1、什么是爬虫?
请求网站并提取数据的自动化程序
2、爬虫的基本流程(四步走)
第一步、 发起请求request
-
第二步、 获取响应内容(response)
-
第三步、 解析内容
解析方式有很多种
1、直接处理(网站内容简单)
- 2、json解析
- 3、正则表达式
- 4、beautifulSoup解析库(bs4)
- 5、PyQuery
-
第四步、 保存数据
保存形式多样,存为文本或视频等各种形式
3、什么是Request (请求)与Response(响应)

4、Request模块包含什么?
requests模块
安装完之后就可以导入使用了
import requests
如何使用
- 指定URL
- 发起请求
- 获取响应数据
- 持久化存储
请求方式
主要有GET 和POST两种类型
Get:显示提交
Post:隐形提交
GET和POST,多数的请求是GET请求,比如在做数据查询时,建议用GET请求方式。而在做数据添加、修改或删除或者用户登陆这些场景的时候就是POST请求,因为GET请求方式的安全性较POST方式要差些,包含机密信息的话,建议用POST数据提交方式。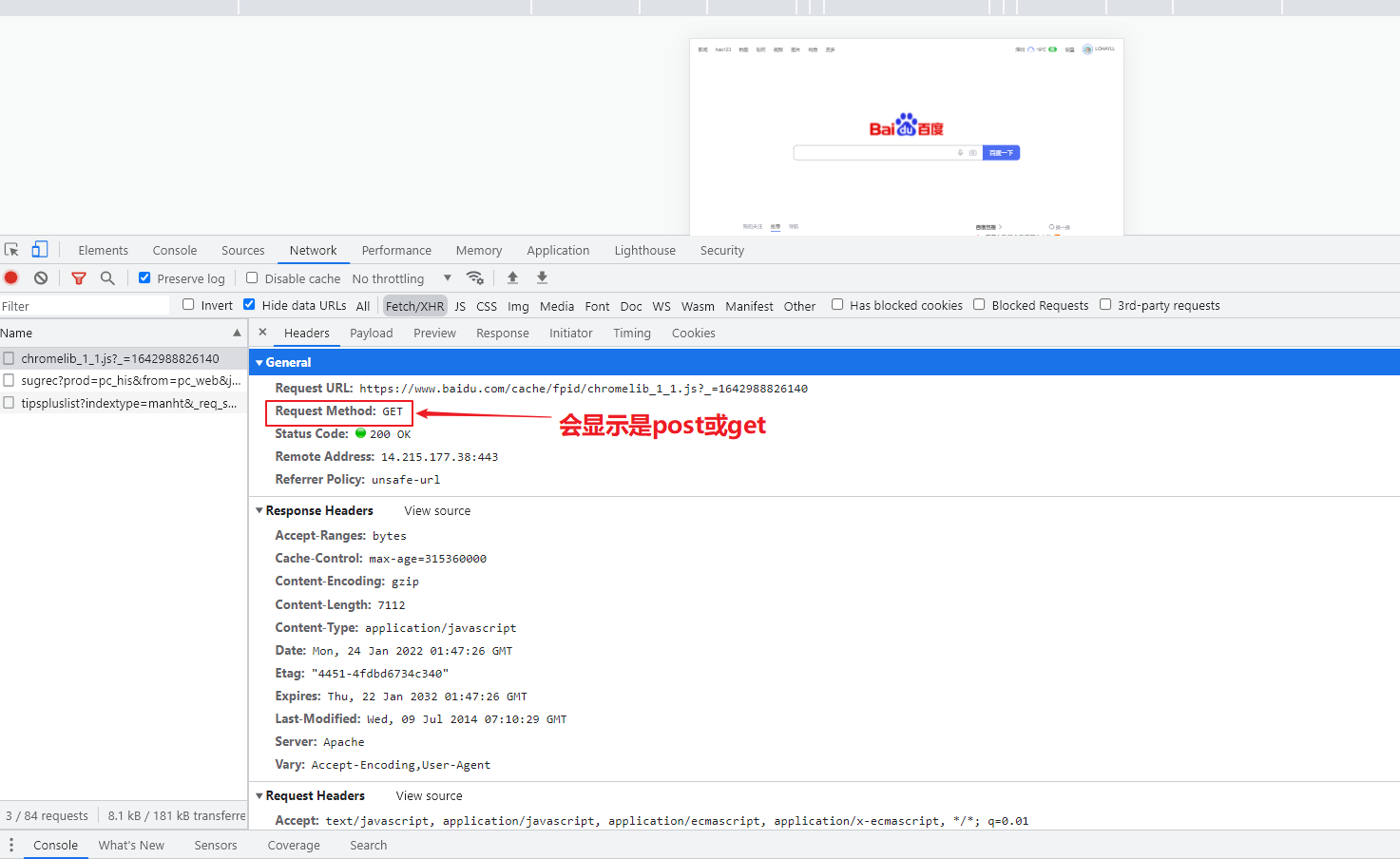
请求url
要访问的网站链接请求头(最重要)
放一些服务器要使用的附加信息
1、User-Agent:请求载体的身份标识(用啥发送的请求)
- UA检测:门户网站的服务器会检测对应的请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求,但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示这个是不正常的请求(爬虫),则服务器端很有可能会拒绝该请求。
