概述
Zookeeper是一个分布式协调服务,提供了分布式数据一致性的解决方案。目前很多开源框架技术背后都有ZooKeeper的身影,比如kafka, hbase等。
Zookeeper基础知识主要分为三大块,数据结构, Watch监控,ACL权限控制。基于这些特点可以实现数据的发布/订阅,软负载均衡,命名服务,统一配置管理,分布式锁,集群管理等等。
数据模型
什么是数据模型呢?就是指Zookeeper创建和处理数据存储的逻辑结构。
Zookeeper创建的数据模型是树状结构,类似Unix的文件系统,类似下图。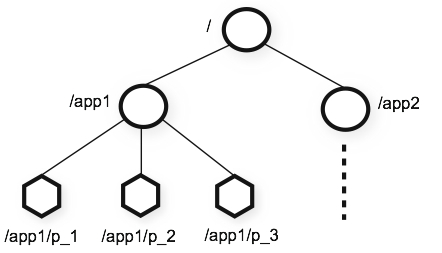
- 有一个固定的根节点(/)
- 根节点下可以创建子节点,子节点下可以继续创建下一级节点
- 每一层级用斜杆(/)分隔
- 查找某个节点只能用绝对路径方式查询(/app1/p_1),不能用相对路径
Znode节点分类
上面数据中的每一个节点叫Znode, 默认情况下最大存储1M的数据,Znode根据特性分为下面三类:持久节点
特点:一旦将节点创建为持久系欸但,该数据节点一直会存储在Zookeeper服务器上,即使创建该节点的客户端和服务端会话关闭了,该节点也不会删除。如果想要删除持久节点,就要显示调用delete函数删除。
命令:create /persistent_node临时节点
特点:如果创建的是临时节点是,当创建该临时节点的客户端会话因超时或发生异常而关闭时,该节点也相应在 ZooKeeper 服务器上被删除,也可以调用delete主动删除临时节点。
命令:create -e /ephemeral_node mydata有序节点
特点:我们在创建有序节点时,ZooKeeper 服务器会自动使用一个单调递增的数字作为后缀,追加到我们创建节点的后边。这个序号对于父 znode 是唯一的。计数器的格式为 %010d - 即 10 位数字和 0(零)填充(计数器以这种方式格式化以简化排序),即“0000000001”。
例如一个客户端创建了一个路径为 works/task- 的有序节点,那么 ZooKeeper 将会生成一个序号并追加到该节点的路径后,最后该节点的路径为 works/task-0000000001。
有序节点属性可以和持久或者临时节点共存,意味着有持久有序节点,临时有序节点。
命令:创建持久有序节点create -s /persistent_sequential_node mydata,
创建临时有序节点create -s -e /ephemeral_sequential_node mydata容器节点
3.6.0版本新加
特点: 服务端会定期扫描这些节点,当该节点下面没有子节点时(或其他条件时)服务端会自动删除节点
命令:create -c /container_node mydataTTL节点
3.6.0版本新加
特点:需要额外配置才能启用,基本和容器相同,当超过 TTL 时间节点下面都没有再创建子节点时会被删除,但是当创建子节点会重置该超时时间。
命令:create -t 3000 /ttl_node mydataZnode节点属性
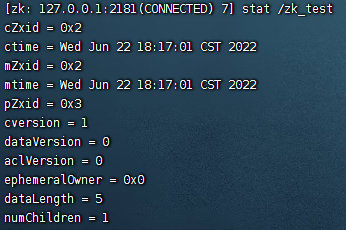
每个Znode节点都有属于自己的状态属性,通过执行stat /zk_test查看节点的状态信息。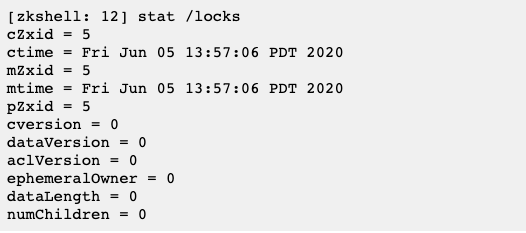
| 属性名 | 说明 |
|---|---|
| czxid | 表示该数据节点被创建时的事务ID |
| mzxid | 表示该节点最后一次被更新时的事务ID |
| pzxid | 表示该节点的子节点列表最后一次被修改时的事务ID |
| ctime | 表示该节点的创建时间 |
| mtime | 表示该节点最后一次被更新的时间 |
| version | 数据节点的版本号 |
| cversion | 子节点的版本号 |
| aversion | 节点的ACL版本号 |
| ephemeralOwner | 创建该临时节点的会话SessionId, 如果该节点时持久节点,那么这个属性时0 |
| dataLength | 数据内容的长度 |
| numChildren | 当前节点子节点的个数 |
安装使用
单机版安装
- 官网下载最新的安装包,https://zookeeper.apache.org/releases.html
- 创建配置conf/zoo.cfg
tickTime=2000dataDir=/var/lib/zookeeperclientPort=2181
- tickTime:ZooKeeper 使用的基本时间单位,以毫秒为单位。它用于做心跳,最小会话超时将是 tickTime 的两倍。
- dataDir:存储内存数据库快照的位置。
- clientPort:监听客户端连接的端口。
启动
bin/zkServer.sh start
查看日志
tail logs/zookeeper-root-server-template.out是否启动成功

