定义
字符串是用一对双引号”或反引号``(键盘数字1的左边键)括起来定义,
str :="string test"fmt.Println(str)aStr := `another string`fmt.Println(aStr)
注意字符串一旦赋值了,字符串是不可以修改的。
str :="hello"str[0] = 's'
会出现如下错误
cannot assign to str[0]
如果需要修改字符串内容,可以把字符串转换成[]byte类型
package mainimport "fmt"func main() {str :="hello"a :=[]byte(str)a[0] = 's'fmt.Println(str)fmt.Println(string(a))}
打印结果如下
hellosello
字符串转换为切片 []byte(s)要慎用,尤其是当数据量较大时(每转换一次都需复制内容)
<br />字符串的2种表现形式,双引号可以识别转义字符,单引号会按照原生输出。
doubleStr := "adc\nnextLine"fmt.Println(doubleStr)singleSte := `\t adc\n nextLine`fmt.Println(singleSte)
底层结构
符串的底层结构在reflect.StringHeader中定义:
//runtime/string .gotype StringHeader struct {Data uintptrLen int}
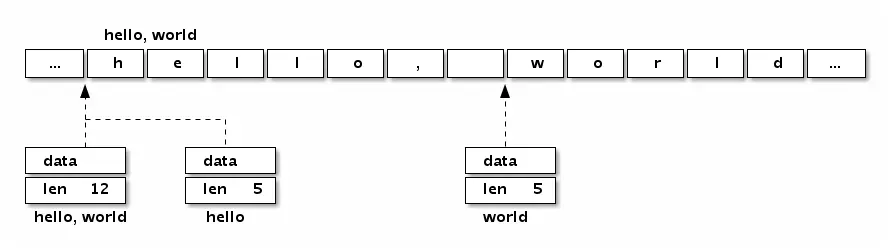
字符串结构由两个信息组成:第一个是字符串指向的底层字节数组,第二个是字符串的字节的长度。字符串其实是一个结构体,因此字符串的赋值操作也就是reflect.StringHeader结构体的复制过程,并不会涉及底层字节数组的复制。在前面数组一节提到的[2]string字符串数组对应的底层结构和[2]reflect.StringHeader对应的底层结构是一样的,可以将字符串数组看作一个结构体数组。
我们可以看看字符串“Hello, world”本身对应的内存结构:
字符串操作
包含
Contains(s, substr string) bool 包含子字符串ContainsAny(s, chars string) bool 任意点码值是否s中出现ContainsRune(s string, r rune) bool r unicode值是否s中出现Count(s, sep string) int sep 子字符串出现的次数EqualFold(s, t string) bool 比较字符串相等忽略大小写HasPrefix(s, prefix string) bool 是否有前缀HasSuffix(s, suffix string) bool 是否有后缀
fmt.Println(strings.Contains("seafood", "foo"))//truefmt.Println(strings.Contains("seafood", "bar"))//falsefmt.Println(strings.Contains("seafood", ""))//truefmt.Println(strings.Contains("", ""))//truefmt.Println(strings.ContainsAny("test",""))//falsefmt.Println(strings.ContainsAny("test","tr"))//truefmt.Println(strings.Count("test", "t"))//2
位置
Index(s, sep string) int 返回第一个sep在s中的位置IndexAny(s, chars string) int 返回chars中unicode码点在s中第一个所在的位置IndexFunc(s string, f func(rune) bool) int 返回s 中unicode码点满足函数f的位置IndexByte(s string, c byte) int 返回第一个c byte在s中出现的位置IndexRune(s string, r rune) int 返回第一个r unicode在s中出现的位置LastIndex(s, sep string) intLastIndexAny(s, chars string)LastIndexFunc(s string, f func(rune)bool)int
过滤
Trim(s string, cutset string) string 从两端过滤包含cutset中码点值TrimFunc(s string, f func(rune) bool)string从两端过滤满足f的码点值TrimLeft(s, string, cutset s string) stringTrimLeftFunc(s string, f func(rune) bool)stringTrimRight(s, string, cutset s string) stringTrimRightFunc(s string, f func(rune) bool)stringTrimSpace(s string) string 从两端过滤空白字符和空格
替换
Map(mapping func(rune) rune, s string) string 根据mapping函数替换里面每个runeNewReplacer(oldnew …string) 创建一个替换器对象Replace(s, old, new string, n int) string 把old 替换为new
大小写
Title(s string) string 对s中每一个单词进行标题首字母大写ToTitle(s string) string 得到s的标题格式ToLower(s string) string 得到小写ToLowerSpeical(case unicode.SpecialCase, s string) string 针对特殊的编码格式小写ToUpper(s string) stringToUpperSpeical(case unicode.SpecialCase, s string) string
分割
Fields(s string) []string 对字符串按空白进行分割FieldsFunc(s string, f func(rune) bool) 对满足f的函数进行切割Split(s, sep string) []string 以sep对字符串s进行分割SplitN(s, sep string, n int)[] string 以sep对字符串s进行分割成几部分SplitAfter(s, sep string) [] stringSplitAfterN(s, sep string, n int)[] stringTrimPrefix(s, prefix string) string 去掉前缀TrimSuffix(s, suffix string) string 去掉后缀
合并
Join(a []string, sep string) string用分割符sep合并aNewReader(s string) *Reader 创建一个字符串对象Repeat(s string, count int) string 新生成一个s重复几次的字符串
转换
