源代码:
#2022-03-01 xpath爬取豆瓣top250电影排行榜import requestsfrom lxml import etreeimport timefor a in range(10):headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250?start={}&filter='.format(a*25)#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)html=etree.HTML(response.text)divs=html.xpath('//*[@id="content"]/div/div[1]/ol/li')#这个属性里面有双引号,外面就用单引号#print(divs)#拿到每一个divfor div in divs:title=div.xpath('./div/div[2]/div[1]/a/span[1]/text()') [0]#标题 打印出来是一个列表,我们要访问列表里的元素,只有一个元素,所以要加一个[0]year=div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]#年份pj=div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]#评价href=div.xpath('./div/div[2]/div[1]/a/@href')[0]#链接print(title,year,pj,href)time.sleep(3)with open(r"dbmovie.txt","a",encoding="utf-8") as f: #使用with open()新建对象f ,a 表示追加f.write("{},{},{},{}".format(title,year,pj,href))#将列表中的数据循环写入到文本文件中f.write("\n")
分析:
1、访问网站信息
url=https://movie.douban.com/top250
import requestsfrom lxml import etreeheaders={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)print(response.text)
2、解析数据,拿到所有div标签
import requestsfrom lxml import etreeheaders={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)html=etree.HTML(response.text)divs=html.xpath('//*[@id="content"]/div/div[1]/ol/li')#这个属性里面有双引号,外面就用单引号print(divs)
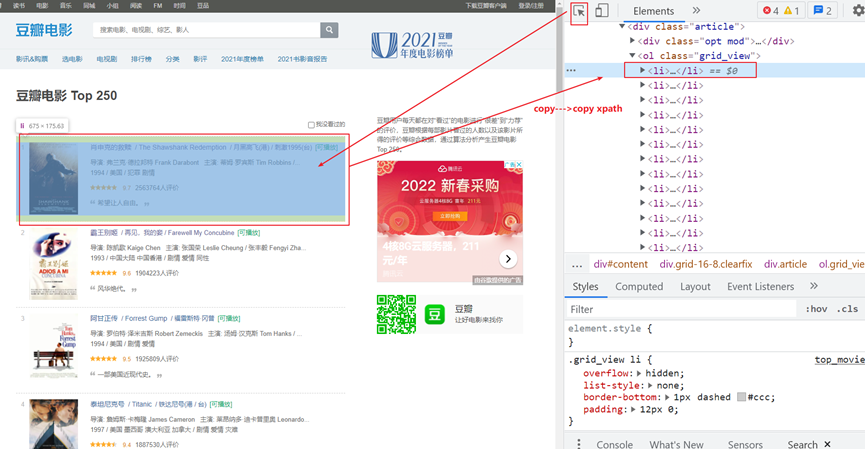
copy得到的xpath是://[@id=”content”]/div/div[1]/ol/li[1]这个是一个div,要所有的div:就是改成: //[@id=”content”]/div/div[1]/ol/li,去掉[1]
3、找到单个div,并查找所有需要的字段
import requestsfrom lxml import etreeimport timeheaders={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250'#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)html=etree.HTML(response.text)divs=html.xpath('//*[@id="content"]/div/div[1]/ol/li')#这个属性里面有双引号,外面就用单引号#print(divs)#拿到每一个divfor div in divs:title=div.xpath('./div/div[2]/div[1]/a/span[1]/text()') [0]#标题 