网课地址:https://www.bilibili.com/video/BV1i54y1h75W?p=37
分析:
1、先获取网站首页信息
#爬取猪八戒网站import requestsif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)print(response.text)
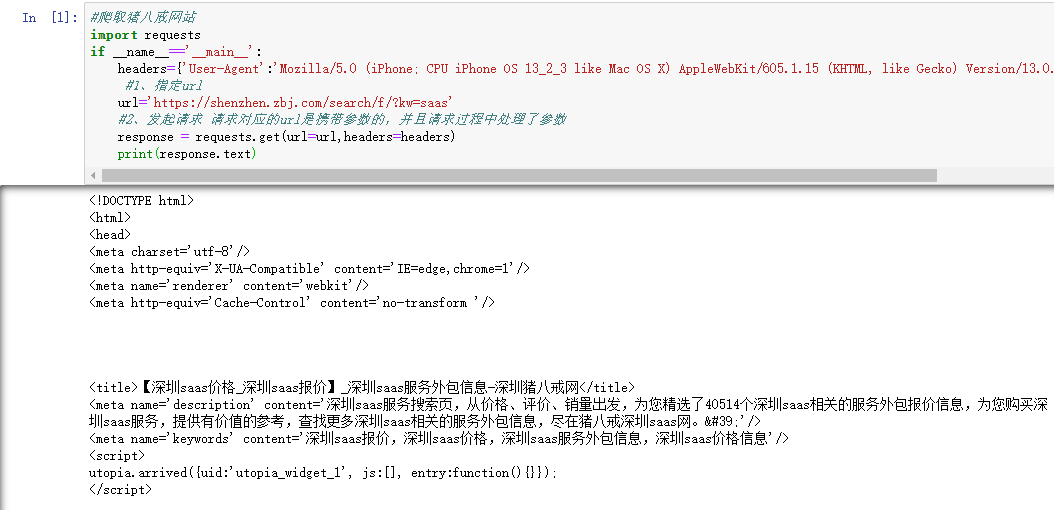
2、拿到一堆服务商的div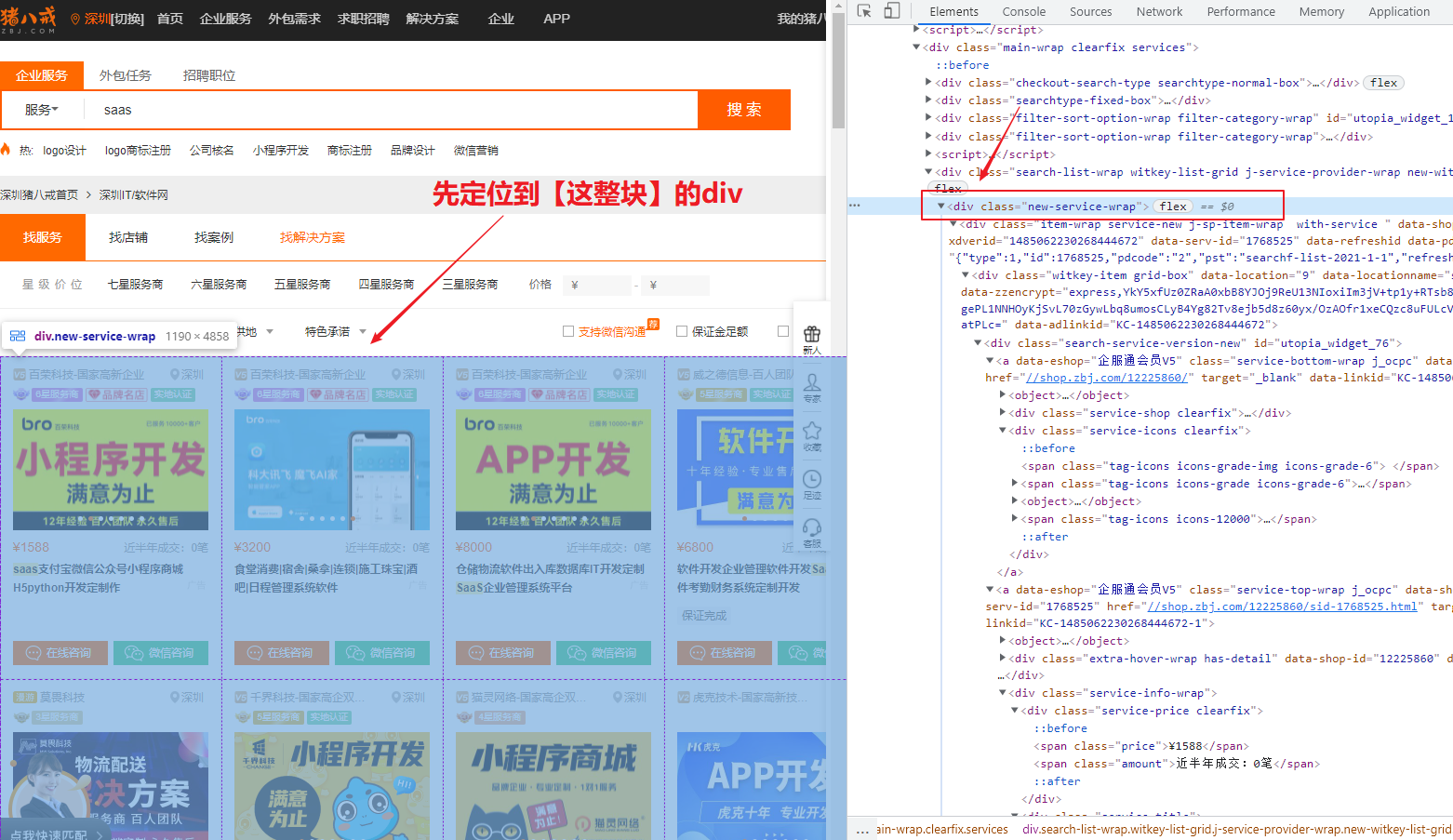
再定位都某一个服务商的div,复制xapth得到:
/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1] 这个是一个div,我们要所有的div,就把[1]去掉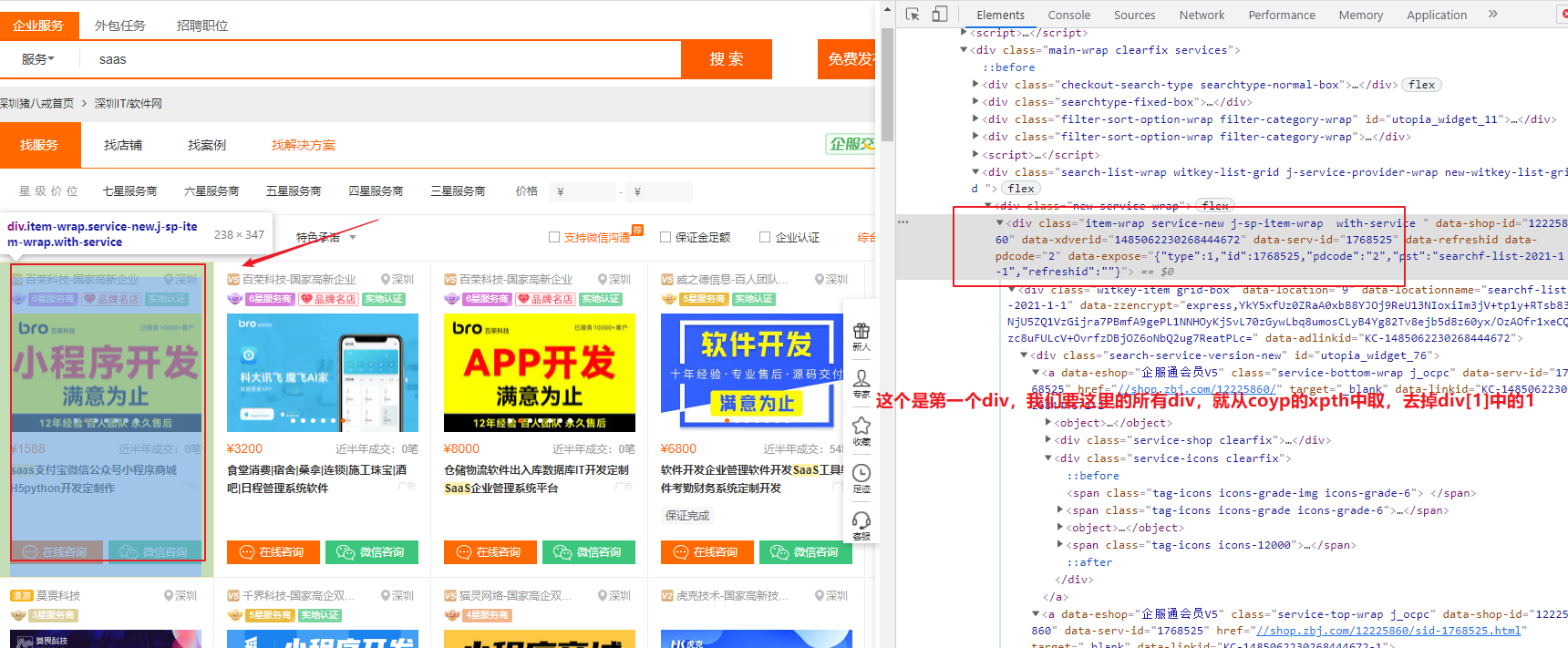
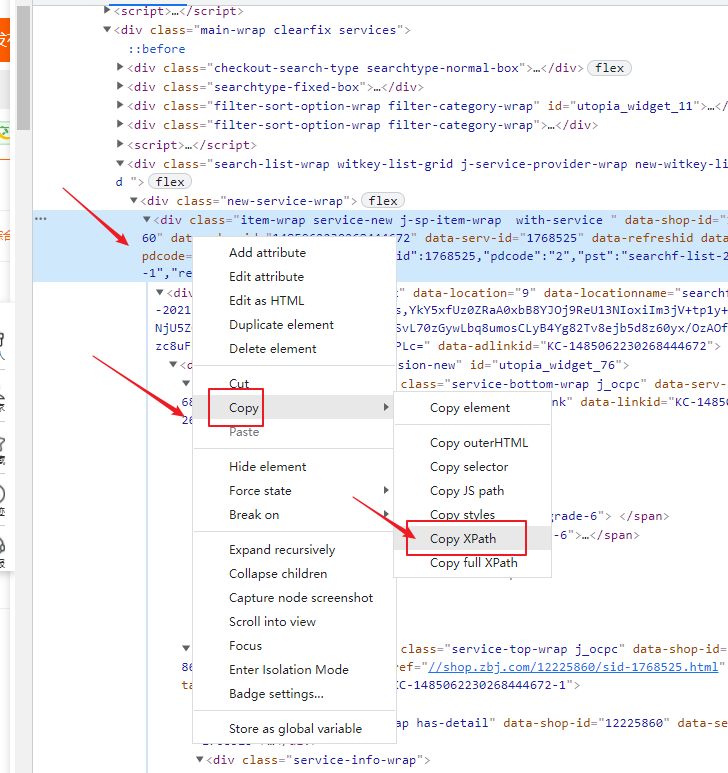
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的divprint(divs) #打印所有的div