字符串转化的函数在strconv中,如下也只是列出一些常用的:
Append 系列函数将整数等转换为字符串后,添加到现有的字节数组中。
package mainimport ("fmt""strconv")func main() {str := make([]byte, 0, 100)str = strconv.AppendInt(str, 4567, 10)str = strconv.AppendBool(str, false)str = strconv.AppendQuote(str, "abcdefg")str = strconv.AppendQuoteRune(str, '单')fmt.Println(string(str))}
Format 系列函数把其他类型的转换为字符串
package mainimport ("fmt""strconv")func main() {a := strconv.FormatBool(false)b := strconv.FormatFloat(123.23, 'g', 12, 64)c := strconv.FormatInt(1234, 10)d := strconv.FormatUint(12345, 10)e := strconv.Itoa(1023)fmt.Println(a, b, c, d, e)}
Parse 系列函数把字符串转换为其他类型
package mainimport ("fmt""strconv")func checkError(e error){if e != nil{fmt.Println(e)}}func main() {a, err := strconv.ParseBool("false")checkError(err)b, err := strconv.ParseFloat("123.23", 64)checkError(err)c, err := strconv.ParseInt("1234", 10, 64)checkError(err)d, err := strconv.ParseUint("12345", 10, 64)checkError(err)e, err := strconv.Atoi("1023")checkError(err)fmt.Println(a, b, c, d, e)}
遍历
range 在字符串中迭代 unicode 编码。第一个返回值是rune 的起始字节位置,然后第二个是 rune 自己。
for index,value := range "123ABCabc"{fmt.Println(index,value)}
rune 类型
Go语言默认的字符编码就是UTF-8类型的 。
Go 内置两种字符类型 :
一种是byte的字节类类型( byte是uint的别名)。
另一种是表示Unicode编码的字符rune. rune在Go内部是int32类型的别名,占用4个字节。
package mainimport "fmt"func main() {str := "Hello你好世界"fmt.Println(len(str))b := []byte(str)for _,v := range b{fmt.Print(string(v))}fmt.Println("")r :=[]rune(str)for _,v := range r{fmt.Print(string(v))}fmt.Println("")r[0]='h'r[5]='您'fmt.Println(string(r))}
打印结果如下
17Helloä½ å¥½ä¸�ç��Hello你好世界hello您好世界
格式化
通用占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %v | 相应值的默认格式。 | Printf(“%v”, people) | {zhangsan}, |
| %+v | 打印结构体时,会添加字段名 | Printf(“%+v”, people) | {Name:zhangsan} |
| %#v | 相应值的Go语法表示 | Printf(“#v”, people) | main.Human{Name:”zhangsan”} |
| %T | 相应值的类型的Go语法表示 | Printf(“%T”, people) | main.Human |
| %% | 字面上的百分号,并非值的占位符 | Printf(“%%”) | % |
| %p | 指针地址,十六进制表示,前缀 0x | Printf(“%p”, &people) | 0x4f57f0 |
字节切片
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %s | 输出字符串表示(string类型或[]byte) | Printf(“%s”, []byte(“Go语言”)) | Go语言 |
| %q | 双引号围绕的字符串,由Go语法安全地转义 | Printf(“%q”, “Go语言”) | “Go语言” |
| %x | 十六进制,小写字母,每字节两个字符 | Printf(“%x”, “golang”) | 676f6c616e67 |
| %X | 十六进制,大写字母,每字节两个字符 | Printf(“%X”, “golang”) | 676F6C616E67 |
数字
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %b | 二进制表示 | Printf(“%b”, 5) | 101 |
| %c | 相应Unicode码点所表示的字符 | Printf(“%c”, 0x4E2D) | 中 |
| %d | 十进制表示 | Printf(“%d”, 0x12) | 18 |
| %o | 八进制表示 | Printf(“%d”, 10) | 12 |
| %q | 单引号围绕的字符字面值,由Go语法安全地转义 | Printf(“%q”, 0x4E2D) | ‘中’ |
| %x | 十六进制表示,字母形式为小写 a-f | Printf(“%x”, 13) | d |
| %X | 十六进制表示,字母形式为大写 A-F | Printf(“%x”, 13) | D |
| %U | Unicode格式:U+1234,等同于 “U+%04X” | Printf(“%U”, 0x4E2D) | U+4E2D%b 无小数部分的,指数为二的幂的科学计数法,与 strconv.FormatFloat 的 ‘b’ 转换格式一致。例如 -123456p-78 |
| %e | 科学计数法,例如 -1234.456e+78 | Printf(“%e”, 10.2) | 1.020000e+01 |
| %E | 科学计数法,例如 -1234.456E+78 | Printf(“%e”, 10.2) | 1.020000E+01 |
| %f | 有小数点而无指数,例如 123.456 | Printf(“%f”, 10.2) | 10.200000 |
| %g | 根据情况选择 %e 或 %f 以产生更紧凑的(无末尾的0)输出 | Printf(“%g”, 10.20) | 10.2 |
| %G | 根据情况选择 %E 或 %f 以产生更紧凑的(无末尾的0)输出 | Printf(“%G”, 10.20+2i) ( | 10.2+2i) |

若有收获,就点个赞吧
0 人点赞
