在豆瓣的评分并不高。
核心内容
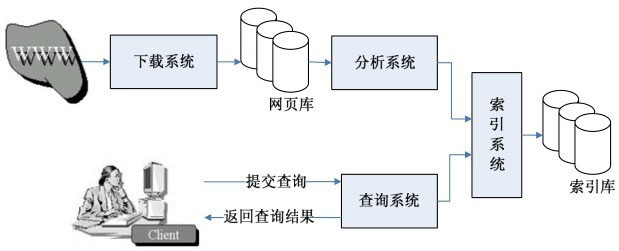
对于SEOer来说,前5章的科普,是最适合的入门搜索引擎原理的内容。全书按照搜索引擎的四大系统展开,分别是:
1 下载系统,负责从互联网上抓取各种类型的网页,并保持更新同步。
2 分析系统,抽取下载的网页数据,进行PageRank和分词计算。
3 索引系统,将分析后的网页对象索引入库。
4 查询系统,负责分析用户提交的查询请求,然后从索引库中检索出相关网页并排序后,以查询结果形式返回给用户。
搜索引擎与其说是一个查询系统,不如说是一个用户定义的信息聚合系统。
而搜索引擎要解决的问题主要是给出快速、全面、准确、可靠的搜索结果,而作为网页来说,能帮助搜索引擎实现以上目标,自然就更容易获得搜索引擎的青睐。
具体来看,快速、全面主要是搜索引擎自身的抓取、索引效率问题,那么面对庞大的数据量,搜索引擎的爬虫资源必然是不够用的,那么主动给各大搜索引擎提交数据,就变成了一个好的解决方案,所以各种站长工具都提供了便捷的链接提交入口,比如sitemap、主动推送、自动推送、手动提交、ping方式等等。
而准确的要求,主要是对网页相关性的考量,数千万个网页,究竟选择哪10条作为搜索引擎的首页展现结果,其实主要是处于对相关性的考量,比如PageRank算法、TF-IDF算法都是主要解决这一问题,后续会详细说一下这两个算法的原理。
至于可靠性,在百度的搜索结果中,表现非常明显,那就是大站优先、百度系自有产品优先,为什么?因为大站的背书,大部分是企业,流量和品牌的双重保障下,更值得信赖。当然这不绝对代表小站失去机会,记住,相关性是最重要的。
下面就按照上面提到的下载、分析、索引、查询四大系统,来展开:
1 下载系统
其实就是爬虫的策略问题,互联网上数据如此庞大,爬虫资源如此有限,先抓哪些网页值得考量,那就需要对网页的重要度有个排序。
而重要性的度量,由链接欢迎度、链接重要度和平均链接深度这3个方面决定。
什么是链接欢迎度?其实就是外链,每一条外链代表了网页的一个投票,更多票选你,你就是受欢迎的,这也是早期SEO策略一度外链猖獗的原因之一。
链接重要度,是关于URL本身的一个函数,比如包含“.com”和“较少斜杠”的URL重要程度高。这也是我们为什么做网站要尽可能选择常见域名和减少URL长度的原因。
平均链接深度,其实说的是当前链接距离爬虫开始抓取的种子链接的点击距离。这个点击距离越近,说明你的重要性越高,这也是我们一直在大型网站中强调的,要减少每个页面距离首页的点击距离,其实就是为了提高重要性,从而增加被抓取的概率。
所以,通过以上原理的理解,我们就能制定出合理的SEO策略,比如:用常见域名、减少URL长度、做更多的外链、减少点击距离等等。
2 分析系统
分析系统主要完成信息抽取、网页去重、中文分词和PageRank计算等任务。
对于分析系统来说,基础和首要的工作,就是从网页中识别抽取出代表网页的属性,比如锚文本、标题、正文、链接模块、图片模块等等。而如果你采用了爬虫不太友好的技术架构,比如flash、frame、ajax等等,就会影响这一步的结果,从而被爬虫丢弃。当然,反之,以上不太友好的架构,往往是作弊和黑帽SEO的温床。
而网页去重过程,为了效率考虑,一般会遵循,谁先被爬虫发现,谁就是原创的原则,所以很多大站因为在抓取过程中更有优势,往往在网页去重的过程中占据优势。这一点,跟我们目前自媒体的原创逻辑,还是不一样的,需要注意。
