虚拟内存
每个进程都拥有独立的、连续的、统一的虚拟地址空间,通过MMU和物理内存映射,高效使用物理内存
Linux进程内存
现在主要讨论的64位的内存分布,目前用了48位的寻址空间,总的虚拟地址空间 为256TB,用户空间为128T, 用户空间布局和32位linux布局一样
堆内存管理
堆内存最初会是一个完整的大块,即未分配任何内存。当发现内存申请的时候,堆内存就会从未分配内存分割出一个小内存块(block),然后用链表把所有内存块连接起来。需要一些信息描述每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在data中。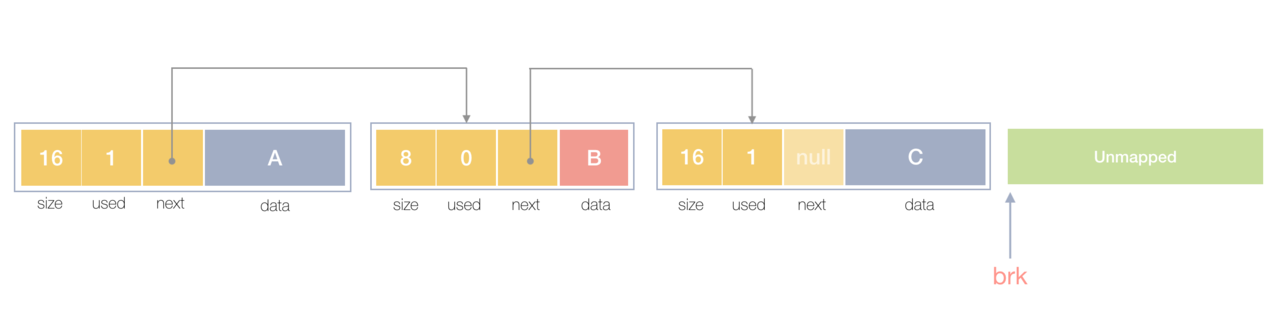
一个内存块包含了3类信息,如下图所示,元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请5Byte内存的时候,就需要进行内存对齐。
释放内存实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中优先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
内存分配器
Ptmalloc
支持多线程,Glib2.3 之后成为Linux默认内存分配器
Tcmalloc
谷歌开发的,小对象使用中心堆-线程堆模型,无需加锁,线程私有缓存,对象按大小分class,不同大小对象使用 不同class的span分配,减少碎片,加 快分配速度。
虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。
TCMalloc的做法是什么呢?为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有2个好处:
- 为线程预分配缓存需要进行1次系统调用,后续线程申请小内存时直接从缓存分配,都是在用户态执行的,没有了系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
内存管理单元
Go在程序启动的时候,会先向操作系统申请一块虚拟内存,申请到的内存块被分配了三个区域,在64位上分别是512MB,16GB,512GB大小。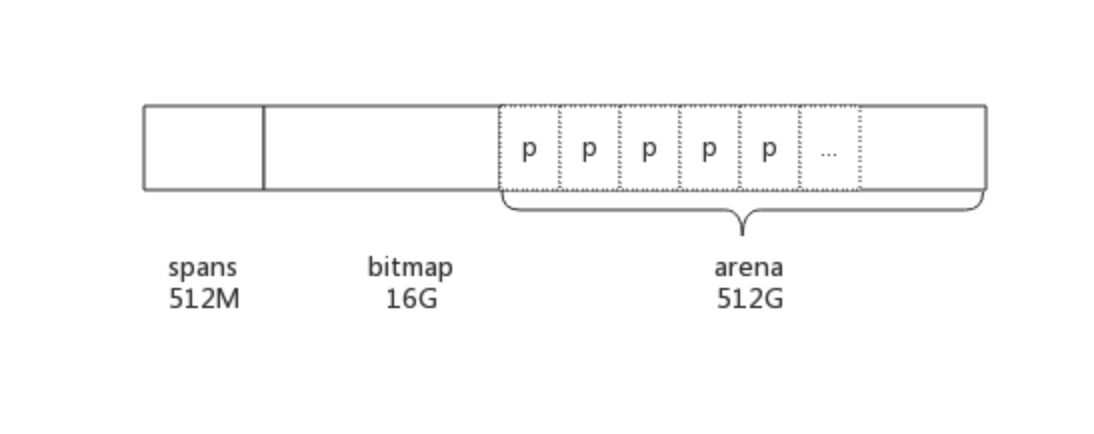
图片来源https://rainbowmango.gitbook.io/go/chapter04/4.1-memory_alloc
arena
Go动态分配的内存都是在这个区域,可以认识这就是我们一直提到的堆区,arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个页,一些页组合起来称为mspan。
span
sizeclass
根据对象大小,划分了一系列class,每个class都代表一个固定大小的对象,以及每个span的大小。如下表所示:
// class bytes/obj bytes/span objects waste bytes// 1 8 8192 1024 0// 2 16 8192 512 0// 3 32 8192 256 0// 4 48 8192 170 32// 5 64 8192 128 0// 6 80 8192 102 32// 7 96 8192 85 32// 8 112 8192 73 16// 9 128 8192 64 0// 10 144 8192 56 128// 11 160 8192 51 32// 12 176 8192 46 96// 13 192 8192 42 128// 14 208 8192 39 80// 15 224 8192 36 128// 16 240 8192 34 32// 17 256 8192 32 0// 18 288 8192 28 128// 19 320 8192 25 192// 20 352 8192 23 96// 21 384 8192 21 128// 22 416 8192 19 288// 23 448 8192 18 128// 24 480 8192 17 32// 25 512 8192 16 0// 26 576 8192 14 128// 27 640 8192 12 512// 28 704 8192 11 448// 29 768 8192 10 