网课地址:https://www.bilibili.com/video/BV1i54y1h75W?p=87
可参考的文章:https://www.cnblogs.com/yourfrozen/p/15684741.html
分析:
1、访问拉勾网站
#导入模块from selenium import webdriverimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get('https://www.lagou.com')
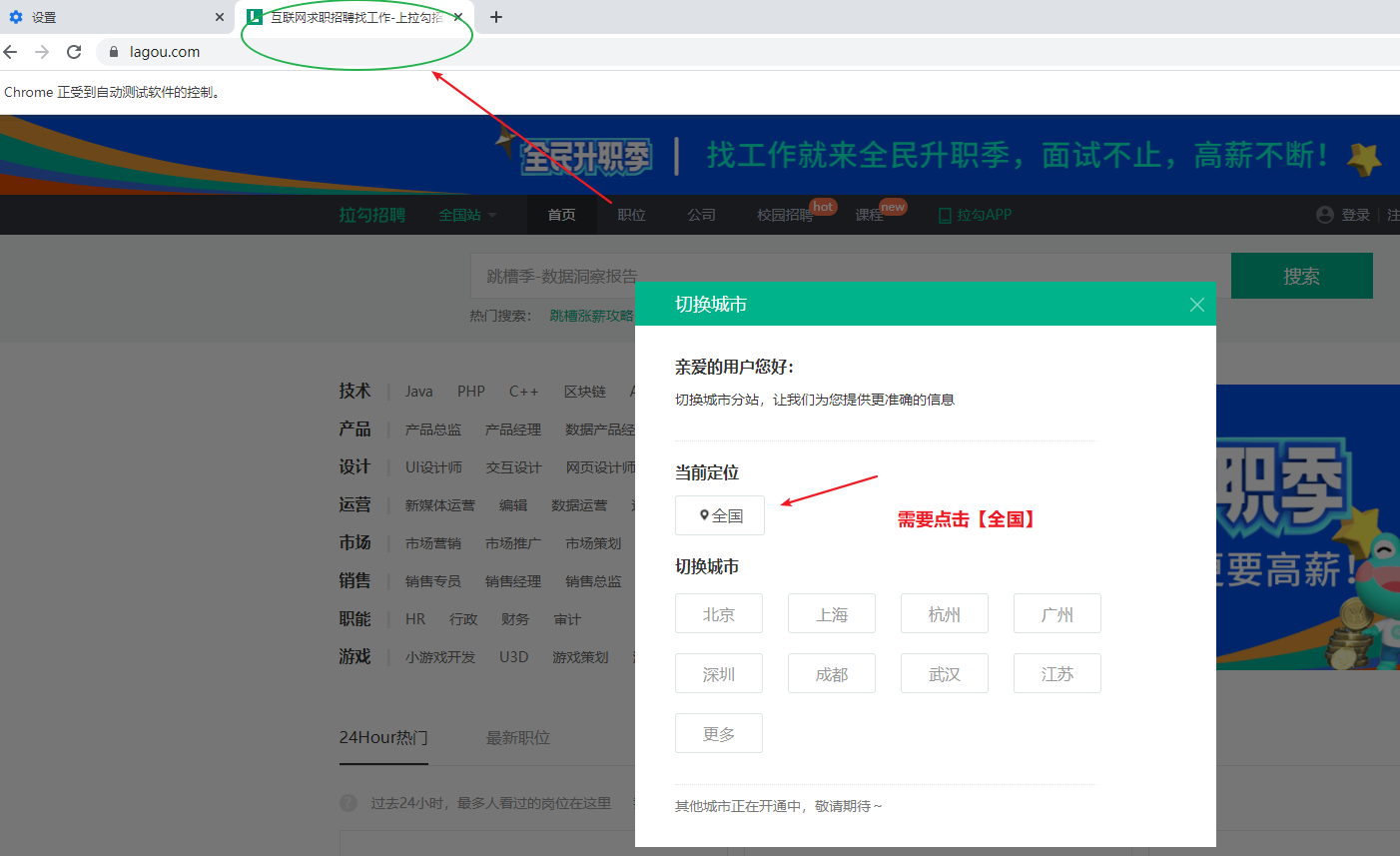
2、找到某个元素,点击它(找到全国这个按钮,点击)
from selenium.webdriver.common.by import By #导入模块el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get('https://www.lagou.com')el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国
注:网课上写的代码是:web.find_element_by_xpath(‘xxxx’),这个是老版的写法,现在用可能会提示错误,新版写法为:web.find_element(By.XPATH, ‘xxxxxx’)
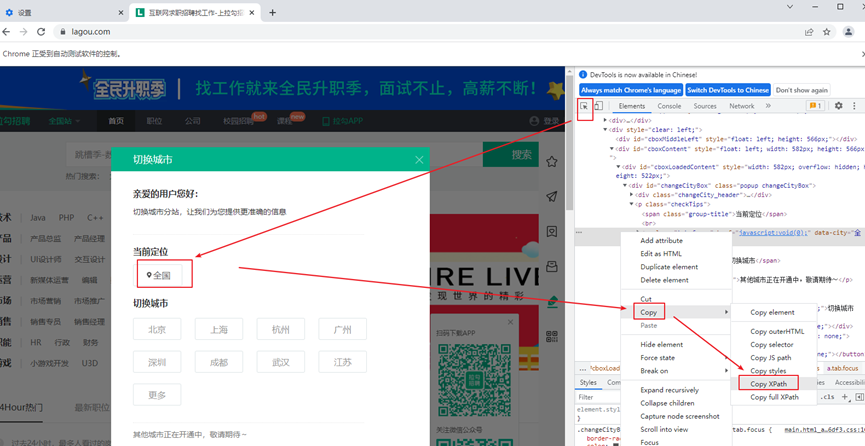
3、在职位搜索框,输入职位名称,这里以“Python开发工程师”为例
from selenium.webdriver.common.keys import Keys #导入模块#找到输入框,输入python---输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get('https://www.lagou.com')el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国#找到输入框,输入python--->输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)
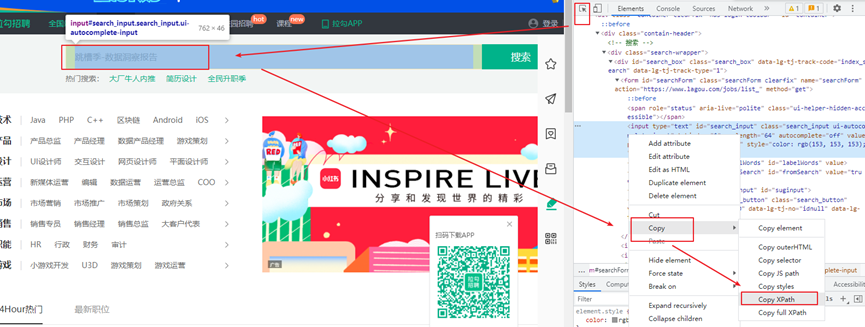
4、找到存放数据的位置,并提取数据
