源代码:
import requestsfrom bs4 import BeautifulSoupimport timeif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/meinvtupian/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8'page=BeautifulSoup(response.text,"html.parser")# print(page)lst = page.find("div", class_='TypeList').find_all("a")for a in lst:href='https://www.umeitu.com'+a.get('href') # print(href) 此刻拿到子页面的源代码#拿到子页面的源代码child_page_resp=requests.get(href)#直接通过get拿到属性的值child_page_resp.encoding='utf-8'child_page_text=child_page_resp.text#从子页面中拿到图片的下载路径child_page=BeautifulSoup(child_page_text,"html.parser")#把源代码交给bs4p=child_page.find("div", class_="ImageBody")img=p.find("img")#找到imgscr=img.get("src")#通过get拿到scr属性的值#下载图片img_resp=requests.get(scr)img_name=scr.split("/")[-1]with open("img/"+img_name,mode='wb') as f:f.write(img_resp.content)print("over!",img_name)time.sleep(1)print("all over!!")
分析:
访问网站,可以得知,我们是要先找到主页链接,找到herf下的链接,然后拼接,得到一个子链接,再访问,然后找到img,然后获取scr图片链接,然后保存下来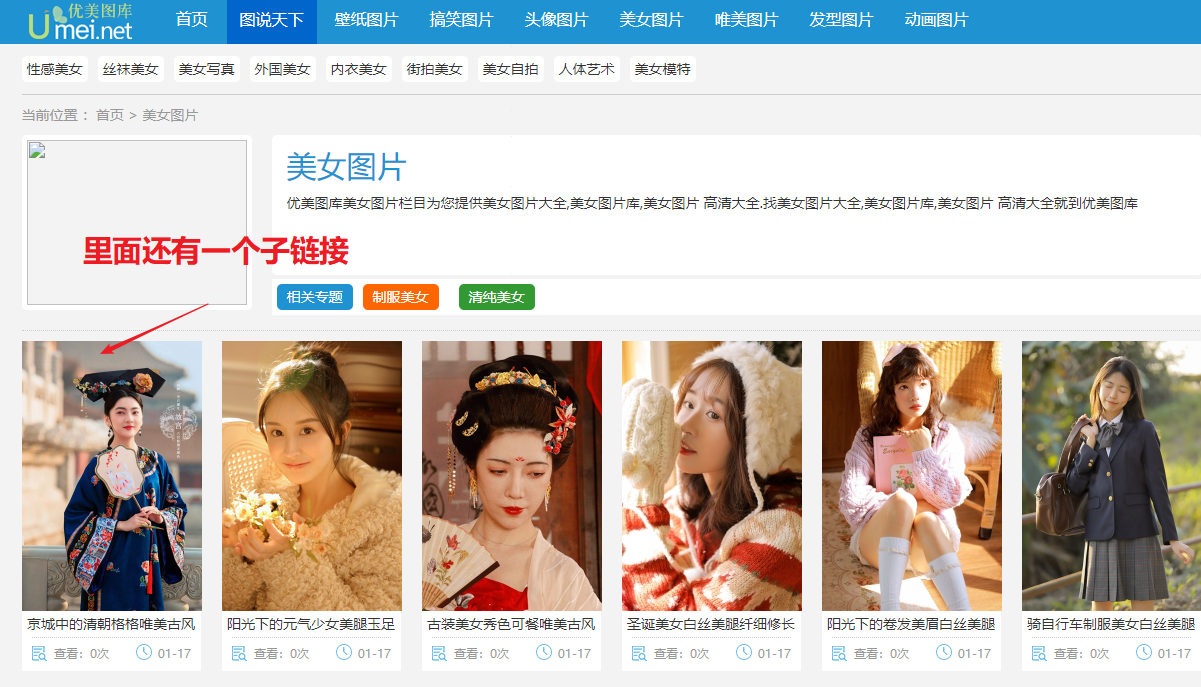
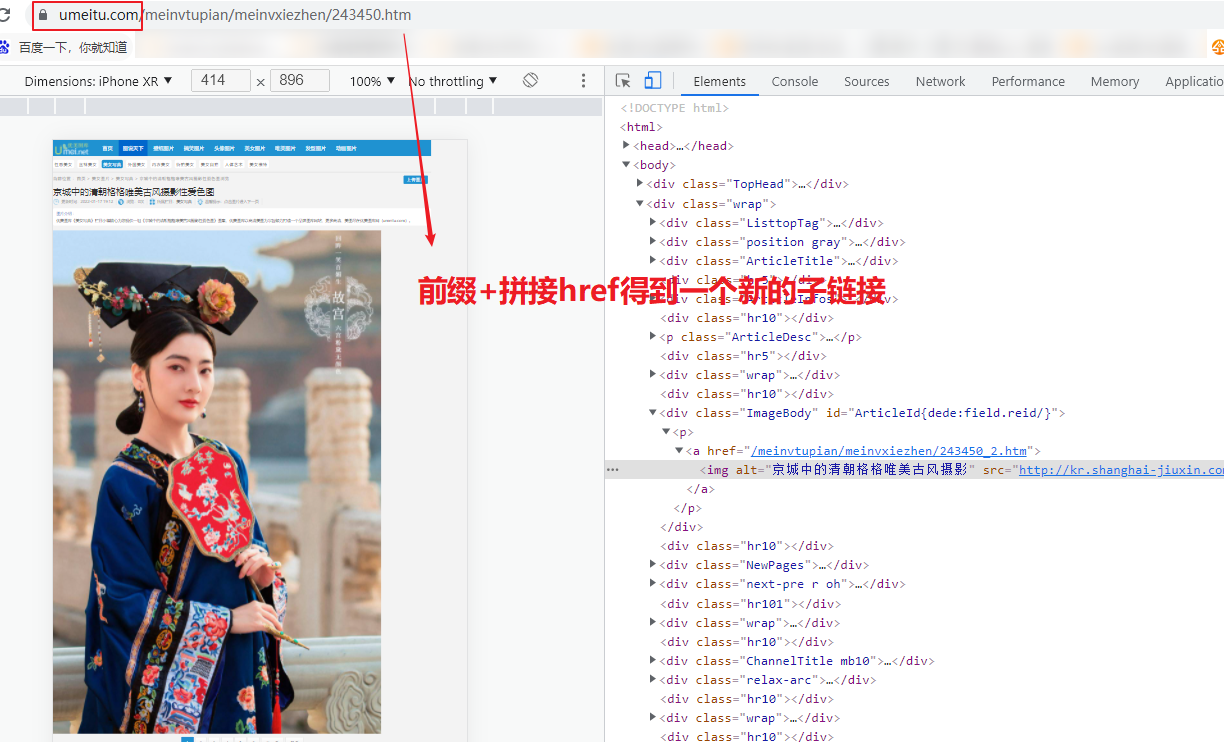
1、先抓取页面源代码;
#先爬取简单的网页htmlimport requestsfrom bs4 import BeautifulSoupif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8' #处理乱码print(response.text)