512// 30 896 8192 9 128// 31 1024 8192 8 0// 32 1152 8192 7 128// 33 1280 8192 6 512// 34 1408 16384 11 896// 35 1536 8192 5 512// 36 1792 16384 9 256// 37 2048 8192 4 0// 38 2304 16384 7 256// 39 2688 8192 3 128// 40 3072 24576 8 0// 41 3200 16384 5 384// 42 3456 24576 7 384// 43 4096 8192 2 0// 44 4864 24576 5 256// 45 5376 16384 3 256// 46 6144 24576 4 0// 47 6528 32768 5 128// 48 6784 40960 6 256// 49 6912 49152 7 768// 50 8192 8192 1 0// 51 9472 57344 6 512// 52 9728 49152 5 512// 53 10240 40960 4 0// 54 10880 32768 3 128// 55 12288 24576 2 0// 56 13568 40960 3 256// 57 14336 57344 4 0// 58 16384 16384 1 0// 59 18432 73728 4 0// 60 19072 57344 3 128// 61 20480 40960 2 0// 62 21760 65536 3 256// 63 24576 24576 1 0// 64 27264 81920 3 128// 65 28672 57344 2 0// 66 32768 32768 1 0
- class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型
- bytes/obj:该class代表对象的字节数
- bytes/span:每个span占用堆的字节数,也即页数*页大小
- objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)
- waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
上表可见最大的对象是32K大小,超过32K大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。
mspan
mspan是一个包含起始地址、mspan规格、页的数量等内容的双端链表。每个mspan按照它自身的属性Size Class的大小分割成若干个object,每个object可存储一个对象。并且会使用一个位图来标记其尚未使用的object。
https://github.com/golang/go/blob/master/src/runtime/mheap.go
//go:notinheaptype mspan struct {next *mspan // next span in list, or nil if noneprev *mspan // previous span in list, or nil if nonelist *mSpanList // For debugging. TODO: Remove.startAddr uintptr // address of first byte of span aka s.base()npages uintptr // number of pages in spanmanualFreeList gclinkptr // list of free objects in mSpanManual spans// freeindex is the slot index between 0 and nelems at which to begin scanning// for the next free object in this span.// Each allocation scans allocBits starting at freeindex until it encounters a 0// indicating a free object. freeindex is then adjusted so that subsequent scans begin// just past the newly discovered free object.