3、然后找单个的服务商,获取价格字段
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的div# print(divs)#打印所有的divfor div in divs:#找每一个服务商price=div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()") #找价格print(price)
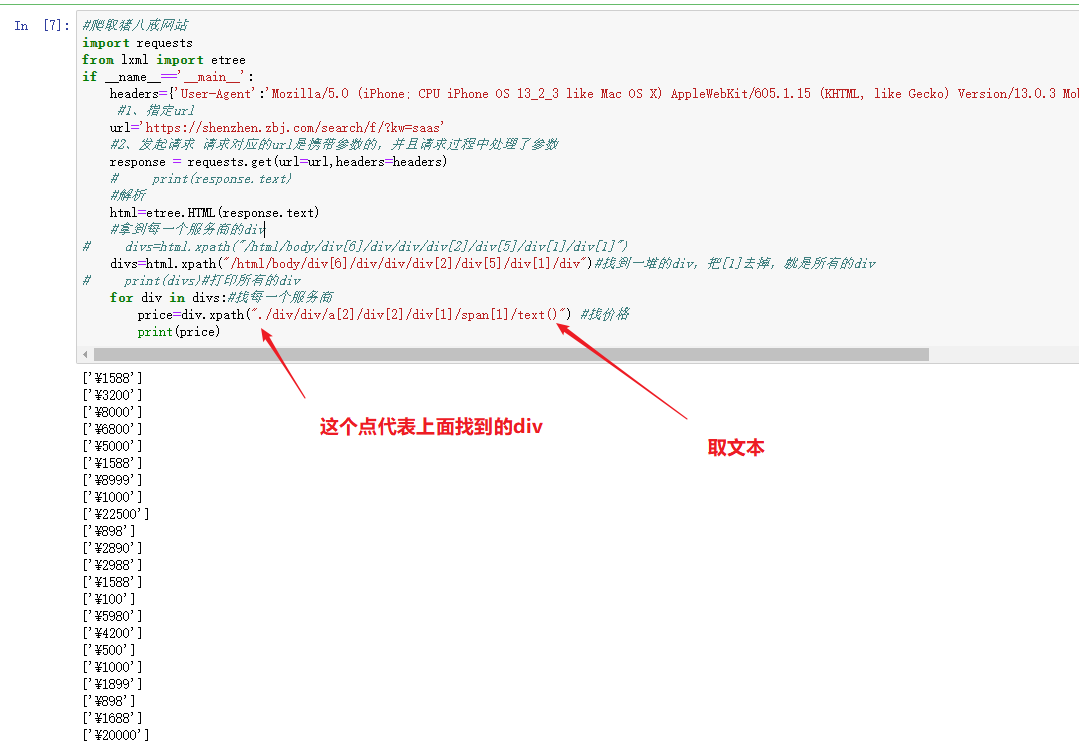

4、获取标题字段
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的div# print(divs)for div in divs:#找每一个服务商price=div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()") #找价格title=div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()") #获取标题print(title)
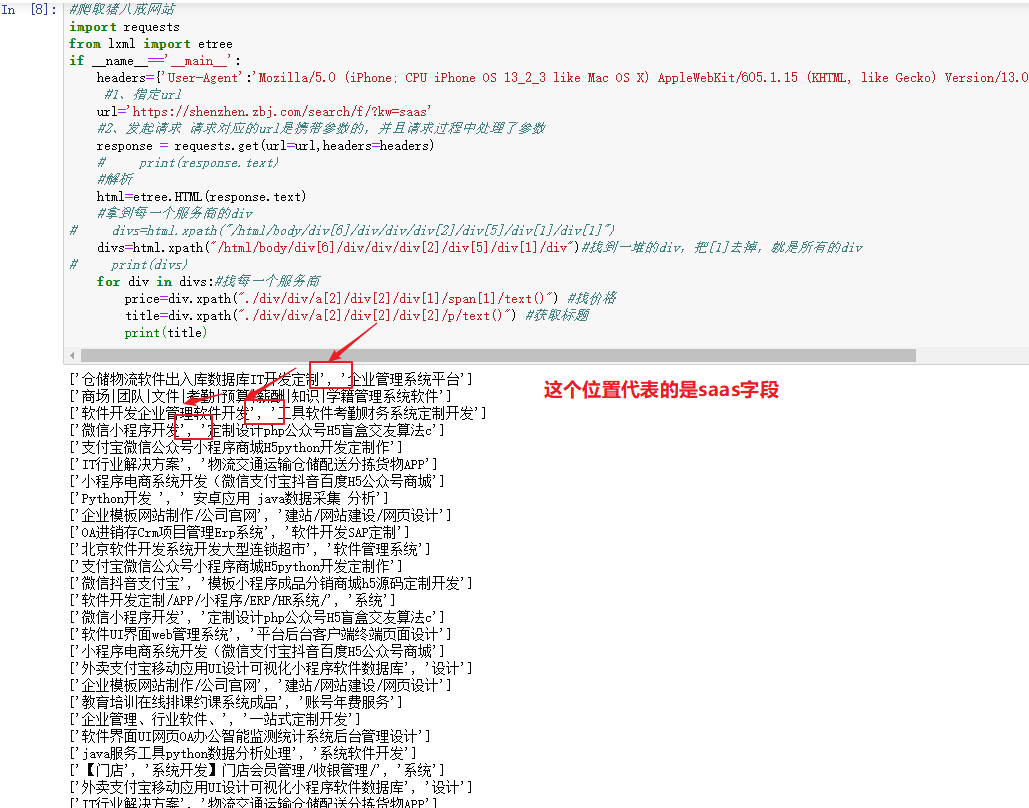