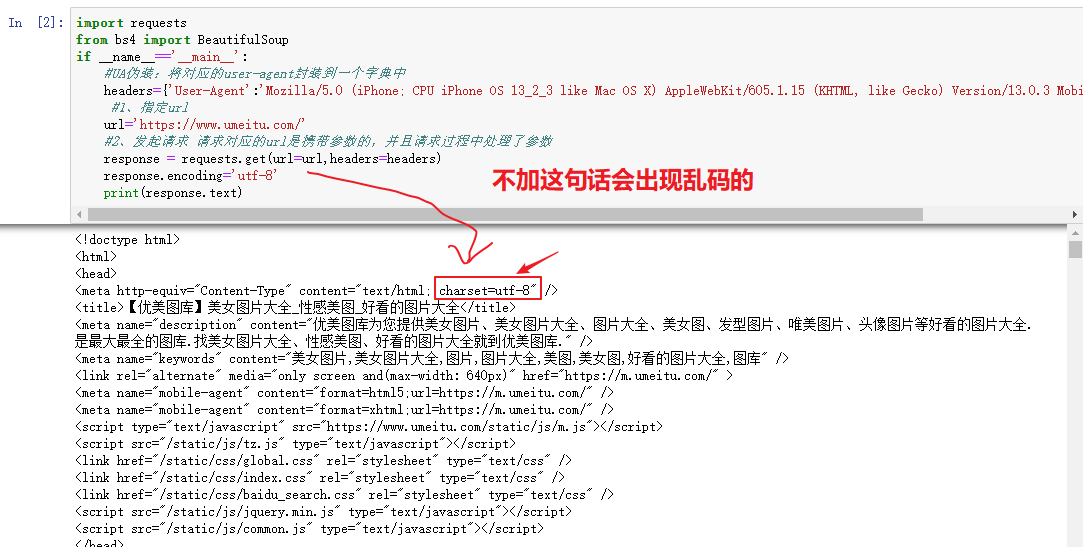
2、分析网页主页源代码,搜索TypeList可以发现有两处,第二处下面的数据不是我们想要的,而且还是TypeList2,所以可以用这个唯一属性
来缩小范围
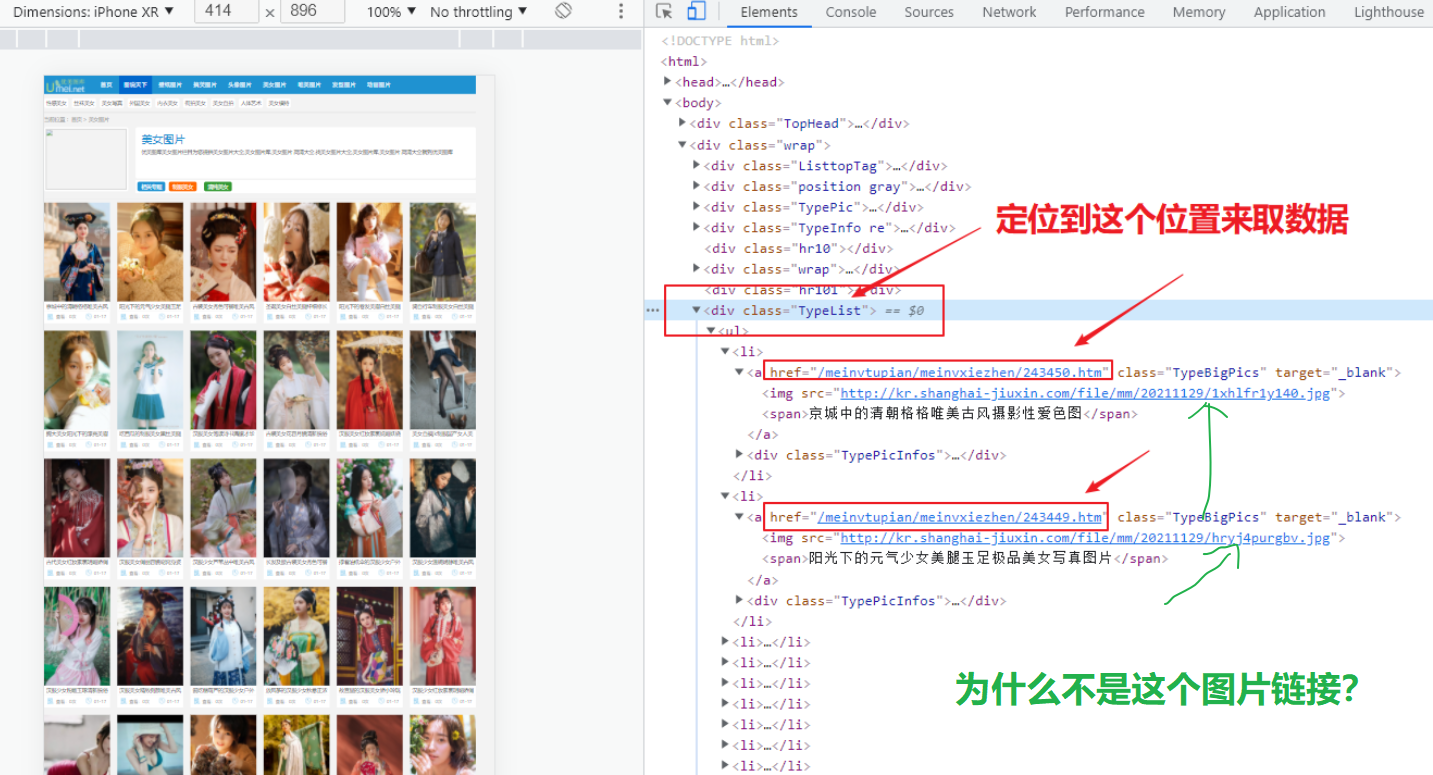
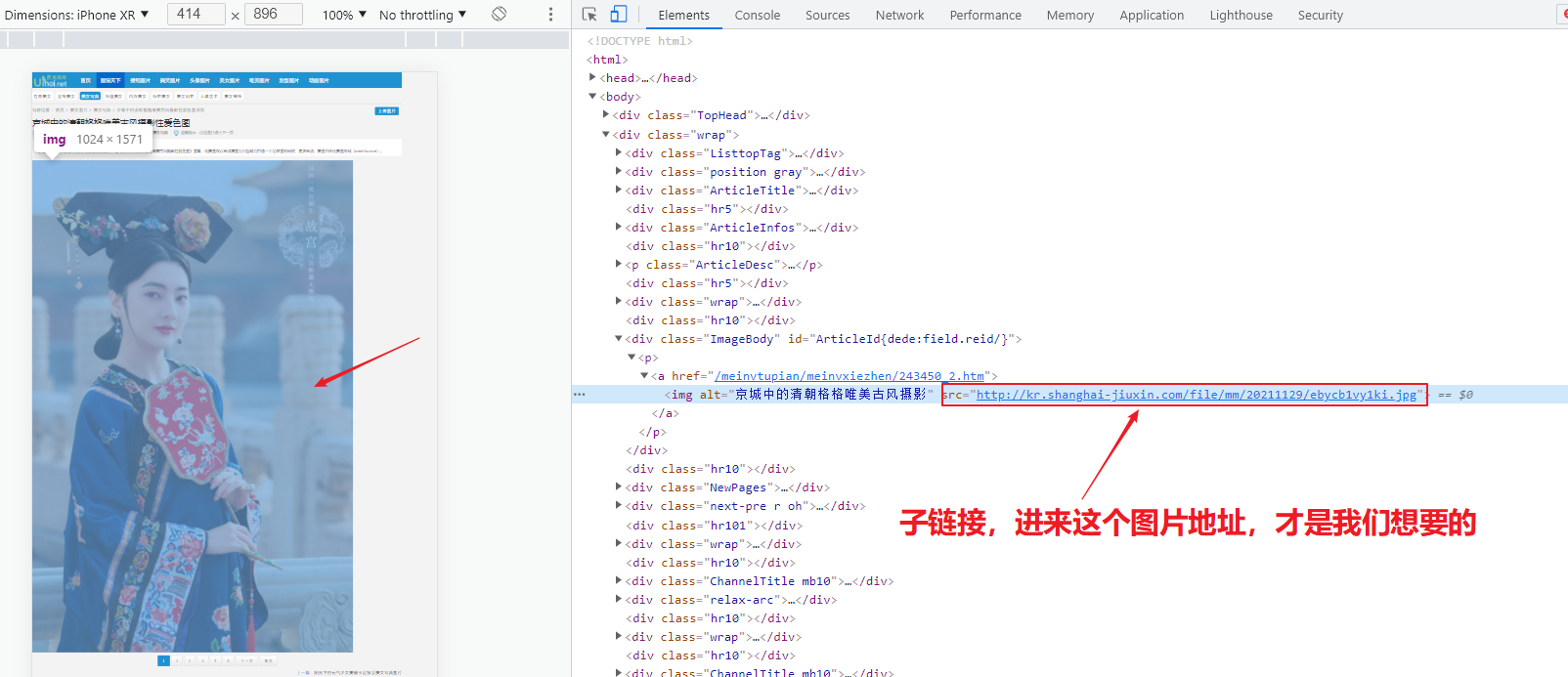
为什么不是主页面的图片链接? 这个是一个小图片,点击进去,是一个小图,我们要的是高清大图,所以要子链接里面的图片链接


然后提取子页面的链接地址,先爬取所有的a标签
page.find("div", class_=’TypeList’).find_all("a")
import requestsfrom bs4 import BeautifulSoupif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/meinvtupian/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8'#处理乱码page=BeautifulSoup(response.text,"html.parser")# print(page) #可以先打印这一步看看,一步步来lst = page.find("div", class_='TypeList').find_all("a") #先查找一个属性为<div class="TypeList">,find.all()查找所有的a标签print(lst)
