小小的一个demo:
分析:
1、访问豆瓣电影的首页,下拉最底部,右侧有个top250,点击‘全部’查询页面数据;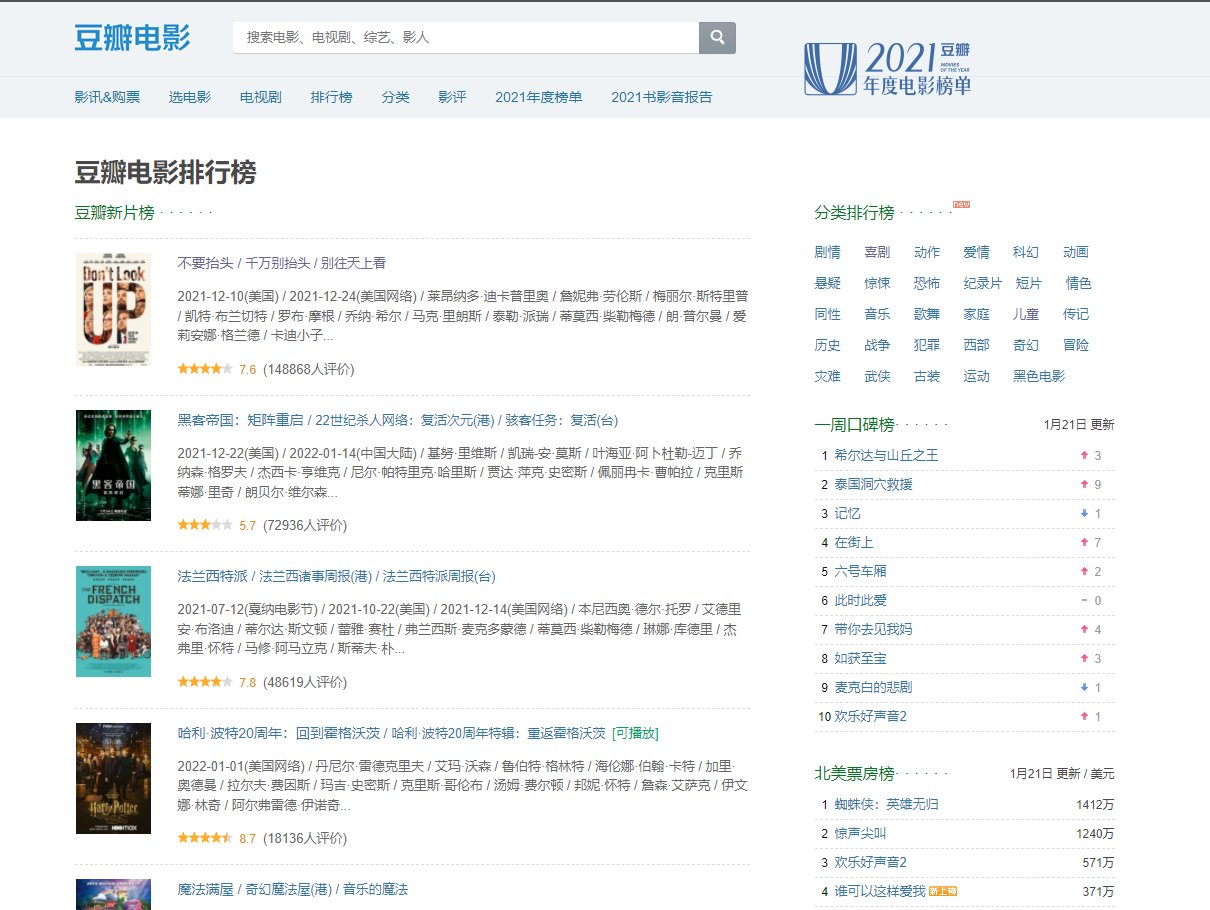
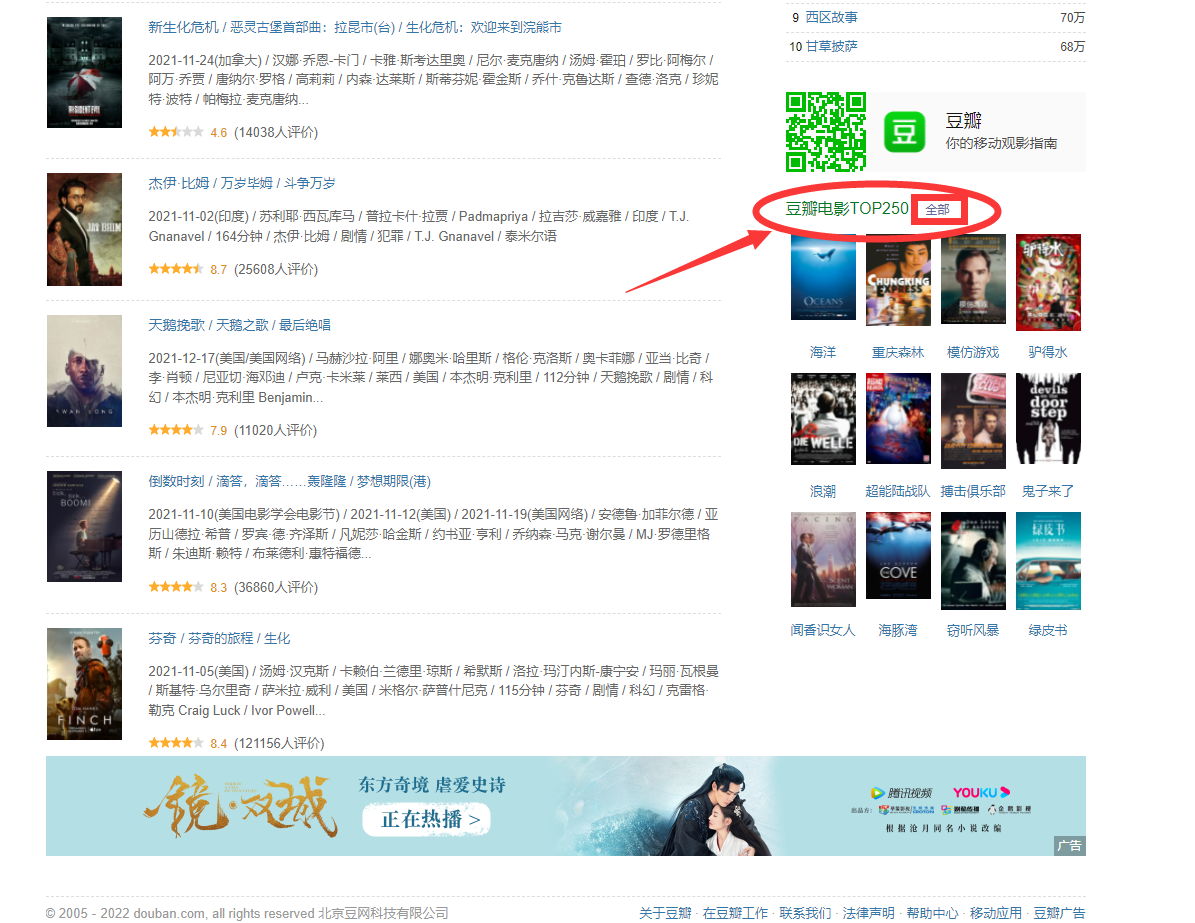
2、要拿到的数据字段有:电影名称、年份、评分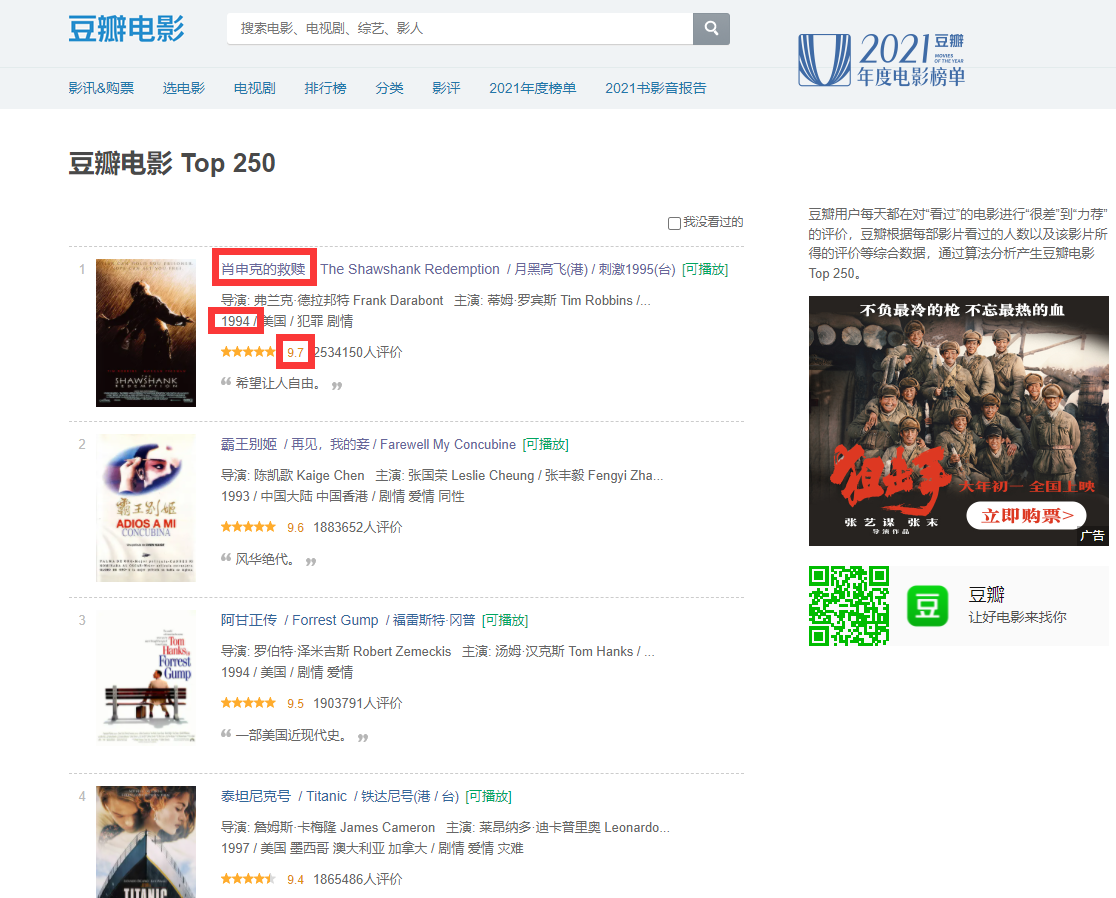
3、先爬取电影名称字段;
#2022-01-25 通过re正则表达式来实现import requestsimport