事件分析
分组的返回逻辑
使用筛选的时间窗口期中,最新的数据周期(若按天查看,则为最新一天),第一个指标(若同时查看 A,B 两个指标,则使用 A 指标)的分组值由大到小进行排序。
- 如:3月1日-3月11日,「支付订单金额」和「支付事件人数」两个指标,按照「国家」分组。
- 返回的分组排序为:3月1日-3月11日的支付订单金额汇总值,按照国家分组由多到少
其中,显示设置也是使用上述排序结果进行展示。
为什么图表中的图例顺序和下面的表格对不上?
- 图表中的图例顺序和表格中的顺序无关。图表中的图例顺序是依赖「显示设置」(在「显示设置」中可手动勾选显示的分组)。
session 分析
session 构成推演
- 取出行为序列(其中 A、B、C、D、E是事件)

- 根据切割规则进行切割

session 的计算指标
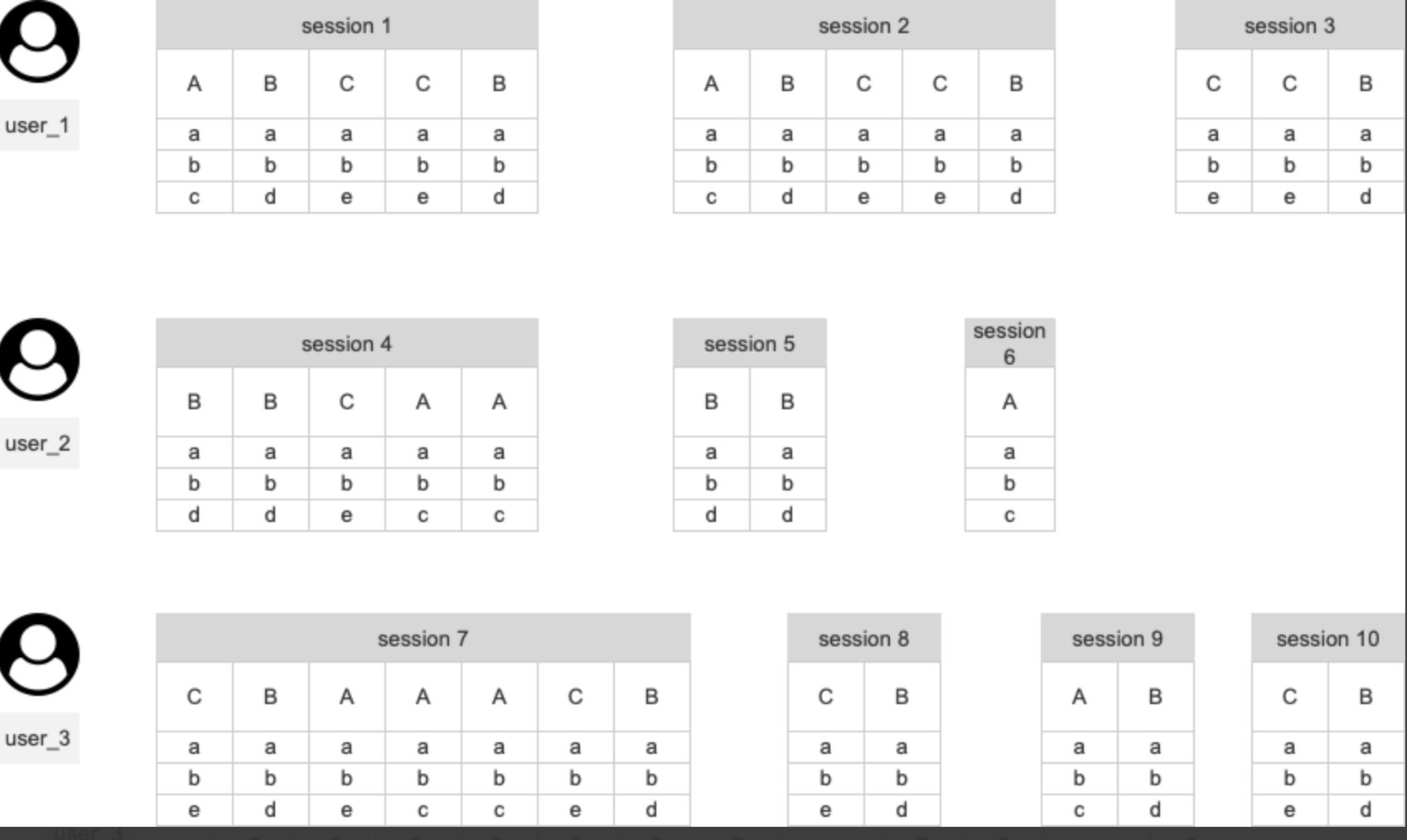
将整个 session 作为一个整体进行分析
- session 总次数:切割出来的 session 个数
- 触发用户数:存在 session 的用户数
- 人均 session 次数:session 总次数 / 触发用户数
- 跳出率:session 中事件发生次数为 1 的 session 数量 / session 总次数
