第14章 文件系统
设备专有文件
- 字符型设备:基于字符处理数据,如终端和键盘
- 块设备:每次处理一块数据,一般都是512字节,如磁带和磁盘
通常位于/dev下,超级用户可以使用mknod命令创建设备文件,特权程序可通过mknod()系统调用实现相同功能,udev程序所依赖的sysfs文件系统,是装载于/sys下的伪文件系统,将设备和其他内核对象的相关信息导出到用户空间
每个设备都有主、辅ID号,主ID标识一般的设备等级,内核会根据主ID查找对应的驱动程序,辅ID能够在同一等级中标识唯一特定设备,命令ls -l可显示出设备文件的主辅ID,每个设备的驱动程序都会将自己与特定主设备号的关联关系向内核注册,以此建立设备专用文件和设备驱动程序之间的关系,内核是不会使用设备文件名查找驱动程序的
磁盘和分区
磁盘驱动器是一种机械装置,由一个或多个高速旋转的盘片组成,通过在磁盘上快速移动读写磁头,可获取/修改磁盘表面的磁性编码信息,磁盘表面信息物理上存储于磁道的一组同心圆上,其又被划分为若干扇区,每个扇区包括一系列物理块,物理块的容量一般是512字节,代表驱动器可以读写的最小信息单元。首先磁头要移动到相应的磁道(寻道时间),然后再相应扇区旋转到磁头下之前,驱动器必须一直等待(旋转延迟),最后还要从所请求的块上传输数据(传输时间),上述操作通常以毫秒计数
每个磁盘可划分为多个分区,内核视每个分区为/dev下的单独设备,系统管理员使用fdisk决定磁盘分区的编号、大小和类型,fdisk -l会列出磁盘上所有分区,Linux专有文件/proc/partitions记录了系统中每个磁盘分区的主副设备编号、大小和名称,磁盘分区可容纳任何类型的信息,通常只包含以下之一:
- 文件系统:用来存放常规文件
- 数据区域:作为裸设备对其进行访问
- 交换区域:供内核的内存管理使用
mkswap命令可创建交换区域,特权进程可用swapon系统调用向内核报告将磁盘分区用作交换区域,swapoff系统调用执行相反功能,即告知内核停止将磁盘分区作为交换区域,可使用Linux专有文件/proc/swaps查看系统中当前以及激活的交换区域的信息
文件系统
文件系统时对常规文件和目录的组织集合,创建文件系统的命令式mkfs,Linux支持种类繁多的文件系统
- 传统的ext2文件系统
- 原生UNIX文件系统,如Minix、System V、BSD
- 微软的FAT、FAT32、NTFS
- ISO CD-ROM文件系统
- Apple Macintosh的HFS
- 一系列日志文件系统,如ext3、ext4、Reiserfs、JFS、XFS、Btrfs
Linux专有的文件/proc/filesystems可以查看当前内核所识别的文件系统类型
ext2随着日志文件系统的兴起,使用日趋减少,但其概念较为通用,文件系统的组成部分:
- 引导块:总是作为文件系统的首块,不为文件系统使用,只是包含用来引导操作系统的信息
- 超级块:紧随引导块的一个独立块,包含与文件系统有关的参数信息,如i节点容量、文件系统中逻辑块大小,文件系统的大小等
- i节点表:记录着文件系统中每个文件与目录
-
i节点
文件的i节点号是ls -li命令所显示的第一列:
skydeiMac:14-文件系统 sky$ ls -li7217991 -rw-r--r--@ 1 sky staff 3582 11 17 08:33 README.md
i节点主要维护如下信息:
文件类型
- 文件属主
- 文件属组
- 3类用户的访问权限
- 3个时间戳:最后访问时间(ls -lu)、最后修改时间(ls -l)、文件状态的最后改变时间(ls -lc),一般不会记录文件的创建时间
- 指向文件的硬链接数量
- 文件的大小,字节为单位
- 实际分配给文件的块数量,512字节为单位,不会简单的等于文件大小,因为要考虑文件中可能包含空洞
- 指向文件数据块的指针
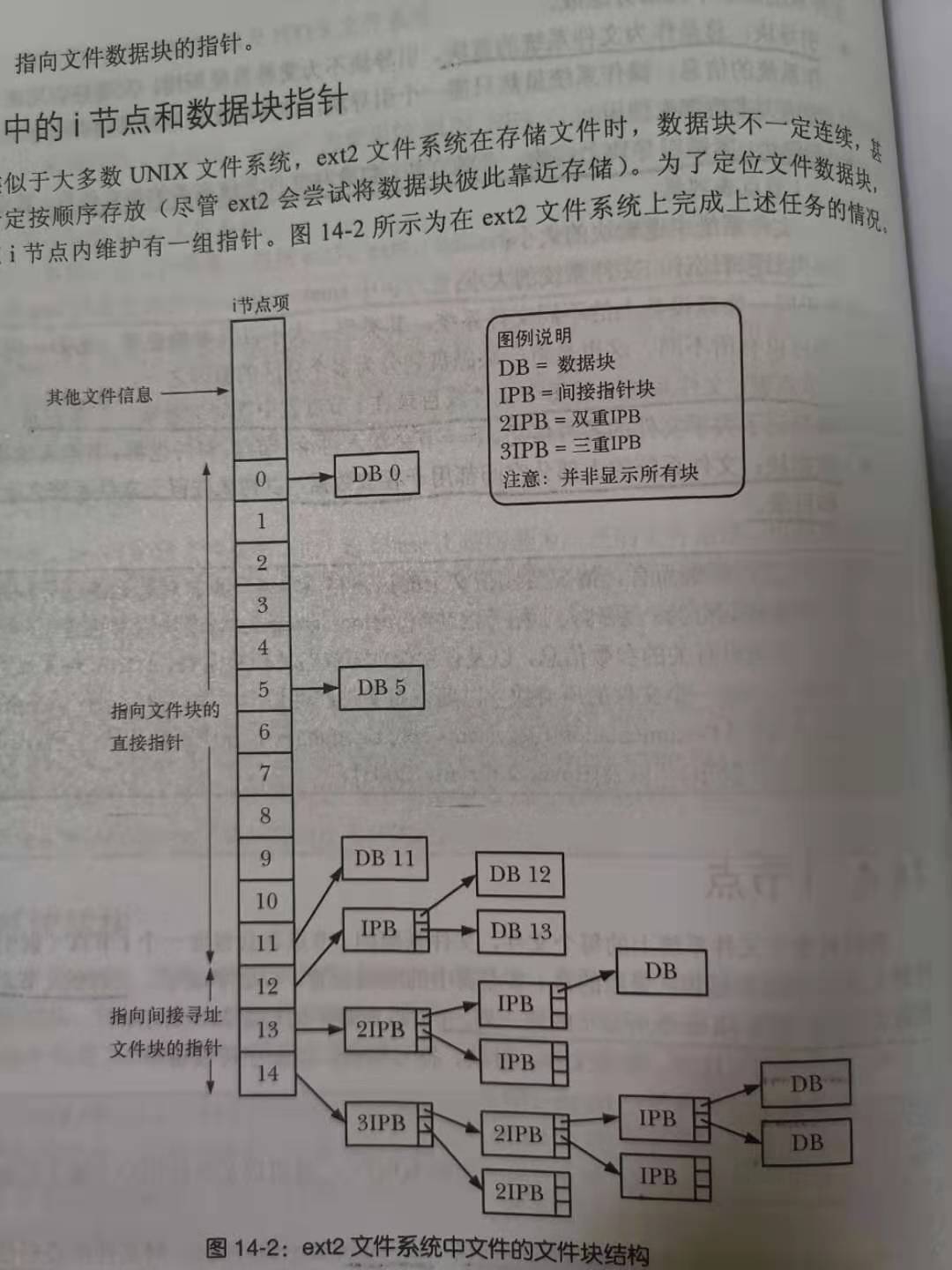
无需连续存储文件块,使得文件系统对磁盘空间利用更为高效,当然导致文件碎片化比较严重