#查找存放数据的位置,进行数据提取#找到页面中存放数据的所有divdiv_list=web.find_elements(By.XPATH,'//*[@id="jobList"]/div[1]/div')for div in div_list:job_name=div.find_element(By.XPATH,'./div[1]/div[1]/div[1]/a').text.split("[")[0]job_city=div.find_element(By.XPATH,'./div[1]/div[1]/div[1]/a').text.split("[")[1].replace("]", "")job_money=div.find_element(By.XPATH,'./div[1]/div[1]/div[2]/span').textprint(job_name,job_city,job_money)
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get('https://www.lagou.com')el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国#找到输入框,输入python--->输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)#查找存放数据的位置,进行数据提取#找到页面中存放数据的所有divdiv_list=web.find_elements(By.XPATH,'//*[@id="jobList"]/div[1]/div')for div in div_list:job_name=div.find_element(By.XPATH,'./div[1]/div[1]/div[1]/a').text.split("[")[0]job_city=div.find_element(By.XPATH,'./div[1]/div[1]/div[1]/a').text.split("[")[1].replace("]", "")job_money=div.find_element(By.XPATH,'./div[1]/div[1]/div[2]/span').textprint(job_name,job_city,job_money)
输出结果为:
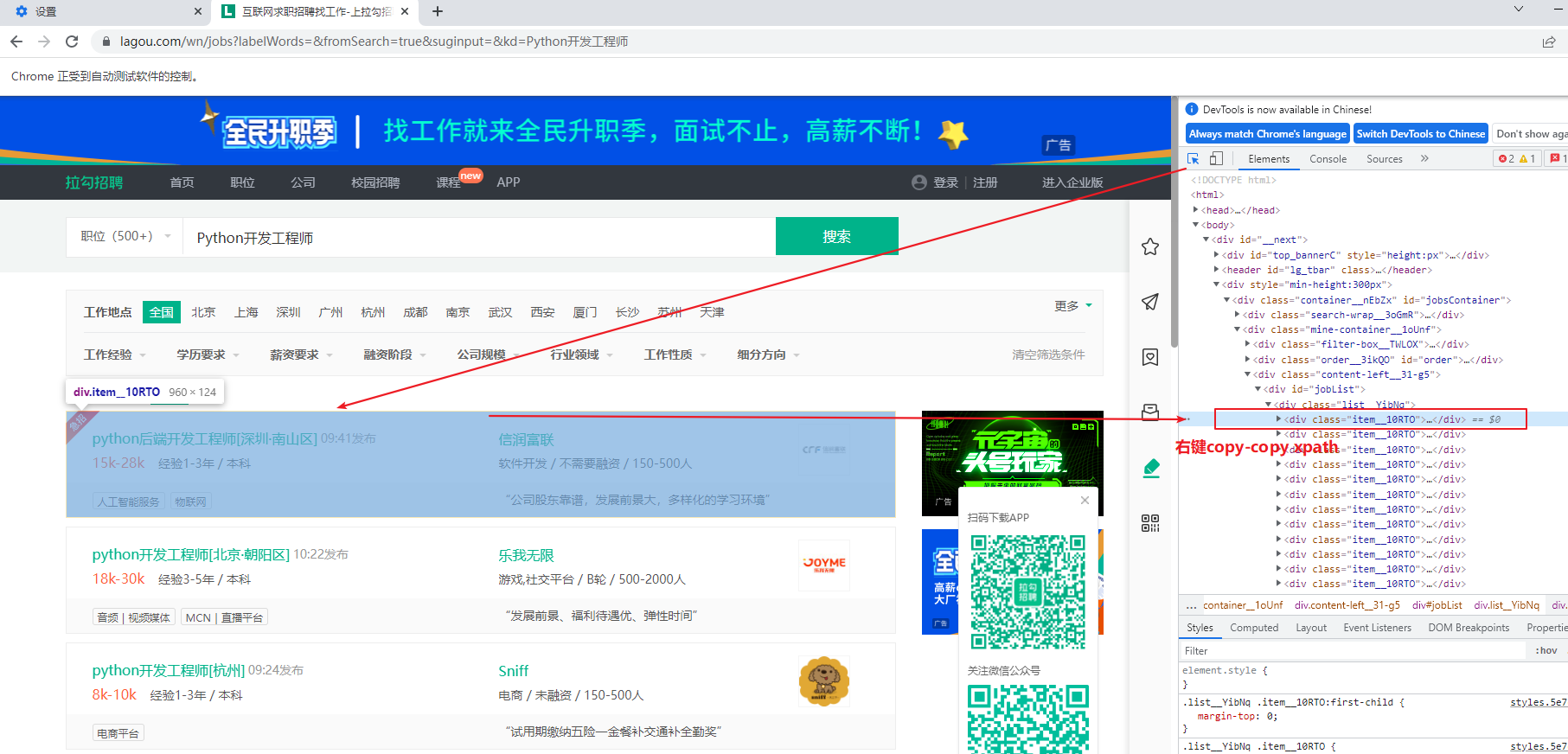
(其他字段也是一样的方法:点击按钮,在网页中点击你想查找的部分,在Elements对应代码中点击右键,Copy->Copy Xpath)