连接使用
- 连接
bin/zkCli.sh -server 127.0.0.1:2181
- 在 shell 中,键入help以获取可以从客户端执行的命令列表
- 创建持久化节点zk_test, 值为alvin

- 查看目录

- 获取节点数据信息

- 查看节点属性信息
- 删除节点

全量的命令参考:
https://zookeeper.apache.org/doc/current/zookeeperCLI.html
实战案例
我们现在利用上面学到的数据模型和节点的特性,用一个案例来加深我们的理解。
场景
一个购物网站,只剩下一部IPhone13, 周杰伦搜索到了准备下单购买,这时候王力宏也查询到了并且提交购买,如果不做任何处理,那么一件商品会被卖两次,出现超卖的情况。那么利用Zookeeper学的知识该如何解决呢?
方案
我们可以通过加锁的方式,比如周杰伦进行操作的时候,对这个商品锁定。实现加锁的方式有两种,悲观锁和乐观锁。
悲观锁
悲观锁认为进程对临界区的竞争总是会出现,为了保证进程在操作数据时,该条数据不被其他进程修改。数据会一直处于被锁定的状态。
我们假设一个具有 n 个进程的应用,同时访问临界区资源,我们通过进程创建 ZooKeeper 节点 /locks 的方式获取锁。
线程 a 通过成功创建 ZooKeeper 节点“/locks”的方式获取锁后继续执行,如下图所示: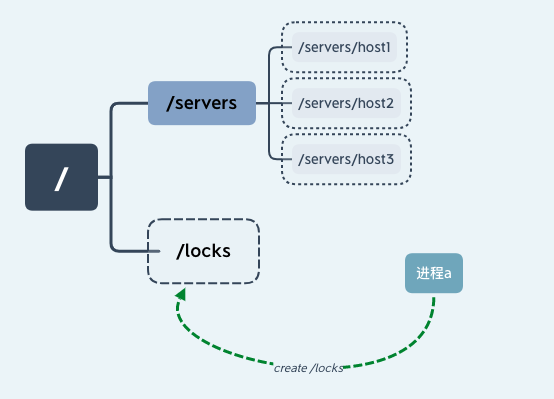
这时进程 b 也要访问临界区资源,于是进程 b 也尝试创建“/locks”节点来获取锁,因为之前进程 a 已经创建该节点,所以进程 b 创建节点失败无法获得锁。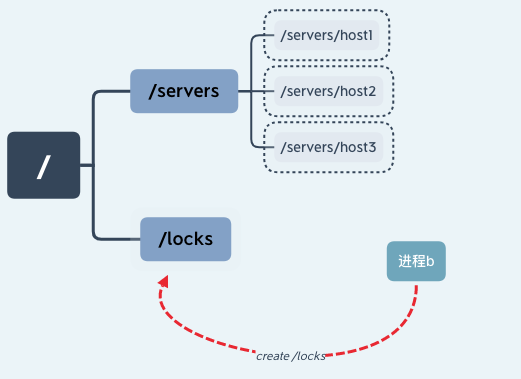
这样就实现了一个简单的悲观锁,不过这也有一个隐含的问题,就是当进程 a 因为异常中断导致 /locks 节点始终存在,其他线程因为无法再次创建节点而无法获取锁,这就产生了一个死锁问题。针对这种情况我们可以通过将节点设置为临时节点的方式避免。并通过在服务器端添加监听事件来通知其他进程重新获取锁。
乐观锁
乐观锁认为,进程对临界区资源的竞争不会总是出现,所以相对悲观锁而言。加锁方式没有那么激烈,不会全程的锁定资源,而是在数据进行提交更新的时候,对数据的冲突与否进行检测,如果发现冲突了,则拒绝操作。
在 ZooKeeper 中的 version 属性就是用来实现乐观锁机制中的“校验”的,ZooKeeper 每个节点都有数据版本的概念,在调用更新操作的时候,假如有一个客户端试图进行更新操作,它会携带上次获取到的 version 值进行更新。而如果在这段时间内,ZooKeeper 服务器上该节点的数值恰好已经被其他客户端更新了,那么其数据版本一定也会发生变化,因此肯定与客户端携带的 version 无法匹配,便无法成功更新,因此可以有效地避免一些分布式更新的并发问题。
悲观锁和乐观锁具体的代码实现在后面的文章中一一和大家展示。
参考
https://zookeeper.apache.org/doc/r3.8.0/zookeeperStarted.html
https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/ZooKeeper%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B8%8E%E5%AE%9E%E6%88%98-%E5%AE%8C/01%20ZooKeeper%20%E6%95%B0%E6%8D%AE%E6%A8%A1%E5%9E%8B%EF%BC%9A%E8%8A%82%E7%82%B9%E7%9A%84%E7%89%B9%E6%80%A7%E4%B8%8E%E5%BA%94%E7%94%A8.md

若有收获,就点个赞吧
0 人点赞
