1.前言
高可用有两个含义:一是数据尽量不丢失,二是服务尽可能提供服务。 AOF 和 RDB 保证了数据持久化尽量不丢失(aof与rdb原理可看核心篇二-数据持久化 - 掘金 (juejin.cn)](https://juejin.cn/post/7045978572158140423))),而主从复制就是增加副本,一份数据保存到多个实例上。哨兵则是当集群与节点宕机,则能够进行故障的自动转移,持续提供服务。
2. 主从
在redis中,可以通过执行replicaof(Redis 5.0之前使用 slaveof)命令形成主库和从库的关系或者在配置文件配置replicaof选项,让一个服务器去复制另外一个服务器,被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则被称为从服务器(slave)。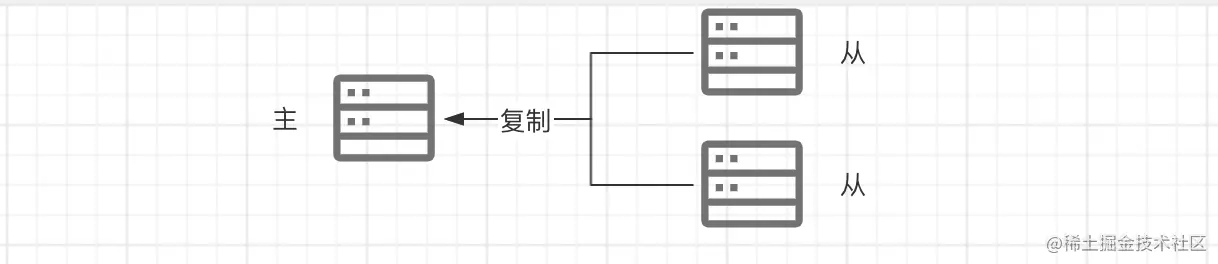 主从之间的关系:
主从之间的关系:
- 主服务可以有多个从服务器,也可以没有从服务,通常一个redis服务什么都不配,默认就为master
- 从服务器只能有一个master
2.1 主从关联
redis服务默认都为master,配置主从关系,可以通过配置主节点信息开启主从复制,有如下三种方式:
配置文件:在从服务器的配置文件添加如下配置
replicaof <masterip> <masterport>
启动参数:redis-server 启动命令后面加入如下参数: —replicaof masterip masterport
客户端命令:连接上redis之后,执行命令:replicaof masterip masterport,则该 Redis 实例成为从节点
2.1.1 演示
客户端连上之后,执行如下命令:

- 观察主机节点日志:
 可以看到,主节点从主从关联的时候,会执行BGSAVE命令,该命令在(redis核心篇(二)-数据持久化 - 掘金 (juejin.cn))有详细描述,不熟悉的小伙伴可移步查看。
可以看到,主节点从主从关联的时候,会执行BGSAVE命令,该命令在(redis核心篇(二)-数据持久化 - 掘金 (juejin.cn))有详细描述,不熟悉的小伙伴可移步查看。