2、Referer:防盗链(这次请求是从哪个页面来的?反爬会用到)
3、cookie:本地字符串数据信息(用户登录信息,反爬的token)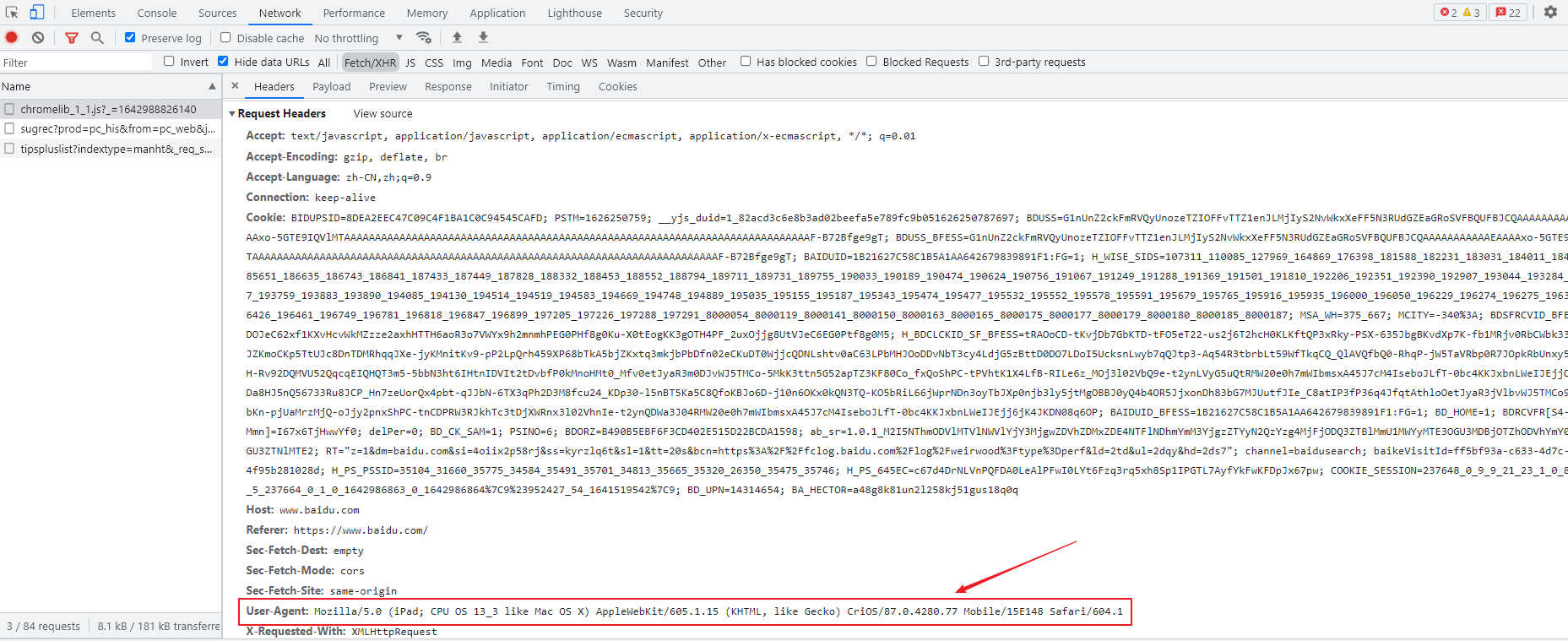
请求体
5、Response包含什么?
影响状态(状态码)
200:成功
301:跳转
404:找不到页面
502:服务器错误
响应头(最重要)
内容类型,长度
1、cookie:本地字符串数据信息(用户登录信息,反爬的token)
2、各种神奇的莫名其妙的字符串(这个需要经验,一般都是token字样,防止各种攻击和反爬)
响应体
6、能抓怎么样的数据?
7、怎么解析?
解析原理
解析的局部的文本内容都会在标签之间或标签对应的属性中进行存储;
- 进行标签定位
- 标签或标签对应的属性中存储的数据进行提取
方法
1、直接处理(网站内容简单)
2、json解析
3、正则表达式
4、beautifulSoup解析库(bs4)
5、PyQuery
6、Xpath解析(*实用性强)
8、怎么解决JavaScript渲染的问题?
1、 服务器渲染,在服务器那边直接把数据和html整合一起,统一返回给浏览器
特点:在页面源代码中能看到数据
2、 客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示
特点:在页面源代码中,得不到数据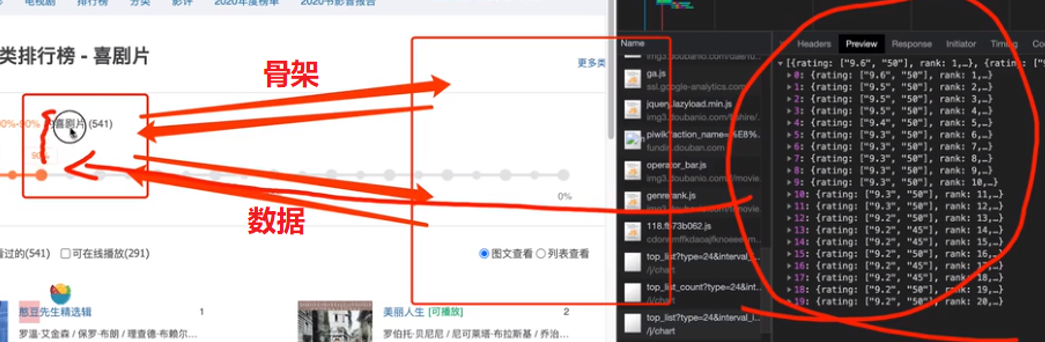
1、分析Ajax请求
2、selenium
3、splash
4、PyV8
9、怎么保存数据?
1、文本,纯文本
2、关系型数据库 mysql
3、非关系型数据库
4、二进制模式

若有收获,就点个赞吧
0 人点赞