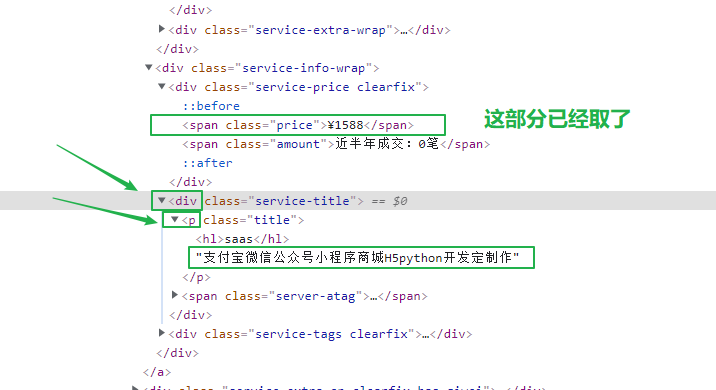
5、获取名称
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的div# print(divs)for div in divs:#找每一个服务商price=div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()") #找价格title=div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()")com_name=div.xpath("./div/div/a[1]/div[1]/p/text()")print(com_name)
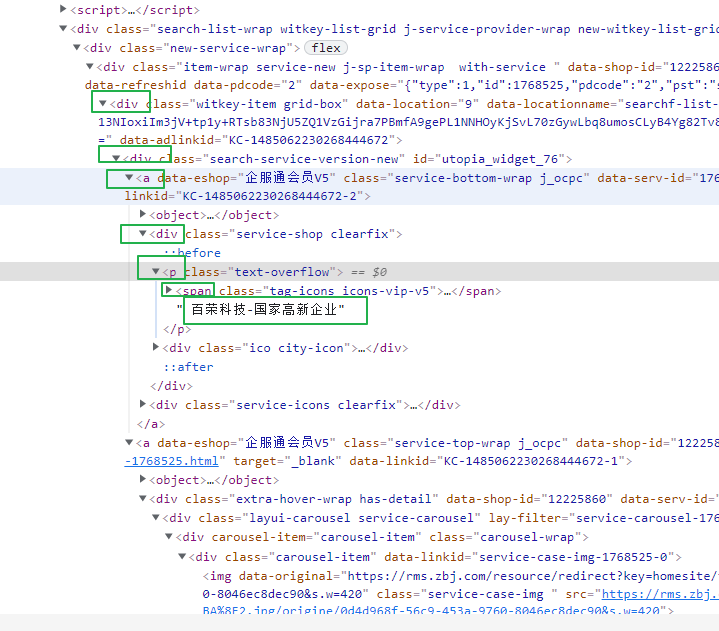
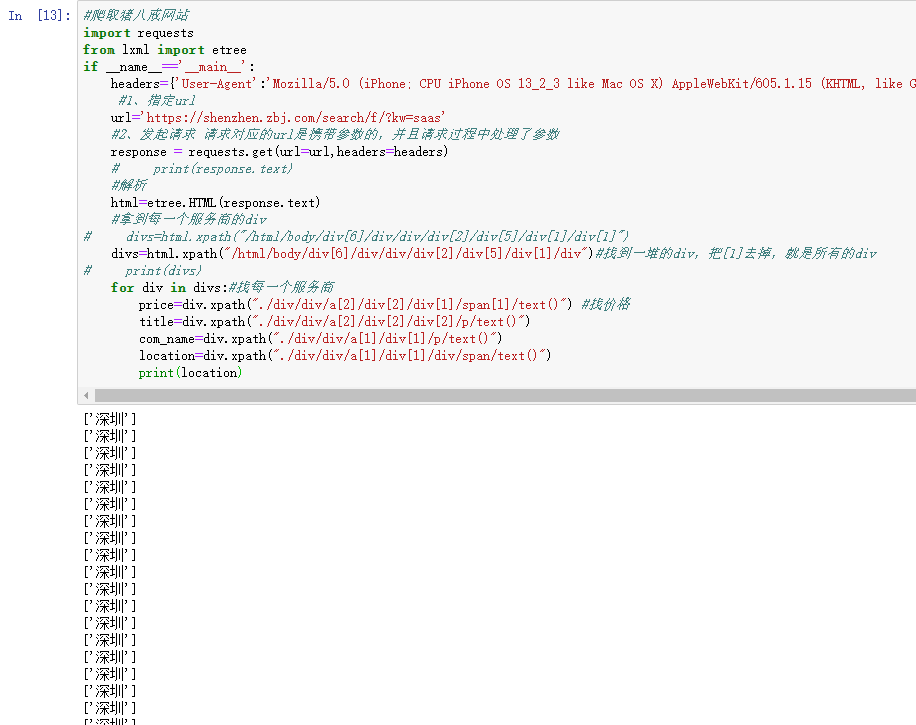
6、获取地理位置
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的div# print(divs)for div in divs:#找每一个服务商price=div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()") #找价格title=div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()")com_name=div.xpath("./div/div/a[1]/div[1]/p/text()")location=div.xpath("./div/div/a[1]/div[1]/div/span/text()")print(location)
7、处理格式
#爬取猪八戒网站import requestsfrom lxml import etreeif __name__=='__main__':headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://shenzhen.zbj.com/search/f/?kw=saas'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)#解析html=etree.HTML(response.text)#拿到每一个服务商的div# divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]")divs=html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")#找到一堆的div,把[1]去掉,就是所有的div# print(divs)for div in divs:#找每一个服务商price=div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")[0].strip("¥")#找价格,处理格式title="saas".join(div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()"))#会有个空白符,saas高亮,拼接起来com_name=div.xpath("./div/div/a[1]/div[1]/p/text()")[0]location=div.xpath("./div/div/a[1]/div[1]/div/span/text()")[0]print(location)
总结:
就是一个个去数有多少个div,里面包含什么属性
拓展:
1、把内容输入到excel;

若有收获,就点个赞吧
0 人点赞