- session 时长:session 末事件发生时间 - session 首事件发生时间,若 session 中仅有一个事件,则 session 时长为0,但计算均值时不作为分母参与计算
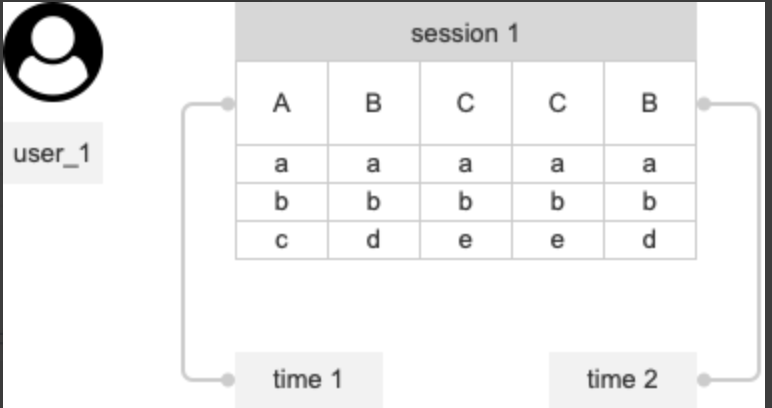
- session 深度:session 中的事件个数

- session 的属性:session 中的首个事件的属性作为该 session 的属性

使用 session 中的某个事件进行分析
假定使用事件C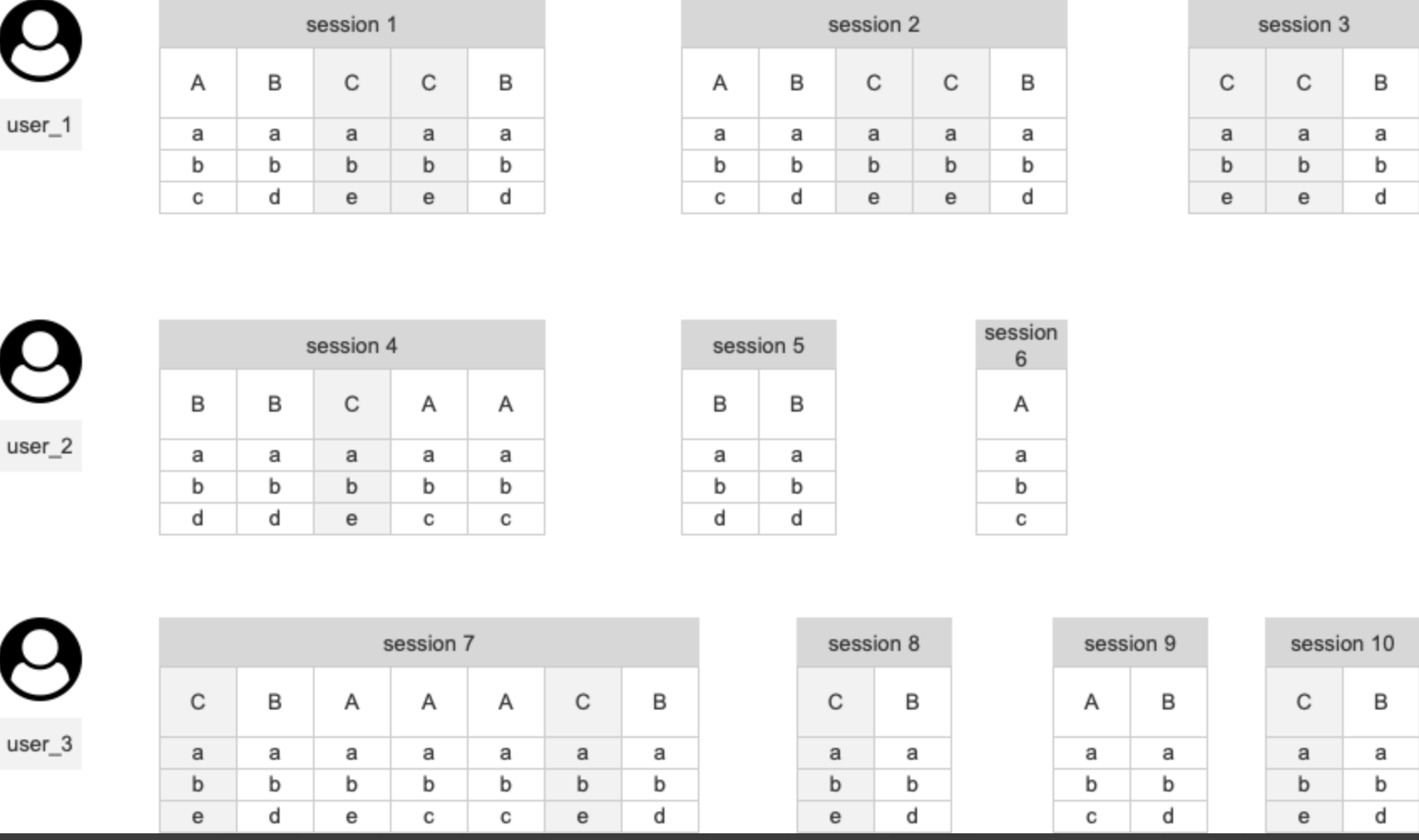
- session 总次数:切割出来的包含某个事件的 session 个数
- 触发用户数:存在包含某个事件的 session 的用户数
- 人均 session 次数:session 总次数 / 触发用户数
- 退出率
- 任意事件退出率:session 总次数 / session 中所有事件的发生次数
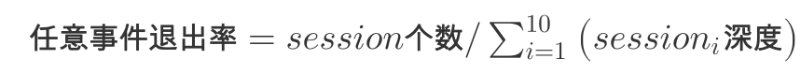
- 指定事件的退出率:指定事件作为 session 的最后一个事件的个数 / 指定事件的发生次数

- session 内的事件时长(跳出/退出事件不计算事件时长)
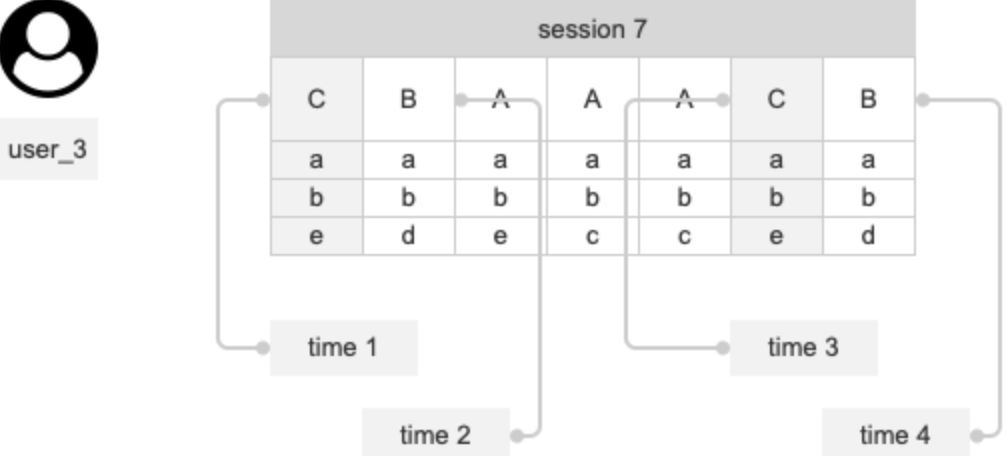
session 内的事件次数