//// If freeindex == nelem, this span has no free objects.//// allocBits is a bitmap of objects in this span.// If n >= freeindex and allocBits[n/8] & (1<<(n%8)) is 0// then object n is free;// otherwise, object n is allocated. Bits starting at nelem are// undefined and should never be referenced.//// Object n starts at address n*elemsize + (start << pageShift).freeindex uintptr// TODO: Look up nelems from sizeclass and remove this field if it// helps performance.nelems uintptr // number of object in the span.// Cache of the allocBits at freeindex. allocCache is shifted// such that the lowest bit corresponds to the bit freeindex.// allocCache holds the complement of allocBits, thus allowing// ctz (count trailing zero) to use it directly.// allocCache may contain bits beyond s.nelems; the caller must ignore// these.allocCache uint64// allocBits and gcmarkBits hold pointers to a span's mark and// allocation bits. The pointers are 8 byte aligned.// There are three arenas where this data is held.// free: Dirty arenas that are no longer accessed// and can be reused.// next: Holds information to be used in the next GC cycle.// current: Information being used during this GC cycle.// previous: Information being used during the last GC cycle.// A new GC cycle starts with the call to finishsweep_m.// finishsweep_m moves the previous arena to the free arena,// the current arena to the previous arena, and// the next arena to the current arena.// The next arena is populated as the spans request// memory to hold gcmarkBits for the next GC cycle as well// as allocBits for newly allocated spans.//// The pointer arithmetic is done "by hand" instead of using// arrays to avoid bounds checks along critical performance// paths.