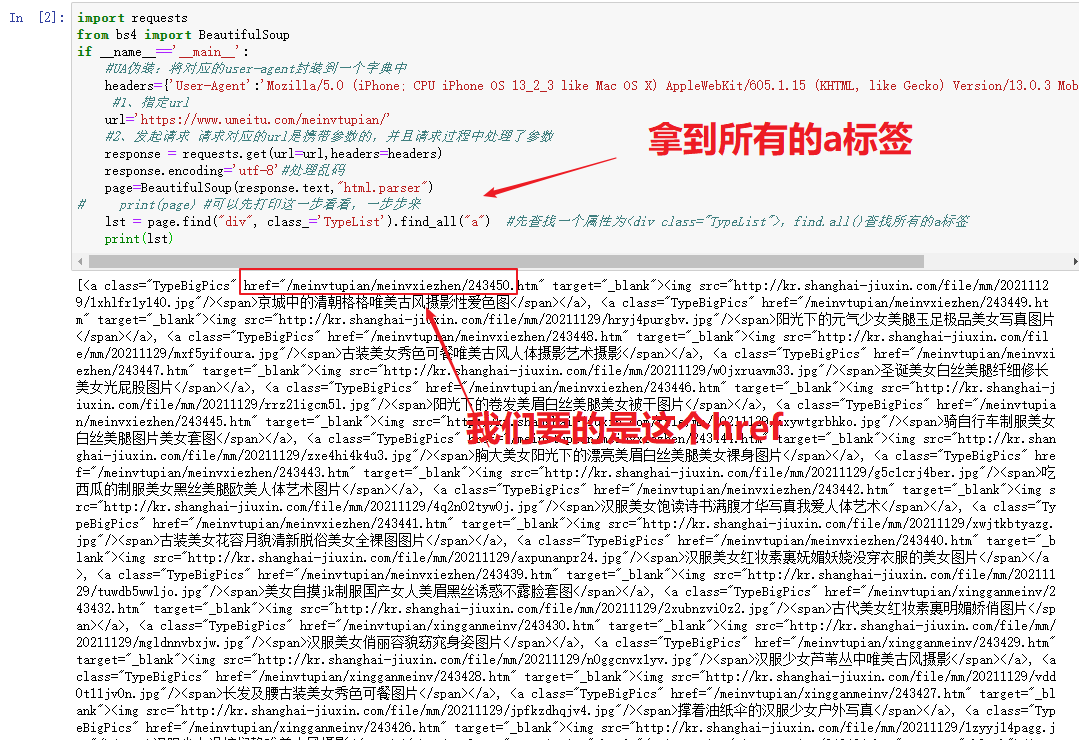
3、拿到所有的子链接,通过href拿到子页面的内容
import requestsfrom bs4 import BeautifulSoupif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/meinvtupian/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8'#处理乱码page=BeautifulSoup(response.text,"html.parser")# print(page) #可以先打印这一步看看,一步步来lst = page.find("div", class_='TypeList').find_all("a")# print(lst)for a in lst:href='https://www.umeitu.com'+a.get('href')#通过拼接可以得到一个完整的子链接print(href) #此刻拿到子页面的源代码
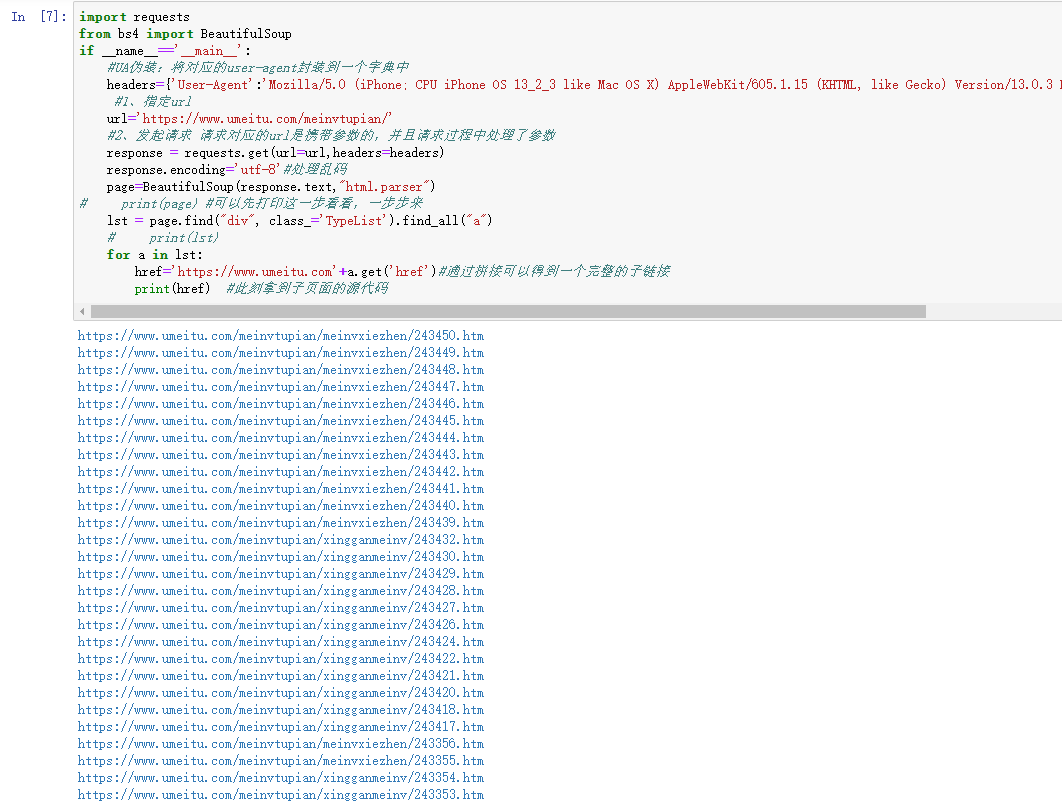