打印出来是一个列表,我们要访问列表里的元素,只有一个元素,所以要加一个[0]year=div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]#年份pj=div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]#评价href=div.xpath('./div/div[2]/div[1]/a/@href')[0]#链接print(title,year,pj,href)time.sleep(3)with open(r"dbmovie11.txt","a",encoding="utf-8") as f:f.write("{},{},{}".format(title,year,pj,href))f.write("\n")
其他字段也是一样的方法:点击按钮,在网页中点击你想查找的部分,在Elements对应代码中点击右键,Copy->Copy Xpath
4、保存数据
import requestsfrom lxml import etreeimport timefor a in range(10):headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}#1、指定urlurl='https://movie.douban.com/top250?start={}&filter='.format(a*25)#2、发起请求 请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,headers=headers)# print(response.text)html=etree.HTML(response.text)divs=html.xpath('//*[@id="content"]/div/div[1]/ol/li')#这个属性里面有双引号,外面就用单引号#print(divs)#拿到每一个divfor div in divs:title=div.xpath('./div/div[2]/div[1]/a/span[1]/text()') [0]#标题 打印出来是一个列表,我们要访问列表里的元素,只有一个元素,所以要加一个[0]year=div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]#年份pj=div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]#评价href=div.xpath('./div/div[2]/div[1]/a/@href')[0]#链接print(title,year,pj,href)time.sleep(3)with open(r"dbmovie.txt","a",encoding="utf-8") as f: #使用with open()新建对象f ,a 表示追加f.write("{},{},{},{}".format(title,year,pj,href))#将列表中的数据循环写入到文本文件中f.write("\n")
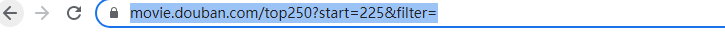
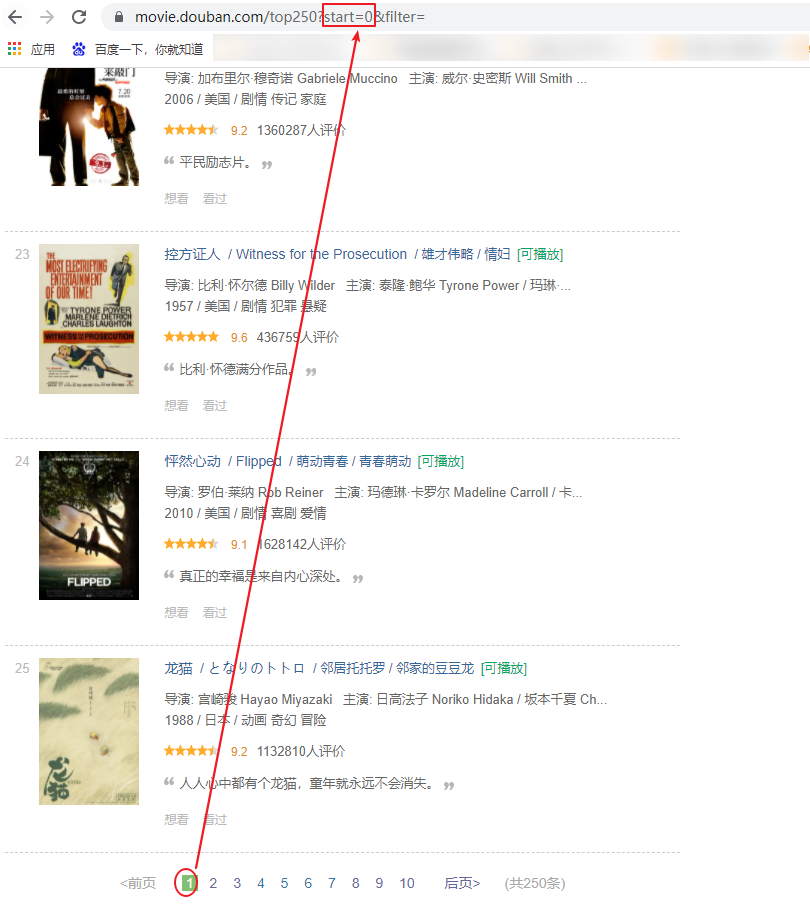
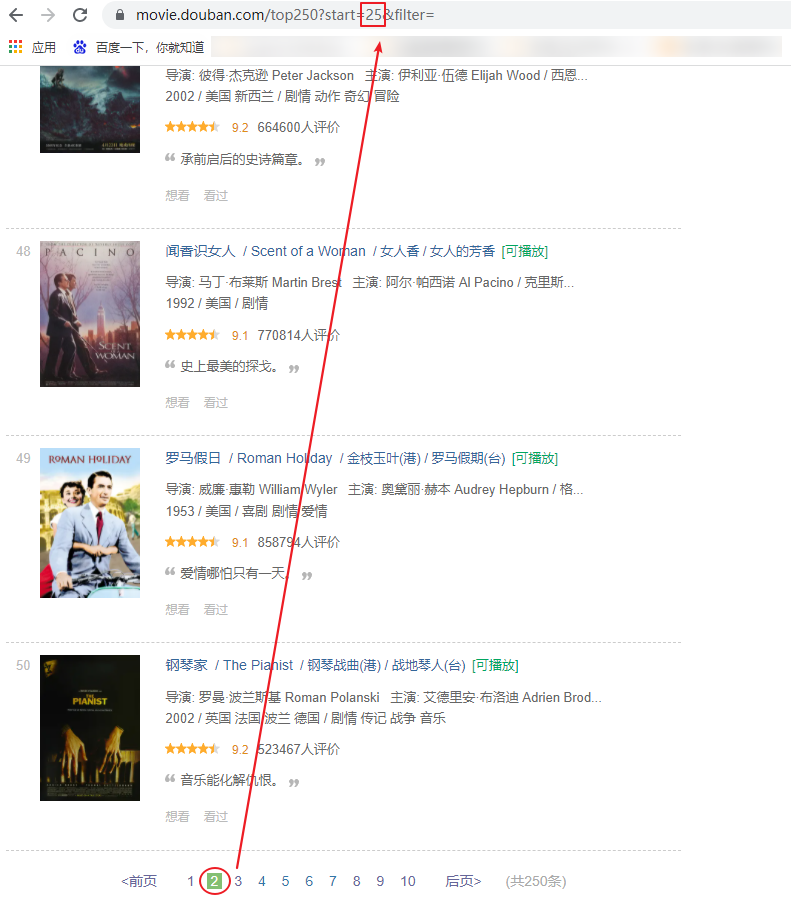
1、分析网站url可得到,25条数据为一页,一共10页,所以用for循环来保存每一页数据: for i in range(10):#一共有10页 url=’https://movie.douban.com/top250?start={}&filter=’.format(a*25)) 2、用with open来打开一个对象文件
5、爬取完成
注意:
1、这种最简单的访问方式,很容易导致ip被封,请谨慎执行!
(执行3-5次,好像没啥问题,执行多了,就封了。。。)
2、可以尝试使用selenium方式来访问

若有收获,就点个赞吧
0 人点赞