窗口期:第一步至最后一步的时间间隔

内筛选:发生在漏斗的数据匹配时,根据筛选条件,返回一个匹配成功的漏斗
外筛选:在返回的匹配成功的漏斗基础上,根据属性进行分组或筛选
分组
- 任意步骤分组:在用户的行为序列中,第一个不为空的分组值
- 某一步骤分组:有效的转化中,该步骤的所在分组
筛选
- 任一步骤筛选:在用户的行为序列中,第一个不为空的属性筛选
-
漏斗的匹配规则
目的:漏斗匹配事件 A、B、D,并且 A、B、D 的事件属性值均是 i 。
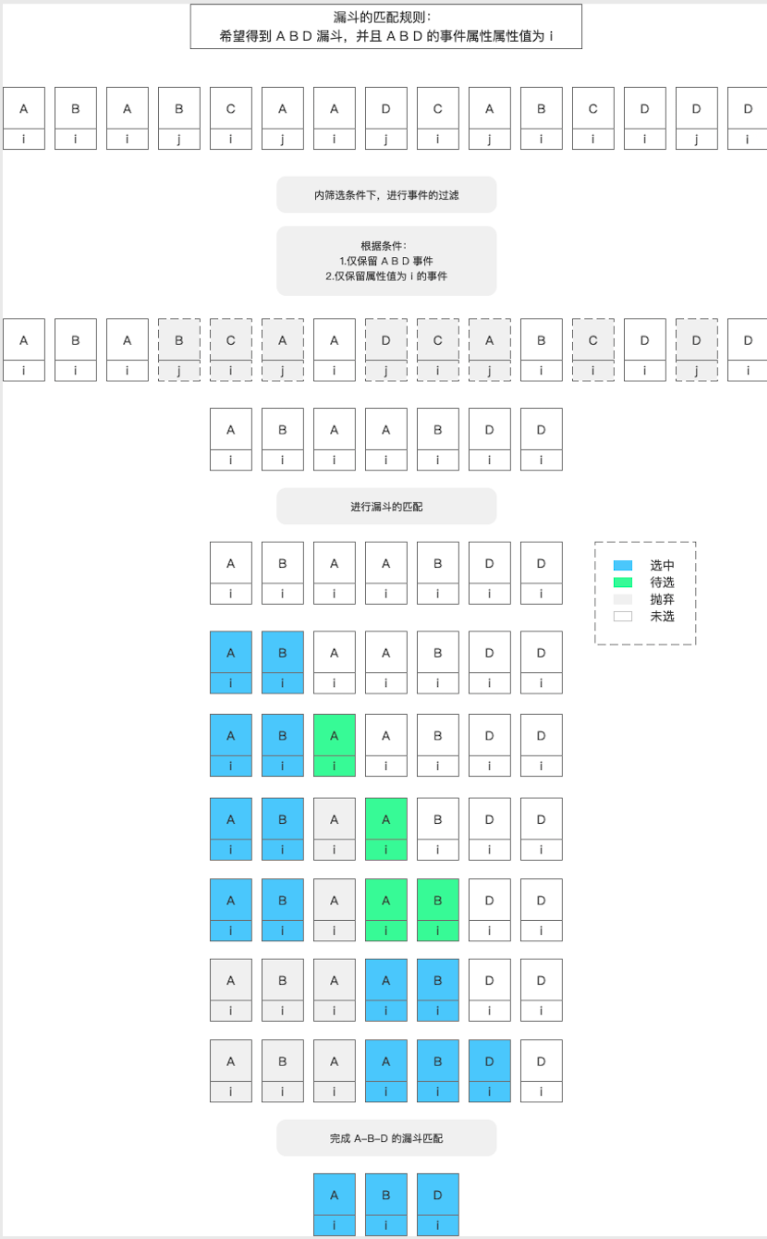
思路2:分桶思想进行匹配
更好的解释属性关联的匹配规则 目的:进行漏斗匹配A、B、D。其中,A、B需要属性关联(即A、B的属性需要相同)。
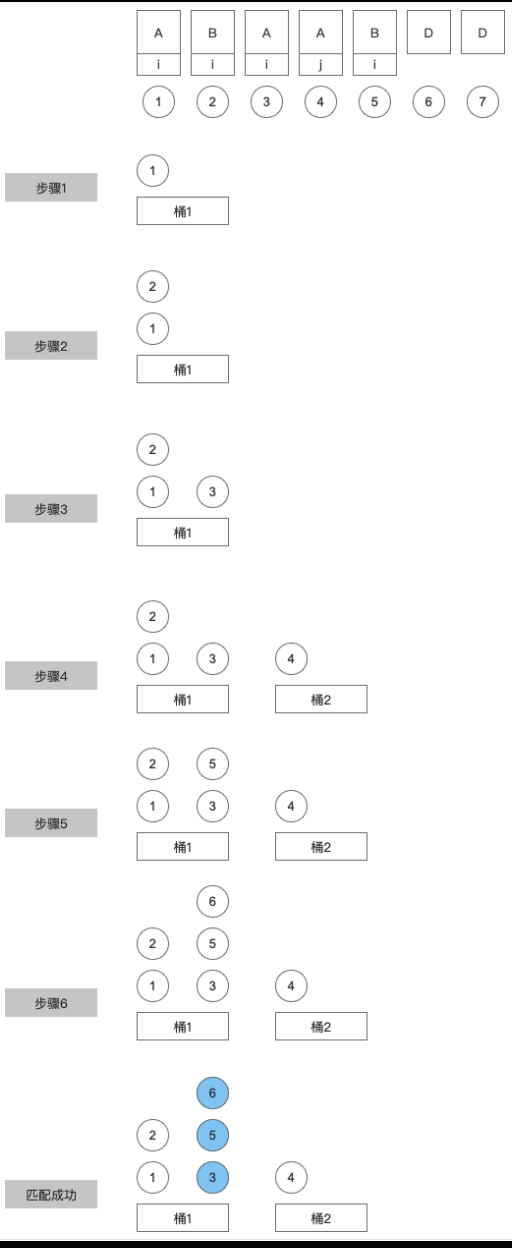
其他:
- A→B→C,事件A作为漏斗的初始事件,事件B作为第二步骤,事件C作为漏斗终止事件;漏斗中的行为需有序进行,无前序步骤的事件会被过滤,不计入有效触发事件次数中;
- 一个用户在一次有序漏斗行为中(从起始事件开始、到终止事件结束),每个步骤的行为事件至多发生一次,多余事件会被过滤,不计入有效触发事件次数中;
- 每次转化的窗口期应根据本次漏斗的起始事件发生时间计算,即同一个用户每次转化的窗口期结束时间并不一致;