4个层级的索引设计为了满足多重意图:维持i节点结构大小固定的同时,支持任意大小的文件;文件系统既可以不连续方式存储,又可以通过lseek随机访问,内核只需计算移动的指针;对于占绝对多数的小文件而言,满足了对文件数据块的快速访问;该设计的另一个优点是文件可以有黑洞,文件系统只需将i节点和间接指针块中的相应指针打上标记(值为0),表明这些指针并未指向实际的磁盘块即可,无需为文件黑洞分配字节数据块
虚拟文件系统
- VFS针对文件系统定义了一套通用接口
- 每个文件系统都会提供VFS接口的实现
VFS接口包括:open、read、write、lseek、close、truncate、stat、mount、unmount、mmap、mkdir、link、unlink、symlink、rename
日志文件系统
系统奔溃重启时会对数据进行一致性检查fcsk,系统奔溃时,对文件的更新可能只完成了一部分,文件系统元数据将处于不一致状态,一致性检查需要遍历整个文件系统,如果是大型系统,耗时极大
采用日志文件系统,会将更新操作记录于专用的磁盘日志文件中,对元数据的更新记录是按相关性分组(以事务记录)进行,在事务处理过程中,一旦系统奔溃,重启时可利用日志重做redo任何不完整的更新,同时将文件系统恢复到一致性状态,即便是大型系统,通常也会在几秒内完成
日志文件系统增加了文件更新的时间,某些系统只会确保文件元数据的一致性,而不记录文件数据,一旦系统奔溃,可能造成数据丢失,但是记录东西过多,会降低文件IO性能
Linux支持的日志文件系统:
- Reiserfs:首个被集成到内核
- ext3:为ext2追加了日志功能
- JFS:IBM开发
- XFS:SGI开发
- Ext4:ext3的接班人,可降低碎片化、纳秒级别时间戳的支持、更为快捷的文件系统检查
Btrfs:读作Butter FS,B树FS,一种自上而下进行设计的新型文件系统,提供了一系列现代化特性
单根目录层级和挂载点
Linux上所有文件系统都挂载在根目录/下,超级用户可用如下命令在挂载文件系统:
mount device dir
将名为device的文件系统挂载到由dir所指定的目录,可使用unmount命令卸载文件系统,然后在另一个挂载点再次挂载,从而改变文件系统的挂载点,如今每个进程都有挂载命令空间,意味着每个进程都可能拥有属于自己的一组文件系统挂载点
mount命令可以列出当前已经挂载的文件系统:mount/dev/disk2 on / (hfs, local, journaled)devfs on /dev (devfs, local, nobrowse)map -hosts on /net (autofs, nosuid, automounted, nobrowse)map auto_home on /home (autofs, automounted, nobrowse)/dev/disk3s2 on /Volumes/人人影视 (hfs, local, nodev, nosuid, read-only, noowners, mounted by sky)/dev/disk4s2 on /Volumes/人人影视 1 (hfs, local, nodev, nosuid, read-only, noowners, mounted by sky)/dev/disk5s2 on /Volumes/QQMusic (hfs, local, nodev, nosuid, read-only, noowners, mounted by sky)
文件系统的挂载和卸载
包含当前挂载文件系统信息的三个文件:
Linux专有的虚拟文件/proc/mounts:当前已挂载的文件系统列表,每个进程都拥有一个/proc/PID/mounts文件,列出了进程挂载空间的挂载点,/proc/mounts只是指向/proc/self/mounts的符号链接
- mount和unmount自动维护/etc/mtab:包含的信息比/proc/mounts稍微详细
- /etc/fstab:系统管理员手工维护,包含了对系统支持的所有文件系统的描述