reif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers).textobj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)result= obj.finditer(response) #用迭代器来存储内容for it in result:print(it.group('name'))
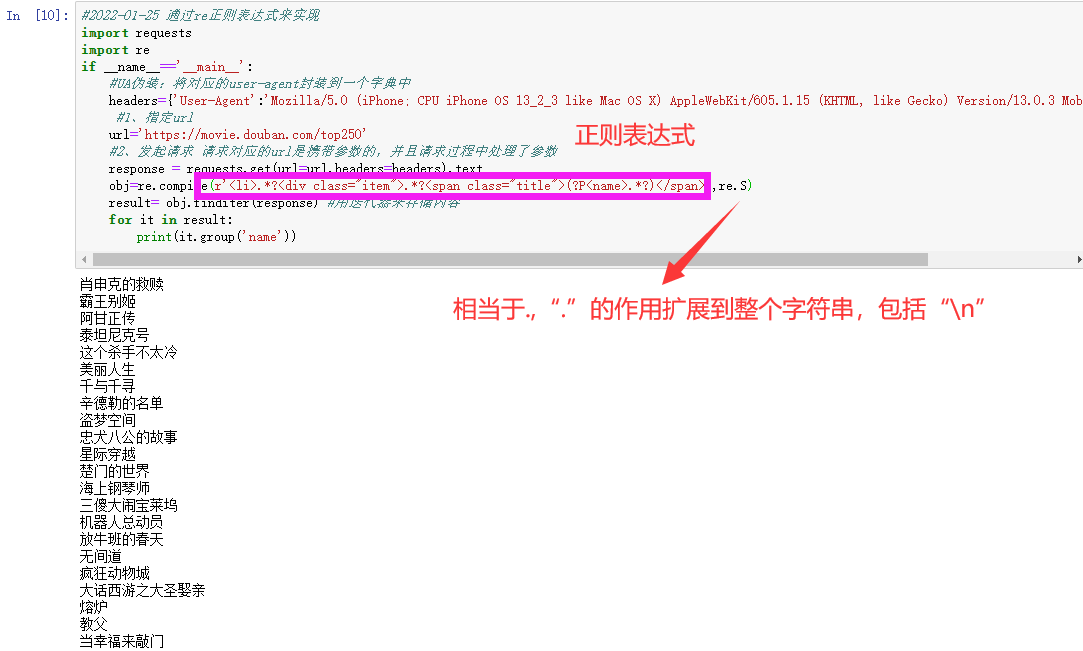
complie函数携带了一个参数re.S,使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