2.2 主从数据一致性
主从关系,既然涉及多个节点,那么在多个节点之间,必然会涉及到节点与节点之间数据同步延迟问题,也就是数据一致性方案;那redis对于数据一致性的方案又是怎么权衡的呢?对于多个节点之间的数据应该怎么同步,直接上图,我大致画了三个方向的解法;有其它解法的小伙伴,可在评论去留言哦: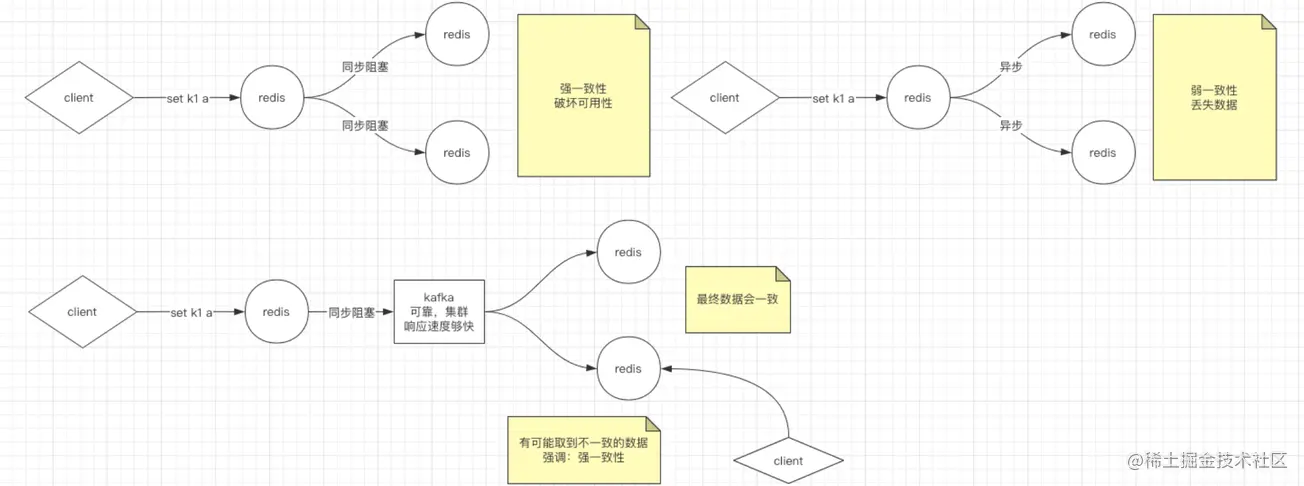
- 强一致性的解决方案:节点与节点之间的数据同步采用完全同步的方式,所有节点写完数据才给客户端响应。此种解法在高性能和高可靠的权衡上,偏向了可靠;虽然保证了数据可靠,但也影响了性能,特别是在多个从节点的时候尤为明显。
- 弱一致性的解决方案:节点与节点之间的数据同步完全采用异步,此种解法是在高性能和高可靠的权衡上,偏向于高性能,性能提高了,数据的可靠性得不到保障,易丢失数据。
- 最终一致性的解决方案:master将消息丢入异步队列(或缓冲区),通过异步线程来消费队列(缓冲区)的数据,以此来同步节点之间的数据,在高性能和高可靠的权衡上互相做了个折中,其实这个也是来源于Base理论,BASE是指基本可用(Basically Available)、柔性状态(Soft State)、最终一致性(Eventual Consistency)
其实对于大多数开源产品,在高性能和高可靠的权衡上,并没有给出特定的一种解决方案,通常是把决定权交给使用者,像kafka的ack机制,通过设置是0还是1或者-1,使用者根据自己的业务场景,自己决定是要消息的高吞吐率还是消息的高可靠;但对于我们的redis来说,并没有提供如此灵活配置,其默认使用异步复制,弱一致性的解法,因为它追求的是极致的高性能。
2.3 主从同步原理
在redis的主从复制实现上,有两个不同的实现版本:2.8版之前使用的sync命令,2.8及2.8之后的版本,使用的psync命令,本篇,将分别介绍这两个命令的实现。
主从复制主要分为两个操作,数据同步和命令传播
- 数据同步:主要将从服务器的状态同步更新至主服务器所在的状态。