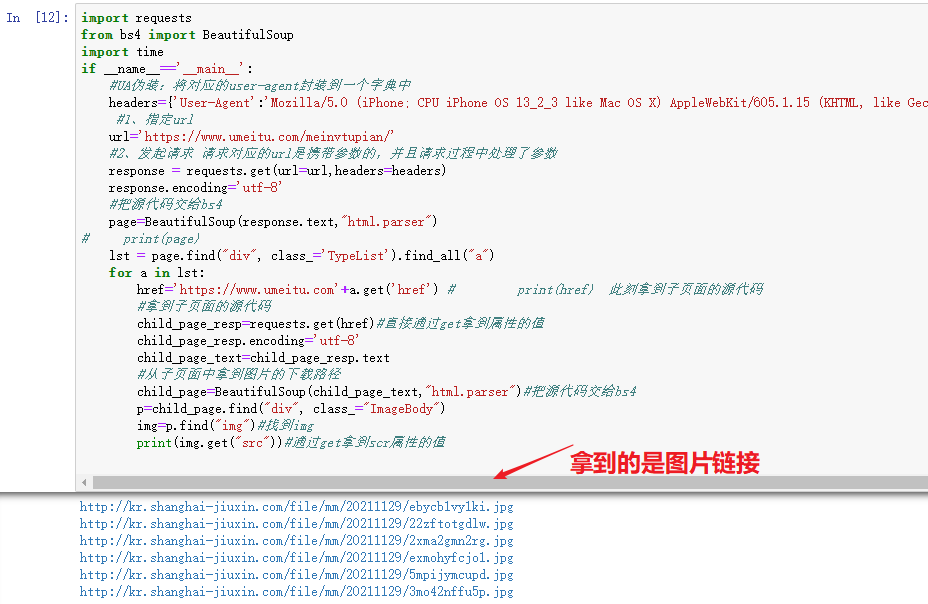
4、访问子链接后,从子页面中找到图片的下载地址, img—->src
img=p.find("img")#找到img
img.get("src")
import requestsfrom bs4 import BeautifulSoupimport timeif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/meinvtupian/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8'#把源代码交给bs4page=BeautifulSoup(response.text,"html.parser")# print(page)lst = page.find("div", class_='TypeList').find_all("a")for a in lst:href='https://www.umeitu.com'+a.get('href') # print(href) 此刻拿到子页面的源代码#拿到子页面的源代码child_page_resp=requests.get(href)#直接通过get拿到属性的值child_page_resp.encoding='utf-8'