// The sweep will free the old allocBits and set allocBits to the// gcmarkBits. The gcmarkBits are replaced with a fresh zeroed// out memory.allocBits *gcBitsgcmarkBits *gcBits// sweep generation:// if sweepgen == h->sweepgen - 2, the span needs sweeping// if sweepgen == h->sweepgen - 1, the span is currently being swept// if sweepgen == h->sweepgen, the span is swept and ready to use// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached// h->sweepgen is incremented by 2 after every GCsweepgen uint32divMul uint16 // for divide by elemsize - divMagic.mulbaseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation baseallocCount uint16 // number of allocated objectsspanclass spanClass // size class and noscan (uint8)state mSpanStateBox // mSpanInUse etc; accessed atomically (get/set methods)needzero uint8 // needs to be zeroed before allocationdivShift uint8 // for divide by elemsize - divMagic.shiftdivShift2 uint8 // for divide by elemsize - divMagic.shift2elemsize uintptr // computed from sizeclass or from npageslimit uintptr // end of data in spanspeciallock mutex // guards specials listspecials *special // linked list of special records sorted by offset.}type mspan struct {next *mspan //链表后继指针prev *mspan //链表前向指针startAddr uintptr // 起始地址,即所管理页的地址npages uintptr // 管理的页数nelems uintptr // 块个数,表示有多少个块可供分配allocBits *gcBits //分配位图,每一位代表一个块是否已分配allocCount uint16 // 已分配块的个数spanclass spanClass // class表中的class ID,和Size Classs相关elemsize uintptr // class表中的对象大小,也即块大小}
https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go
spans
spans区域存放span的指针,每个指针对应一个page,所以span区域的大小为(512GB/8KB)*8B(指针大小) = 512M
bitmap
bitmap区域大小也是通过arena计算出来,不过主要用于GC。
标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。
Go内存分配器
Go分配器由3种组件构成:mcache, mcentral, mheap。
mcache
mcache:每个工作线程都会绑定一个mcache,本地缓存可用的mspan资源,这样就可以直接给Goroutine分配,因为不存在多个Goroutine竞争的情况,所以不会消耗锁资源。
type mcache struct {alloc [numSpanClasses]*mspan}numSpanClasses = _NumSizeClasses << 1
