概述
前面我们讲解Zookeeper集群环境的搭建,最终整个集群中选举出一个作为Leader, 那它是通过什么方式选举出来的,又是何时会进行Leader的选举?
集群中的角色
Zookeeper集群中公共有三种角色,分别是leader,follower,observer。
| 角色 | 描述 |
|---|---|
| leader | 主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。 |
| follower | 子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并拥有投票权。 |
| observer | 次级子节点,又名观察者。用于读取数据,与follower区别在于没有投票权,不能被选为主节点。并且在计算集群可用状态时不会将observer计算入内。 |
关于observer的说明:
如果集群配置中加上observer后缀,那么该节点只用于提供读取数据服务,不参与选主,也没有投票权。配置如下:
server.4=127.0.0.1:2888:3888:observer
般生产上不会配置observer,因为observer并没有选举权,可以理解为observer是一个临时工,不是正式员工,没法获得晋升。除此之外,它和follower的功能是一样的,那它有什么作用呢,什么时候需要observer呢?
因为zk一般读的请求会大于写。当整个集群压力过大时,我们可以增加几个临时工observer来获得性能的提升。在不需要的时候的时候,可以随时撤掉observer。
选举关键参数说明
在整个选举Leader的过程中需要依赖一些重要的参数,我们先提前来说明一下。
SID
服务器id, 用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和集群搭建时myid一致。
ZXID
事务id, 用来标识服务器状态的变更,Zookeeper上任何数据节点的变更都会导致zxid递增。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
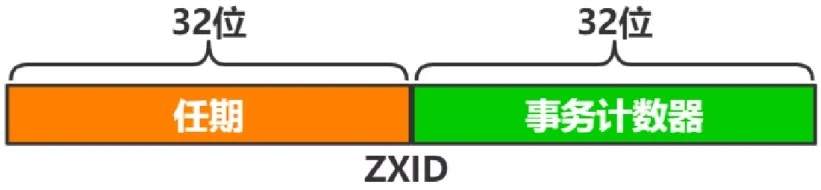
ZXID 由两部分组成:
- 任期:完成本次选举后,直到下次选举前,由同一 Leader 负责协调写入;
- 事务计数器:单调递增,每生效一次写入,计数器加一。
ZXID是一个长度为64位的数字,其中低32位是按照数字来递增,任何数据的变更都会导致低32位数字简单加1。高32位是leader周期编号,每当选举出一个新的Leader时,新的Leader就从本地事务日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次选举新的Leader后,保证了ZXID的唯一性而且是保证递增的。
选举过程
Zookeeper在下面的两种场景下会进入 Leader 选举, 他们选举的过程是不一样的。
- 服务器集群第一次启动。
- 服务器运行期间 Leader 故障,非第一次启动
选举状态说明:
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
我们以5个Zookeeper节点作为例子,讲解下Leader选举的过程。
第一次启动选举
Zookeeper集群第一次启动,没有历史数据的情况下,它首先会进行一次选举。
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
- 服务器2启动,发起一次选举。服务器1和2会投自己1票,但此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时,服务器1是0票,服务器2是2票,不够半数以上(3票),服务器1、2状态保持为LOOKING;
- 服务器3启动,发起一次选举。服务器 1、2、3 先投自己一票,然后因为服务器 3 的 id 最大,两者更改选票投给为服务器 3。此时服务器 1 为 0 票,服务器 2 为 0 票,服务器 3 为 3 票。此时服务器 3 的票数已经超过半数(3 票),服务器 3 当选 Leader。服务器 1,2 更改状态为 FOLLOWING,服务器 3 更改状态为 LEADING。
- 服务器4启动,发起一次选举,此时服务器 1,2,3 已经不是 LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器 3 为 3 票,服务器 4 为 1 票。此时服务器 4 服从多数,更改选票信息为服务器 3.服务器 4 并更改状态为 FOLLOWING。
- 服务器 5 启动,发起一次选举,与服务器 4 一样投票给 3,此时服务器 3 一共 5 票,服务器 5 为 0 票。服务器 5 并更改状态为 FOLLOWING。
小结:Zookeeper集群第一次启动的时候,选举Leader主要根据SID决定。
非第一次启动
当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 ZooKeeper 集群将暂停对外服务,会触发新一轮的选举。此时,如果服务器3,也就是Leader节点发生宕机,那它的选举流程是如何的呢?
此时Zookeeper各个节点的SID, ZXID和Epoch如下:
| 服务器 | SID | ZXID |
|---|---|---|
| Server1 | 1 | 8 |
| Server2 | 2 | 8 |
| Server3 | 3 | / |
| Server4 | 4 | 9 |
| Server5 | 5 | 7 |
- 状态变更。Leader 故障后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
- 每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同。在第一轮投票中,Server1、Server2、Server4、Server5都会投自己,产生投票(1, 8),(2, 8),(4, 9), (5,7)然后各自将投票发送给集群中所有机器。
- 接收来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下:
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
以Server1为例,它的投票为(1,8),接收到其他选票为(2, 8),(4, 9), (5,7),由于Server4的ZXID最大,于是更新自己的投票为(4,9),然后重新投票。最终,Server4将成为Leader。
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息。
- 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
总结
Zookeper在第一启动和Leader节点挂掉的情况下会进行选举,选举过程取决于ZXID和SID, ZXID越大,权重越大,在同等ZXID下,SID越大,权重越大。参考
https://segmentfault.com/a/1190000040777791
https://www.cnblogs.com/leesf456/p/6107600.html

若有收获,就点个赞吧
0 人点赞