- 考虑前序行为的影响可能存在一定滞后性,分桶采取先开启先匹配的原则,即当窗口期有部分重叠时,重叠部分中的后续事件优先用来填满先开启的分桶。
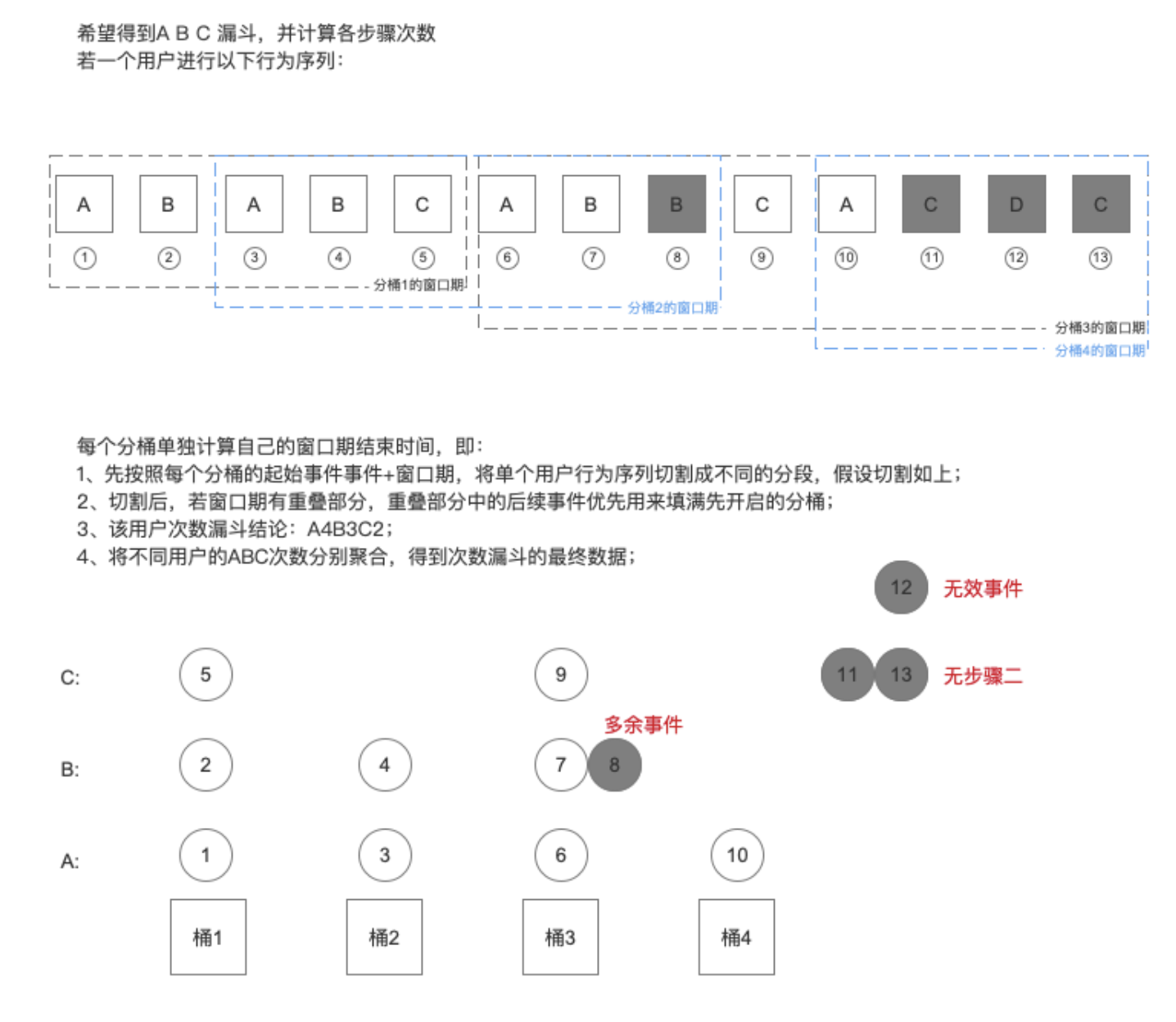
分析过程
留存分析留存计算示例及逻辑
假设数据如下。对应的用户行为序列中:A-注册、B-登录、C-充值。
注:日代表时段。可改为周和月。
留存用户数
1、过滤出第0日含 A 事件的用户,即初始人数;
2、统计各日中,触发后续行为 B 的用户数,即各日的留存用户数。
同时显示 Number 属性的总和
1、过滤出第0日含 A 事件的用户,即初始人数;
2、统计各日中,触发后续行为 B 的用户数,即各日的留存用户数;
3、统计各日中,留存用户的 C 事件的金额(Number 属性)总和。
注意:注意:B、C 事件在同一天发生时,才会统计此次 C 事件。如原行为序列中的标红事件,不会计入总和。
同时显示 Number 属性的阶段累计总和
1、过滤出第0日含 A 事件的用户,即初始人数;
2、统计各日中,触发后续行为 B 的用户数,即各日的留存用户数;
3、统计各日中,留存用户的 C 事件的金额(Number 属性)总和;
4、累计之前所有日期的总和,即阶段累计总和。
同时显示 Number 属性的阶段累计人均值(即 LTV 功能)