注: 1、查找所有的div,这里copy—->copy xpath的代码为://[@id=”jobList”]/div[1]/div[1] 这个要找所有div所以改成://[@id=”jobList”]/div[1]/div; 2、job_name=div.find_element(By.XPATH,’./div[1]/div[1]/div[1]/a/text()’) 这个xpath表达式放在浏览器中是对的,因为浏览器中的xpath可以通过在xpath表达式最后加上/text()获取当前节点的文本;但是在selenium中获取文本的正确写法是:job_name=div.find_element(By.XPATH,’./div[1]/div[1]/div[1]/a ‘).text
5、点击职位,打开新的页面查询另一个页面的信息
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get("https://www.lagou.com")el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国#找到输入框,输入python--->输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)#点击职位,打开新的页面查询另一个页面的信息web.find_element(By.XPATH,'//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()
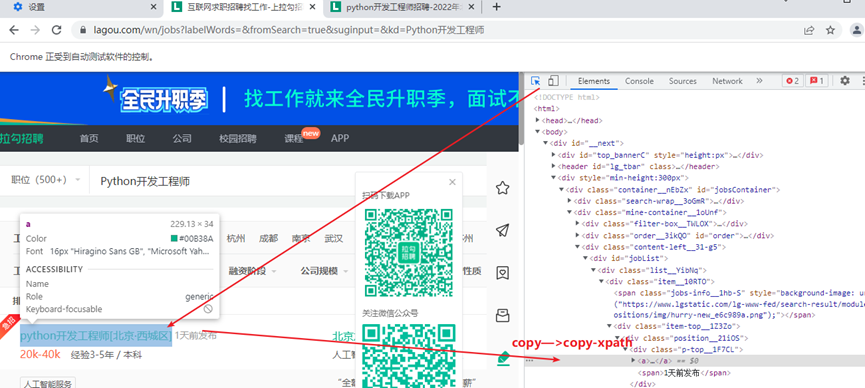
6、在新窗口中提取数据
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get("https://www.lagou.com")el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国#找到输入框,输入python--->输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)#点击职位,打开新的页面查询另一个页面的信息web.find_element(By.XPATH,'//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()#如何进入新窗口进行提取#在selenium的眼中,新窗口默认是不切换过来的web.switch_to.window(web.window_handles[-1])#到最后一个窗口,即新窗口#在新窗口中提取内容job_detail=web.find_element(By.XPATH,'//*[@id="job_detail"]/dd[2]/div').textprint(job_detail)
输出结果为:
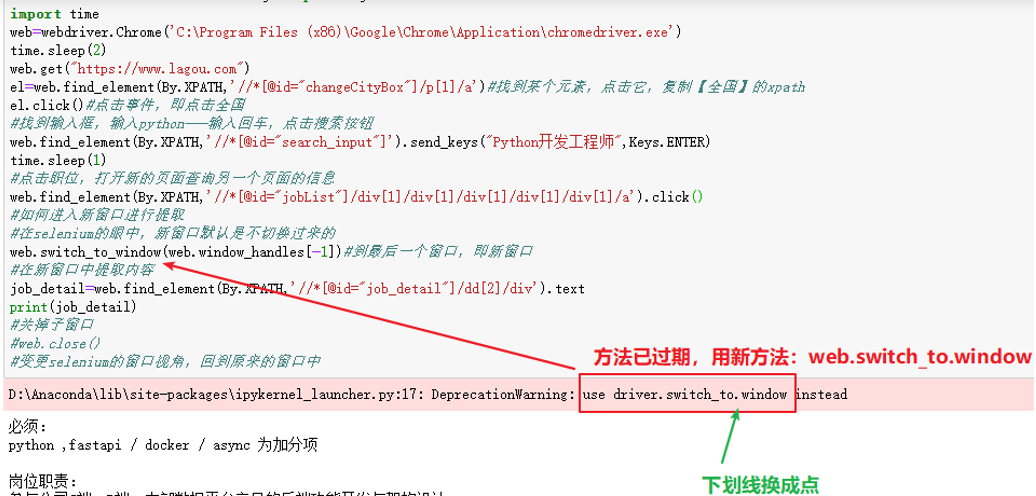