这三个文件的格式相同,如:
/dev/sda9 /boot ext3 rw 0
6个字段包括:
- 已挂载设备名
- 设备的挂载点
- 文件系统类型
- 挂载标志
- 一个数字:dump用它控制对文件系统的备份操作,只有/etc/fstab会用到,其他两个文件该字段是0
- 一个数字:系统引导时,fsck用它来控制文件系统的检查顺序,只有/etc/fstab会用到,其他两个文件该字段是0
—->挂载文件系统:mount
将source指定设备所包含的文件系统,挂载到target指定的目录:#include <sys/mount.h>int mount(const char *source, const char *target, const char *fstype, unsigned long mountflags, const void *data);// 返回值:若成功,返回0,若出错,返回-1// fstype是文件系统类型,如ext4或btrfs// mountflags的取值:MS_BIND:执行bind挂载,使文件或者子目录树在文件系统内的另一个点上可视MS_DIRSYNC:同步目录的更新MS_MANDLOCK:允许在文件上执行强制锁MS_MOVE:移动子目录树MS_NOATIME:不要更新文件上的访问时间MS_NODEV:不允许访问设备文件MS_NODIRATIME:不允许更新目录上的访问时间MS_NOEXEC:不允许在挂上的文件系统上执行程序MS_NOSUID:执行程序时,不遵照set-user-ID和set-group-ID位MS_RDONLY:指定文件系统为只读MS_REMOUNT:重新加载文件系统,允许改变现存文件系统的mountflag和数据,而无需使用先卸载,再挂上文件系统的方式MS_REALTIME:只有当最后访问时间早于最后修改时间或最后状态变更时间,才对前者进行更新MS_STIRCTATIME:总是更新最后访问时间MS_SYNCHRONOUS:同步文件的更新
—->卸载文件系统:unmount
target指定卸载文件系统的挂载点:
unmount2是unmount的扩展版本,通过flags参数,可以有更精密的控制:#include <sys/mount.h>int unmount(const char *target);// 返回值:若成功,返回0,若出错,返回-1// 无法卸载正在使用中的文件系统,即有文件被打开,或当前工作目录驻留在此文件系统下,返回EBUSY错误
#include <sys/mount.h>int unmount2(const char *target, int flags);// 返回值:若成功,返回0,若出错,返回-1// flags的取值:MNT_DETACH:执行lazy卸载,当所有进程不再使用访问点时,系统会卸载相应的文件系统MNT_EXPIRE:将挂载点标记为到期,这提供了一种机制:卸载某段时间内未用的文件系统MNT_FORCE:强制卸载,即使文件系统处于忙状态UNMOUNT_NOFOLLOW:若target为符号链接,不进行解引用,专为set-user-ID-root程序设计,允许非特权用户执行卸载操作,意在避免安全性问题的发生
高级挂载特性
—->在多个挂载点挂载文件系统
可以将同一个文件系统挂载于文件系统内的多个位置,由于每个挂载点下的目录子树内容都相同,在一个挂载点下对目录子树做的改变,其他挂载点也会改变:suPassword:mkdir /testfs // 新建两个文件夹mkdir /demomount /dev/sda12 /testfs // 将一个设备挂载到两个不同的目录mount /dev/sda12 /demomount | grep sda12/dev/sda12 on /testfs type ext3(rw)/dev/sda12 on /demo type ext3(rw)touch /testfs/myfile // 在一个目录下新建文件ls /demo // 此文件在另一个目录也存在lost+found myfile
—->多次挂载同一挂载点