1、过滤出第0日含 A 事件的用户,即初始人数;
2、统计各日中,触发后续行为 B 的用户数,即各日的留存用户数;
3、统计各日中,留存用户的 C 事件的金额(Number 属性)总和;
4、累计之前所有日期的总和,即阶段累计总和;
5、用阶段累计总和除以初始行为人数,即阶段累计人均值。
流失分析的流程逻辑
第 7 日流失的计算:第 0 日访问 A 事件的用户,从第 0 日到第 7 日都不在留存用户中,则为流失用户。
分组加权留存/流失率计算示例及逻辑
这里选择初始行为日期外的其他选项时,会按加权方式来计算留存率
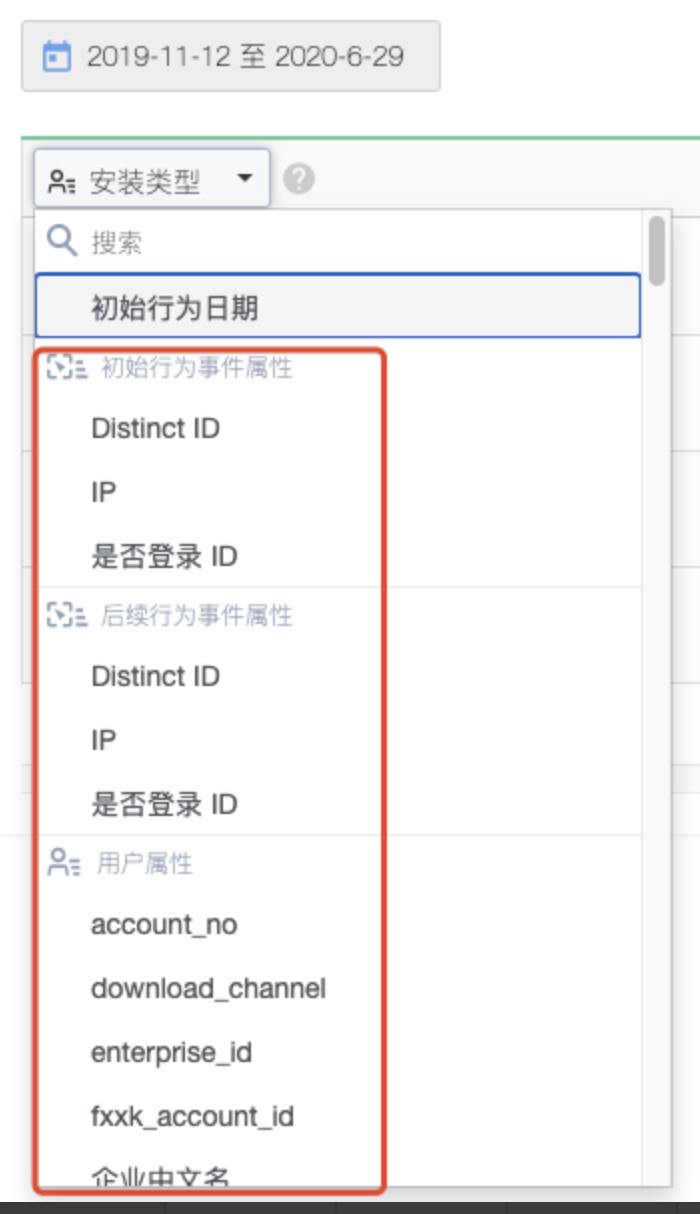
汇总行的留存/流失率修改为采用加权计算,即 “初始行为日期起第 n 天 留存/流失人数之和”除以 “初始行为日期的访问人数之和”。
- 假设1、2、3为三个日期,其初始行为日期的访问人数分别是 S1、S2 和 S3,第N天的留存/流失人数分别是 N1、N2 和 N3;则留存/流失率为: (N1 + N2 + N3)/ (S1 + S2 + S3)
- 如 iOS 分组第 5 天的留存率计算公式为:
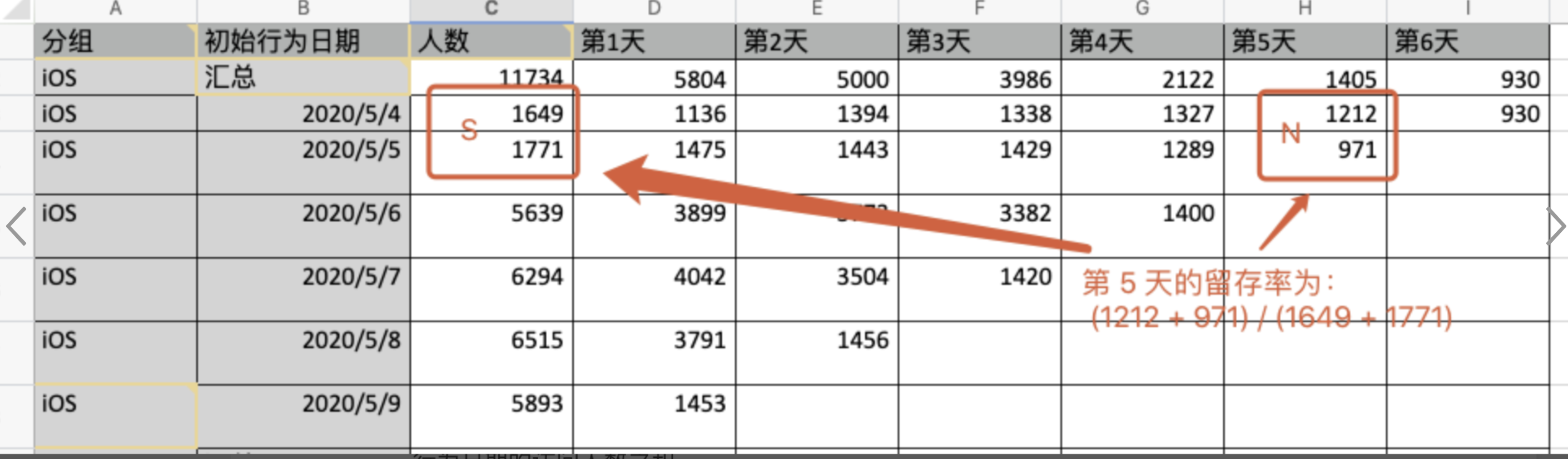
举个例子:
iOS 登录人数(初始行为和后续行为都是 iOS 登录)
- 1日 初始人数 4人,第1天 留存3人