4、抓取年份、评分字段;
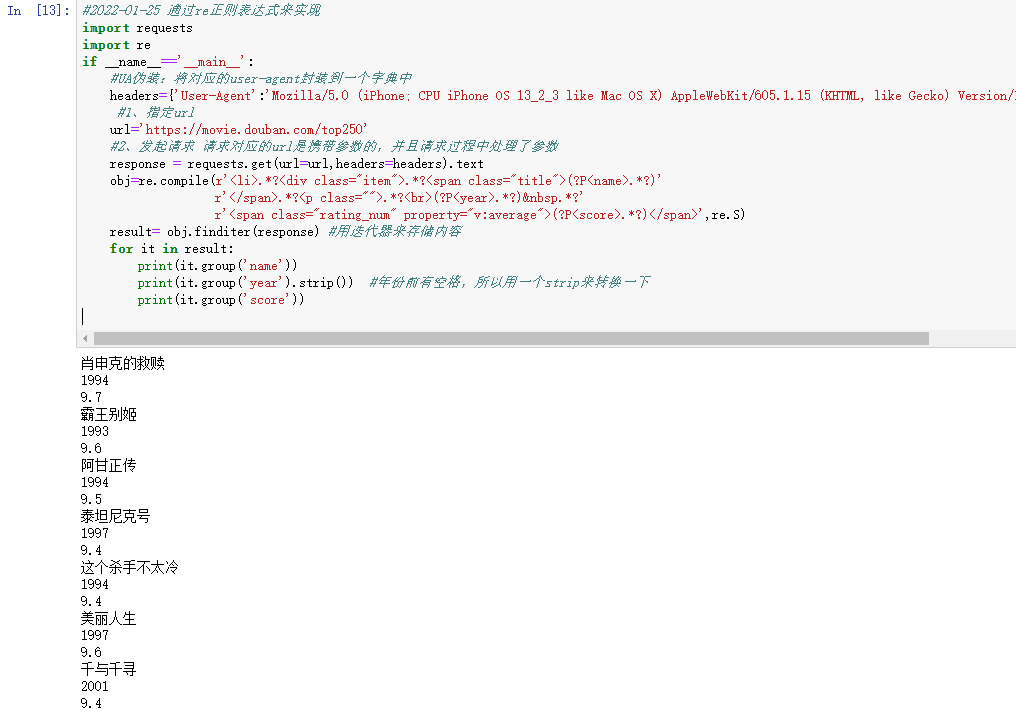
#2022-01-25 通过re正则表达式来实现import requestsimport reif __name__=='__main__':#UA伪装:将对应的user-agent封装到一个字典中headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers).textobj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>',re.S)result= obj.finditer(response) #用迭代器来存储内容for it in result:print(it.group('name'))print(it.group('year').strip()) #年份前有空格,所以用一个strip来转换一下print(it.group('score'))
拓展:
1、改变url的参数来爬取剩下页数的信息;
2、用csv来存储数据,更方便分析;

若有收获,就点个赞吧
0 人点赞