最后一步PageRank计算,其实为了最终网页排序做准备,所以也是一种衡量网页重要性的工具。
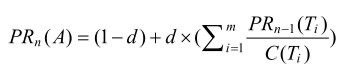
说明如下:
(1)PRn(A):网页A的PageRank值。
(2)PRn-1(Ti):网页 Ti存在指向A的链接,并且网页 Ti在上一次迭代时的PageRank值。
(3)C(Ti):网页Ti的外链数量。
(4)d:阻尼系数,0
3 索引系统
索引的简单理解,就相当于一本书的目录。
而搜索引擎存在正排索引和倒排索引两类。所谓正排索引就是以唯一性的文档编号去映射对应搜索词,而倒排索引就是以搜索词去映射对应的一组文档。
所以,搜索引擎的索引库是分层级,只有进入更高级的索引库,才有机会在搜索结果中展现。
由此,衍生出索引和收录的区别:
搜狗站长平台给出这样的解释:搜狗对网站的收录量为搜狗爬虫对网站内页面的总成功抓取量。索引量为被收录的页面经过索引流程进入线上后的总网页数量。由此可见,索引是高于收录的。
4 查询系统
严格意义上,普通用户提交给查询系统的关键词称为“查询词”;经过查询系统分词,提交检索代理的称为“检索词”。
一般来说,查询的流程如下:
(1)对查询词进行分词,得到一个逻辑表达式。例如查询「走进搜索引擎」,将会被切分成「走进」,「搜索引擎」这两个词。并且转换为用AND逻辑表示的表达式,即「走进」AND「搜索引擎」。
(2)采用布尔模型的方法得到结果文档列表,例如从倒排索引中提取包含「走进」关键词的文档列表和包含「搜索引擎」关键词的文档列表。并将检索出的文档列表求交集,得到既包含「走进」,也包含「搜索引擎」的文档列表。
(3)将步骤(2)得到的文档列表中的全部文档和查询词分别向量化,并求向量间的相似度。
(4)按照相似度排序输出检索结果。
以上提到的相似度问题,就涉及到搜索引擎中最重要的算法之一:TF-IDF算法。
TF = 关键词出现次数 / 文档总字数
IDF = log( 搜索引擎文档总数 / 出现某个词的文档总数 )
TF-IDF值 = TF * IDF
举个例子:以「SEO学习方法」为例,中文分词为「SEO」「学习方法」
假设百度文档总数为10亿
SEO收录数为7730万
学习方法收录数为1亿
可以看出SEO的IDF值更高,属于权重高的关键词词项,其重要性优先于学习方法
而搜索「SEO学习方法」
排名第一的页面,SEO词频=0.06
排名第二的页面,SEO词频=0.02
可以大概验证出,TF-IDF算法的价值。
而百度专利中提到,百度会分开计算页面中不同模块的TF-IDF,所以相关推荐的关键词词频,就会尤为重要。
此外title,description,正文内容这些能反映关键词词频的位置,都有很大价值。
很明显,TF-IDF存在明显漏洞,只要堆砌IDF值高的词,就能大大提升相关性,从而提升网站排名,这也是早期搜索引擎中存在大量堆砌关键词这种作弊手段的根源。
现在,随着搜索引擎的升级,单纯堆砌关键词会招致惩罚,但是因为底层算法的原因,只要不超过红线,堆砌关键词依旧是非常有效的手段。
所以,SEO玩的就是细节,对算法理解越深,可以探索的细节就是越多,这也是为什么SEO的高手喜欢研究百度、Google这些搜索引擎专利的原因。通过专利可以看清搜索引擎的底层原理,由此探索出规则的底线,在规则上跳舞,也是符合增长黑客精神的一种做法。
参考内容:
重读《走进搜索引擎》

若有收获,就点个赞吧
0 人点赞