- 2日 初始人数 4人,第1天 留存2人
- 3日 初始人数 5人,第1天 留存3人
- 这三天的初始人数,都来此相同的 5个人,。留存人数也都来自于相同的3个人。
分组行的:初始人数= 5人,第1天 留存人数=3人
- 原来的留存率 = 3/5 = 60%
- 加权计算的分组留存率 =(3+2+3)/(4+4+5)= 8/13 = 61.5%
LTV分析
用户生命周期价值(Life Time Value,LTV),即用户在生命周期中贡献的商业价值。LTV 分析是一种分析用户商业价值的分析模型,可分析特定日期访问的用户群体,在一定时长内所贡献的人均价值。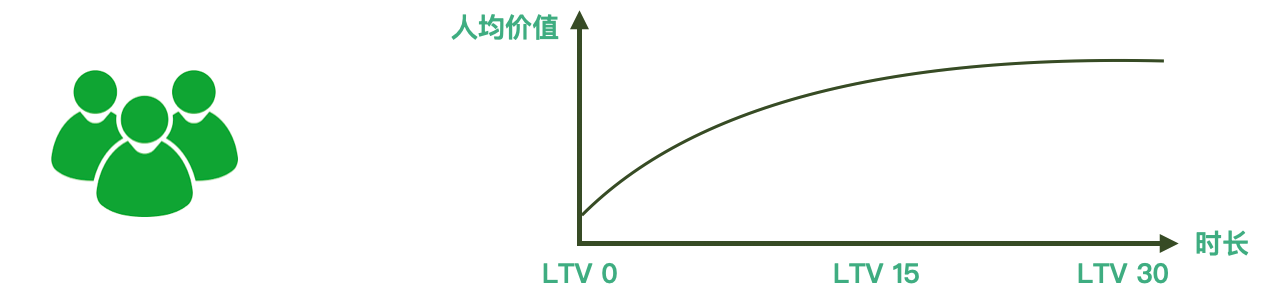
行为序列示例
假设数据如下。对应的用户行为序列:A-注册、B-充值,括号中为充值金额
1、过滤 10、11日含 A 事件的用户,即初始人数;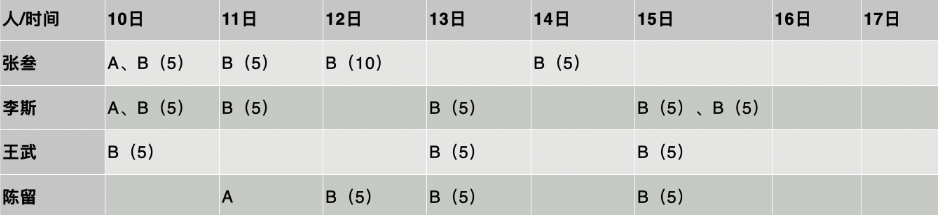
计算口径说明
2、统计各日中,触发后续行为 B 的用户数,即各日的留存用户数。
3、统计各留存日中,留存用户的 B 事件的金额(Number 属性)总和。
4、累计之前所有日期的总和,得到累计总和。
5、用累计总和除以初始行为人数,即 LTV。
汇总 LTV计算示例及逻辑
总体行、指标行和分组行,会展示汇总的 LTV 值。计算口径说明