child_page_text=child_page_resp.text#从子页面中拿到图片的下载路径child_page=BeautifulSoup(child_page_text,"html.parser")#把源代码交给bs4p=child_page.find("div", class_="ImageBody")img=p.find("img")#找到imgprint(img.get("src"))#通过get拿到scr属性的值
5、下载图片
import requestsfrom bs4 import BeautifulSoupimport timeif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://www.umeitu.com/meinvtupian/'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)response.encoding='utf-8'page=BeautifulSoup(response.text,"html.parser")# print(page)lst = page.find("div", class_='TypeList').find_all("a")for a in lst:href='https://www.umeitu.com'+a.get('href') # print(href) 此刻拿到子页面的源代码#拿到子页面的源代码child_page_resp=requests.get(href)#直接通过get拿到属性的值child_page_resp.encoding='utf-8'child_page_text=child_page_resp.text#从子页面中拿到图片的下载路径child_page=BeautifulSoup(child_page_text,"html.parser")#把源代码交给bs4p=child_page.find("div", class_="ImageBody")img=p.find("img")#找到imgscr=img.get("src")#通过get拿到scr属性的值#下载图片img_resp=requests.get(scr)img_name=scr.split("/")[-1]with open("img/"+img_name,mode='wb') as f:f.write(img_resp.content)print("over!",img_name)time.sleep(1)print("all over!!")
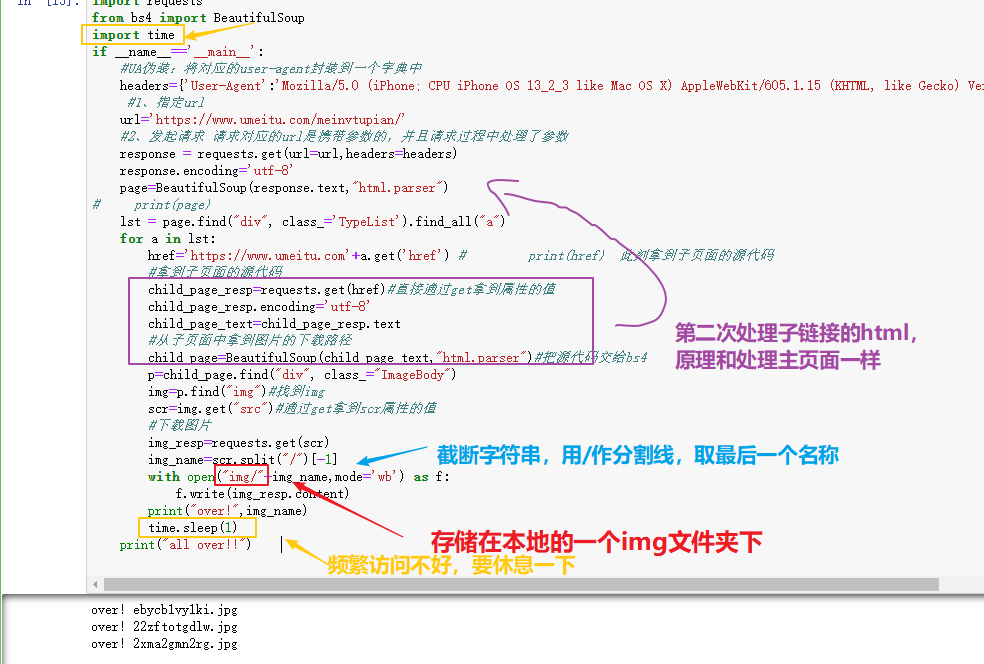
6、爬取结束!

若有收获,就点个赞吧
0 人点赞