注:网课上写的代码是:web.switch_to_window(‘xxxx’),这个是老版的写法,现在用可能会提示错误, 新版写法为:web.switch_to.window
7、变更selenium的窗口视角,回到原来的窗口中
#导入模块from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timeweb=webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')time.sleep(2)#让浏览器休息一下,避免访问过快,被封ipweb.get("https://www.lagou.com")el=web.find_element(By.XPATH,'//*[@id="changeCityBox"]/p[1]/a')#找到某个元素,点击它,复制【全国】的xpathel.click()#点击事件,即点击全国#找到输入框,输入python--->输入回车,点击搜索按钮web.find_element(By.XPATH,'//*[@id="search_input"]').send_keys("Python开发工程师",Keys.ENTER)time.sleep(1)#点击职位,打开新的页面查询另一个页面的信息web.find_element(By.XPATH,'//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()#如何进入新窗口进行提取#在selenium的眼中,新窗口默认是不切换过来的web.switch_to.window(web.window_handles[-1])#到最后一个窗口,即新窗口#在新窗口中提取内容job_detail=web.find_element(By.XPATH,'//*[@id="job_detail"]/dd[2]/div').textprint(job_detail)#关掉子窗口web.close()#变更selenium的窗口视角,回到原来的窗口中,打印Python开发工程师这个标题,这个在第一页才有的web.switch_to.window(web.window_handles[1])#我们这里是1,网课上是0,因为我们这个在第二个页面[0],[1],[2],[3]...print(web.find_element(By.XPATH,'//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').text)

7、完成
拓展:
这些只是提取第一页数据的操作步骤,要抓取多页岗位信息,可自行尝试。

若有收获,就点个赞吧
0 人点赞