同上面描述,我们会计算得到用户充值金额的累计总和。
各日期累计总和之和除以其初始人数之和,得到汇总行的 LTV 值。如下,(50+15)/(2+1) = 21.67 即为 10-11 日的汇总 LTV 7。
分布分析
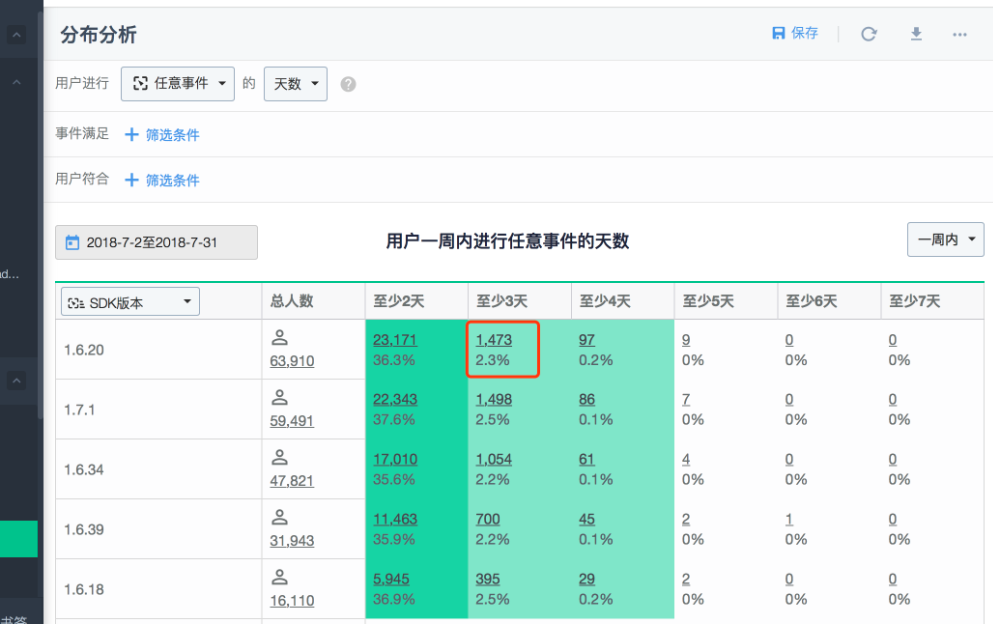
问题:
- Q1:分布分析中,按照一周内查看,如果一个用户在第一天、第二天、第三天、第四天都进行了选择的用户行为,选择「用户行为日期」时,该用户会展示在哪里?
- A:该用户在至少2天、至少3天、至少4天中都会存在。
- 如果想看某天具体的人数,可以让客户自己获取至少当天的人数减去至少后一天的人数。(2天人数-0;3天人数-0;4天人数-1)
- Q2:分布分析中,按照一周内查看选择事件发生的时间范围一个月(假如是四周),然后选择其他查看形式(如 SDK版本),此时用户该如何展示?
- A:此时会获取用户的平均值,并展示到某一个分组(事件的第一个不为空的属性)中。
- 比如一个用户在该月第一周进行用户行为2天,第二周进行了3天,第三周没有任何操作,第四周进行了4天,此时该用户最终展示的分组为 (2+3+4)/3 = 3 ,该用户存在至少2天、至少3天的分组中。如果平均值为小数则获取整数值。
归因分析
1、归因分析适用的场景和模型关系
