一、前端预渲染的局限
我们知道前端预渲染的原理是:构建打包之后,插件会在本地启动express静态服务,serve打包好的静态资源。然后再启动一个无头浏览器(例如Puppeteer),浏览器从服务器请求网页,网页运行时候会请求首屏接口,用拿到的数据渲染出包含内容的首屏后,无头浏览器截屏并替换掉原来的html。
但是在单页应用中存在一个问题,前端路由切换时候,还是会请求接口,而不会加载预渲染好的html,例如预渲染index.html和about.html,但是从index.html跳转about.html时候,如果是前端路由,不会从服务器请求about.html,而是加载about组件,那还是会请求接口,从而可能带来界面渲染慢的情况。
二、解决方案:数据预下载
怎么解决这个问题呢?
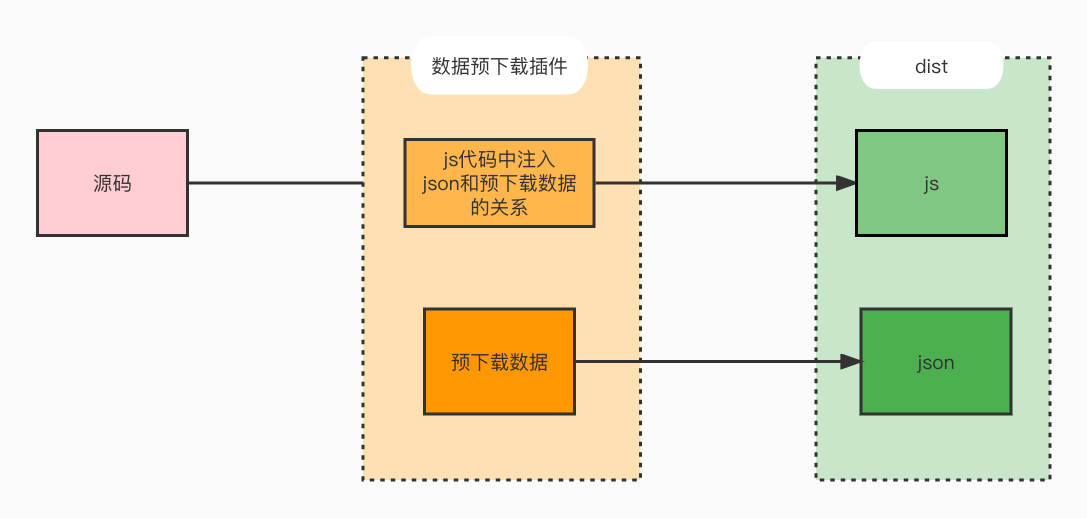
在优化灵题库(https://www.lingtiku.com)页面加载时候,我想到一个简单的办法,就是仿照前端预渲染的思路,在构建阶段就把一些数据预下载,下载之后保存在一个json文件里,json文件放到前端静态资源目录中。然后前端发起请求时候,用axios拦截预下载的请求,改成请求静态的json数据。
这样会带来两个好处
- 减小服务器压力,不需要读数据库和缓存
- 对于json数据,初始读取一次,后续都可以读浏览器的缓存,速度非常快。而且初始请求因为是静态资源,速度也会比接口更快一些。
写一个rollup插件,来实现数据预下载的功能,这个插件需要做以下事情
- 根据插件配置,获取所有的需要预下载的数据接口和接口下载完成保存成的文件名字。还有打包构建输出的静态资源目录。
- 在打包输出文件阶段,请求接口并将数据保存到指定文件名的json文件,并将文件放到静态资源目录。
- 将请求接口和json文件名的映射关系注入到代码中,以便axios可以拦截处理。
在rollup插件中,需要实现transform钩子,来将配置的json文件名和接口的映射注入到代码中;还要实现写bundle构造,在这个阶段请求数据并把json文件输出到构建目录中。
插件使用request库来请求数据。
另外需要注意,为了保证数据改变时候可以及时更新,需要给json加一个版本号,这里的版本号简单地设置成当前时间,其实使用内容的md5更合适一些。
插件代码如下:
// preload-data-plugin.jsimport fs from 'fs';import path from 'path';import request from 'request';import {promisify} from 'util';import crypto from 'crypto';const writeFileAsync = promisify(fs.writeFile);const version = String(Date.now());const preloadData = options => {const {map, staticDir} = options;Object.entries(map).forEach(([name, urlOrParams]) => {request(urlOrParams, (err, res, body) => {writeFileAsync(path.join(staticDir, `${name}_${version}.json`), body);});});};const preloadDataPlugin = (options = {}) => ({name: 'preloadDataPlugin',transform: (code, id) => {const map = {};Object.entries(options.map).forEach(([key, value]) => {map[`${key}_${version}`] = value;});return {code: code.replace(/__PRELOAD_DATA_MAP__/g, JSON.stringify(map))}},writeBundle: () => {try {preloadData(options)}catch (e) {console.error(e)}}});export default preloadDataPlugin;
rollup的插件配置如下
// rollup.config.jsimport preloadDataPlugin from './rollup-plugin/preload-data-plugin';export default {// ...other configplugins: [preloadDataPlugin({staticDir: path.resolve(__dirname, 'dist'),map: {'main': 'https://api.example.com/all','quiz_1': 'https://api.example.com/quiz/find?id=1','quiz_2': 'https://api.example.com/quiz/find?id=2','quiz_3': 'https://api.example.com/quiz/find?id=3',}}),]};
最终会在dist目录生成几个文件
├── main_1651497197552.json├── quiz_1_1651497197552.json├── quiz_2_1651497197552.json└── quiz_3_1651497197552.json
axios拦截代请求,替换成请求的json码如下
// http.jsimport axios from 'axios';const parseURL = url =>url.split('?')[1].split('&').filter(Boolean).reduce((result, paramPair) => {const [key, value] = paramPair.split('=');result[key] = value;return result;}, {});axios.interceptors.request.use(function (config) {Object.entries(__PRELOAD_DATA_MAP__).some(([name, url]) => {const query = parseURL(url);const isParamsEqual = !config.params || Object.entries(query).every(([key, value]) => {return config.params[key] == value;});// 接口和参数都匹配,则替换if (url.includes(`${config.baseURL || ''}${config.url}`) && isParamsEqual) {config.baseURL = '';config.url = `/${name}.json`;config.params = {};}});return config;},function (error) {return Promise.reject(error);});
再说另一个问题:如果数据很大,及时很快请求到,但是长列表渲染也会很慢。
目前灵题库的解决方法是通过懒加载方式解决,先只渲染前20条。后面的数据渲染过程中加loading,以提供好的交互体验。当然这种问题通过分页来解决是最优雅的方案。
三、后续
- 目前只是简单地支持get请求,可以考虑扩展一下,支持post请求。
- 安全方面,为了避免数据被轻易爬取,可以考虑让插件支持将请求数据base64加密,然后前端解密,这样增加了爬数据的成本
- 容错方面,当请求json失败或者json数据解析失败时候,要fallback到原接口。

若有收获,就点个赞吧
0 人点赞