内核2.4之后,Linux允许针对同一个挂载点进行多次挂载,每次新挂载都会隐藏之前可见于挂载点下的目录子树,卸载最后一次挂载时,挂载点下上次挂载的内容会再次显示:suPassword:mount /dev/sda12 /testfstouch /testfs/myfile // 在sda12上新建文件mount /dev/sda13 /testfs // 在同一个目录挂载第二次mount | grep testfs/dev/sda12 on /testfs type ext3(rw)/dev/sda13 on /testfs type reiserfs(rw)touch /testfs/newfile // 在sda13上新建文件ls /testfsnewfileunmount /testfs // 卸载sda13,此时sda12处于栈顶mount | grep testfs/dev/sda12 on /testfs type ext3(rw)ls /testfs // 在sda12上文件显现lost+found myfile
—->基于每次挂载的挂载标志
从内核2.4开始,文件系统和挂载点之间不是一一对应的关系,如下所示,同一文件系统对应两个挂载点,MS_NOEXEC标志的影响,mount的其他标志也类似:suPassword:mount /dev/sda12 /testfs // 同一设备挂载到testfsmount -o -noexec /dev/sda12 /demo // 同一设备挂载到demo,但不允许执行程序cat /proc/mounts | grep sda12/dev/sda12 /testfs ext3 rw 0 0/dev/sda12 /demo ext3 rw,noexec 0 0cp /bin/echo /testfs/testfs/echo 'Art is something which is well done' // testfs下可以执行echoArt is something which is well done/demo/echo "Art is something which is well done" // demo下不可以执行echobash: /demo/echo: Permission denied
—->绑定挂载
是指在文件系统目录层级的另一处挂载目录或文件,导致文件或目录在两处同时可见,类似于硬链接,区别如下:
- 绑定挂载可以跨越多个文件系统挂载点,甚至不拘于chroot监禁区
可针对目录执行绑定挂载
suPassword:pwd:/testfsmkdir d1touch d1/xmount --bind d1 d2 // 创建绑定挂载目录ls d2 // d2可以看见d1的内容xtouch d2/yls d1 // d1可以看见d2的内容y
cat > f1 // 创建文件并写入内容Chance is powerful,touch f2mount --bind f1 f2 // 创建绑定挂载文件mount | egrep '(d1|d2)'/testfs/d1 on /testfs/d2 type none (rw, bind)/testfs/f1 on /testfs/f2 type none (rw, bind)cat >> f2 // 给f2写入内容can you grab it?cat f1 // 查看f1的内容Chance is powerful, can you grab it?rm f2rm: cannot unlink 'f2': Device or resource busyunmount f2 // 先要卸载才能删除rm f2
—->递归绑定挂载
默认情况下,MS_BIND为某个目录创建绑定挂载,不会将其子目录也挂载,如果需要递归绑定挂载,需要用MS_BIND与MS_REC相与,mount的—rbind提供类似功能