mcache用Span Classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,也就是67*2=134,为什么有一个两倍的关系,前面我们提到过:为了加速之后内存回收的速度,数组里一半的mspan中分配的对象不包含指针,另一半则包含指针。
对于无指针对象的mspan在进行垃圾回收的时候无需进一步扫描它是否引用了其他活跃的对象。

Go内存分配
内存分配算法:使用TCMalloc算法原理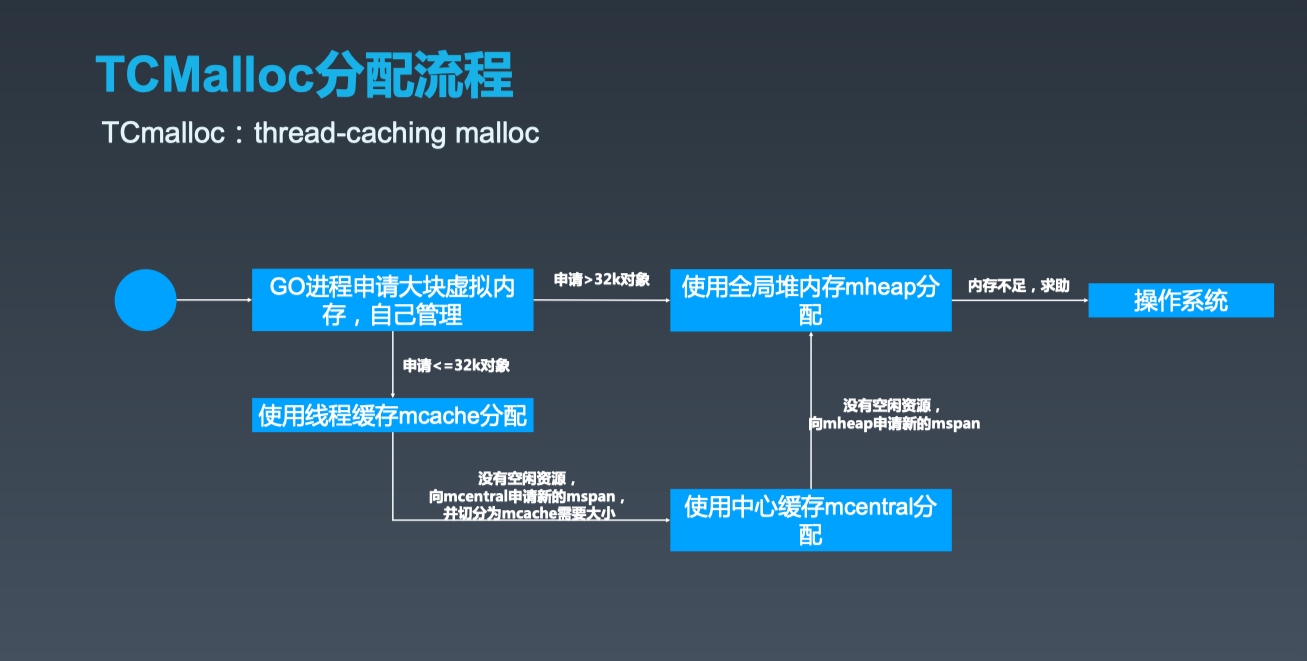
- Golang程序启动时申请一大块内存,并划分成spans、bitmap、arena区域
- arena区域按页划分成一个个小块
- span管理一个或多个页
- mcentral管理多个span供线程申请使用
- mcache作为线程私有资源,资源来源于mcentral
new&make
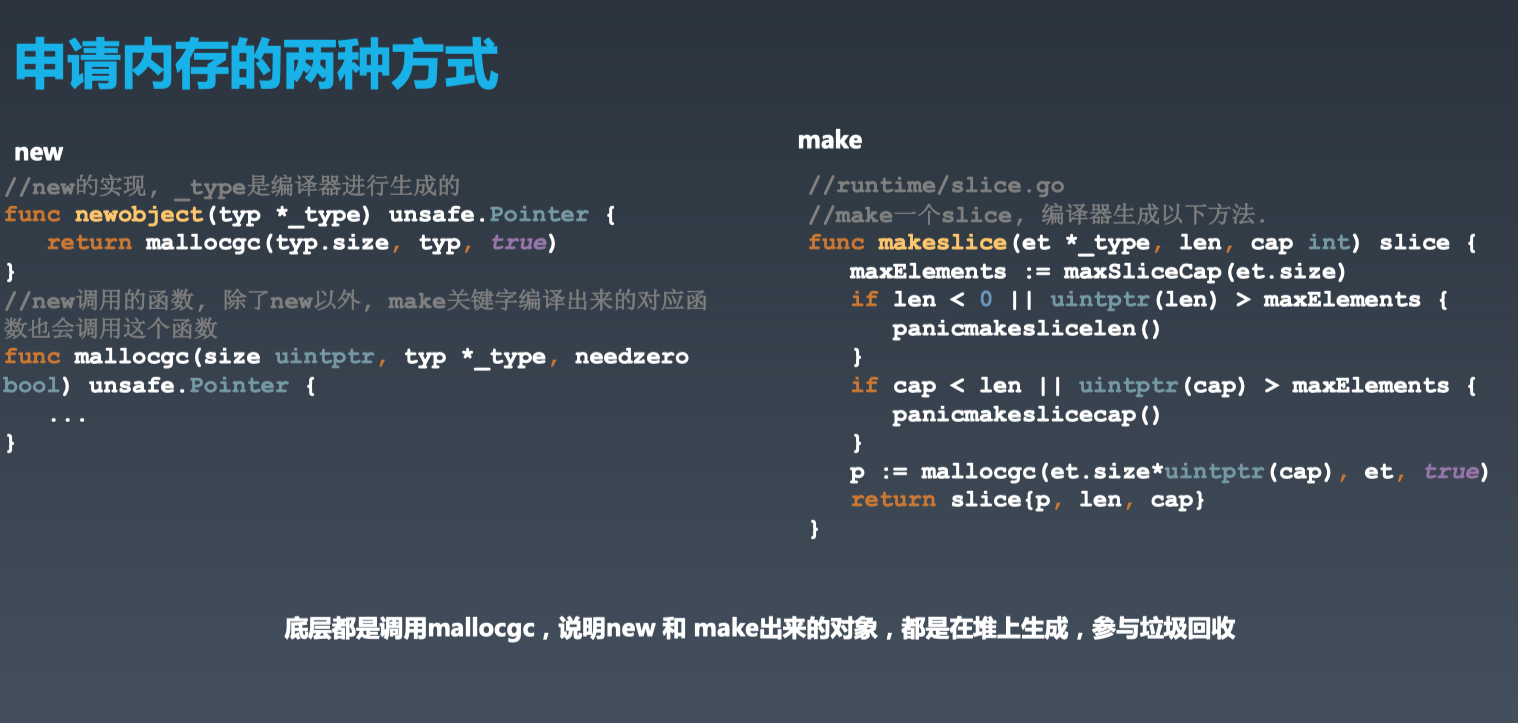
new 返回指针,且值为零等价于:
Make只用来创建slice,map和channel 已初始化、返回为引用T *t = (T*)malloc(sizeof(T)) memset(t, 0, sizeof(T))
内存泄露
预期的能很快被释放的内存由于附着在了长期存活的内存上、或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。
在 Go 中,由于 goroutine 的存在,所谓的内存泄漏除了附着在长期对象上之外,还存在多种不同的形式。
附着根对象
当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放。例如:
var cache = map[interface{}]interface{}{}func keepalloc() {for i := 0; i < 10000; i++ {m := make([]byte, 1<<10)cache[i] = m}}
goroutine 泄漏
Goroutine 作为一种逻辑上理解的轻量级线程,需要维护执行用户代码的上下文信息。在运行过程中也需要消耗一定的内存来保存这类信息,而这些内存在目前版本的 Go 中是不会被释放的。因此,如果一个程序持续不断地产生新的 goroutine、且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象,例如:
func keepalloc2() {for i := 0; i < 100000; i++ {go func() {select {}}()}}
验证
我们可以通过如下形式来调用上述两个函数:
package mainimport ("os""runtime/trace")func main() {f, _ := os.Create("trace.out")defer f.Close()trace.Start(f)defer trace.Stop()keepalloc()keepalloc2()}
运行程序:
go run main.go
会看到程序中生成了 trace.out 文件,我们可以使用 go tool trace trace.out 命令得到下图:

可以看到,途中的 Heap 在持续增长,没有内存被回收,产生了内存泄漏的现象。
值得一提的是,这种形式的 goroutine 泄漏还可能由 channel 泄漏导致。而 channel 的泄漏本质上与 goroutine 泄漏存在直接联系。Channel 作为一种同步原语,会连接两个不同的 goroutine,如果一个 goroutine 尝试向一个没有接收方的无缓冲 channel 发送消息,则该 goroutine 会被永久的休眠,整个 goroutine 及其执行栈都得不到释放,例如:
var ch = make(chan struct{})func keepalloc3() {for i := 0; i < 100000; i++ {// 没有接收方,goroutine 会一直阻塞go func() { ch <- struct{}{} }()}}
参考
https://www.infoq.cn/article/q-ELp4QGJvI1oBVbmhh5
https://www.tuicool.com/articles/e2ENney
https://juejin.im/post/5d47b1f16fb9a06aec2623ff

若有收获,就点个赞吧
0 人点赞