- 命令传播:主要作用于当主服务器所在状态被更改,导致主从数据不一致的情况时,让主从服务器的状态重回一致。
数据同步可分为2种情况:
- 首次同步:从节点首次连接到master的数据同步
- 断开重连:从节点断开后重新连接到master
2.3.1 sync
2.3.1.1 首次同步
主从库第一次复制过程大体可以分为 3 个阶段:
1)连接建立阶段(即准备阶段);
2)主库同步数据到从库阶段;
3)发送同步期间新写命令到从库;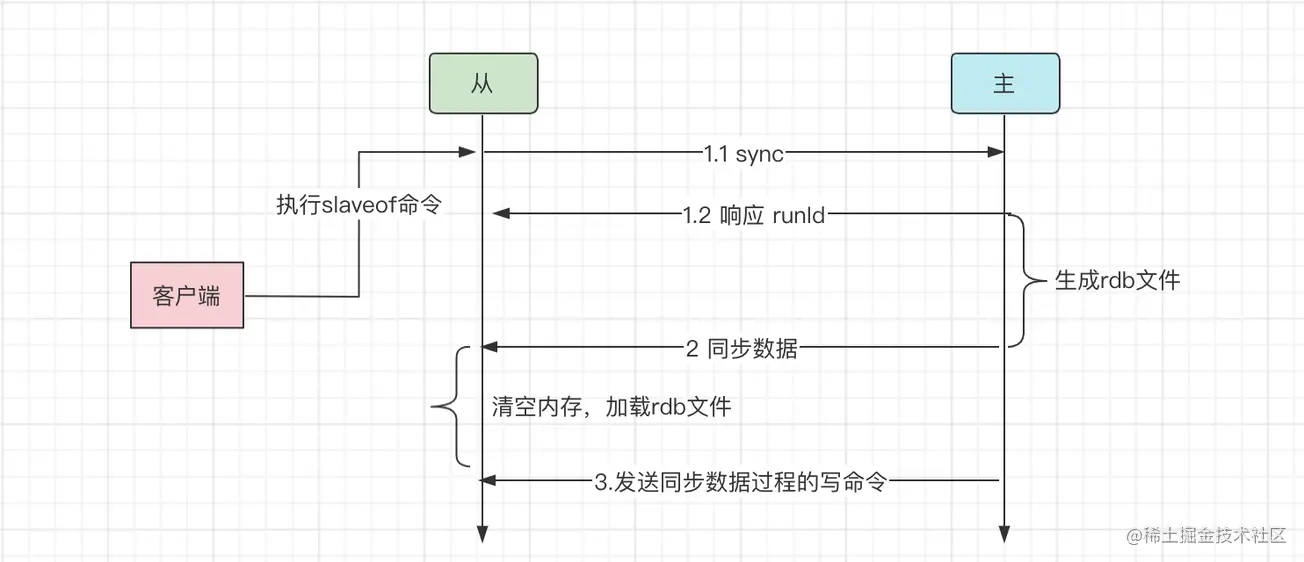
- 链接建立阶段:该阶段的主要作用是在主从节点之间建立连接,为数据全量同步做好准备。从库会和主库建立连接的时候,从库执行slaveof并发送sync命令并告诉主库即将进行同步,主库确认回复后,主从库间就开始同步了。
- 第二阶段:master执行bgsave命令生成RDB文件,并将文件发送给从库,同时主库为每一个 slave 开辟一块缓冲区记录从生成RDB文件开始收到的所有写命令;从库收到 RDB 文件后保存到磁盘,并清空当前数据库的数据,再加载 RDB 文件数据到内存中
- 第三阶段:从节点加载RDB完成后,master将缓冲区的数据发送到从节点,Slave 接收并执行,从节点同步至主节点相同的状态。
通过上面的过程不难看出,当主从同步的时候,如果此时业务并发量很高,导致写命令qps飙升,很容易造成从节点在载入rdb文件过程中,缓冲区容量过小,导致主从同步失败,重新进行同步;容易形成bgsave和rdb重传操作的无限循环。
2.3.1.2 断开重连
在2.8版本之前,同步所用的sync命令,没有很好的处理断线重连的情况,当主从断开发生再次重连的时候;所执行的步骤同第一次主从同步过程,需要进行全量复制,过程同首次同步,此处就不再说明。
参考
https://redis.io/docs/manual/sentinel/#sentinel-as-a-distributed-system
https://juejin.cn/post/7051129092908777503
https://juejin.cn/post/6844904097116585991

若有收获,就点个赞吧
0 人点赞