首先创建一个目录树src1,将其挂载到top下,而top下包括字挂在src2:suPassword:mkdir topmkdir src1touch src1/aaamount --bind sr1 top // 创建绑定挂载,src1挂载在top下mkdir top/submkdir src2touch src2/bbbmount --bind src2 top/sub // 创建绑定挂载,src2挂载在top/sub下find toptoptop/aaatop/subtop/sub/bbb
以top作为源目录,另行创建绑定挂载,属于非递归操作,新挂载不会复制子挂载:
mkdir dir1mount --bind top dir1find dir1dir1dir1/aaadir1/sub
再以top作为源目录创建递归绑定挂载:
mkdir dir2mount --rbind top dir2find dir2dir2dir2/aaadir2/subdir2/sub/bbb
虚拟内存文件系统:tmpfs
Linux支持驻留于内存的虚拟文件系统,和其他文件系统并无二致,由于不涉及磁盘访问,操作速度极快,最为复杂的莫过于tmpfs,不但使用RAM,在RAM耗尽的情况下,还会利用交换空间,它是可选组件,通过CONFIG_TEPFS选项配置,要创建tmpfs文件系统:
mount -t tmpfs source target// source是任意名称,只在/proc/mounts中出现,target是文件系统的挂载点// 可以使用堆叠挂载
可以采用如下命令改善程序性能,此类程序因创建临时文件而频繁使用/tmp目录:
mount -t tmpfs newtmp /tmpcat /proc/mounts | grep tmpnewtmp /tmp tmpfs rw 0 0
一旦卸载tmpfs或遭遇系统奔溃,那么该文件系统中所有数据将丢失,tmpfs因此得名,tmpfs还有两个用途:
内核挂载的隐形tmpfs文件系统,用于实现System V共享内存和共享匿名内存映射
- 挂载于/dev/shm的tmpfs文件系统,为glibc用以实现POSIX共享内存和POSIX信号量
获取与文件系统有关的信息:statvfs
#include <sys/statvfs.h>int statvfs(const char *pathname, struct statvfs *statvfsbuf);int fstatvfs(int fd, struct statvfs *statvfsbuf);// 两个函数返回值:若成功,返回0,若出错,返回-1// 两个函数都是基于类似的statfs和fstatfs系统调用struct statvfs{unsigned long f_bsize; /* file system block size */unsigned long f_frsize; /* fragment size */fsblkcnt_t f_blocks; /* size of fs in f_frsize units */fsblkcnt_t f_bfree; /* # free blocks */fsblkcnt_t f_bavail; /* # free blocks for non-root */fsfilcnt_t f_files; /* # inodes */fsfilcnt_t f_ffree; /* # free inodes */fsfilcnt_t f_favail; /* # free inodes for non-root */unsigned long f_fsid; /* file system ID */unsigned long f_flag; /* mount flags */unsigned long f_namemax; /* maximum filename length */};// 对于大多数Linux而言,f_bsize和f_rsize取值一样// Linux为超级用户预留了一部分文件系统块,即便在文件系统空间耗尽的情况下,超级用户仍然可以登录系统解决故障// f_flag字段是位掩码标志,用于挂载文件系统// 某些UNIX使用f_fsid来返回文件系统的唯一标识符

若有收获,就点个赞吧
0 人点赞