1.1 业务应用场景
在业务上,一次成功的购买转化可能与很多因素有关系。比如一个商品在 某个广告 形成曝光,在 推荐系统 里曝光,又在 推送消息 中推送进行强化推荐。如果这个商品最后形成的购买的转化,那么这次的购买与推广因素的关系为: [ 浏览广告(18:00) , 推荐系统(18:30) , 推送消息(19:00) ] → [ 购买转化 ] 通过该转化关系,根据自己的业务场景,选择一套适合的 归因模型 ,即可得到每个推广因素的功劳和价值。
1.2 模型关系
归因模型实际上是计算一个事件的发生,与其前序事件的关系程度。我们使用的几种常用的归因模型如下:
- 末次归因
认为多个触点时,最后一次的触点功劳最大,占100%
转化路径少、周期短 - 首次归因
认为多个触点时,第一次的触点功劳最大,占100%
重视商品曝光 - 位置归因
多个触点时,首次和末次分别占有40%功劳,中间部分平分20%功劳
重视最初带来线索和最终产生成交 - 线性归因
每个触点平均分配此次转化功劳
在整个销售周期内保持与客户的联系,并维持品牌认知度 时间衰减归因
每个触点距离目标事件发生时间(分钟),取自身倒数,计算权重后进行标准化处理为每个触点打分
客户决策周期短、销售周期短2、精准计算
在【1.1 业务应用场景】中我们可以看出来,想要找到每次的推广触点,都是通过商品的曝光作为回溯点进行关联回溯的,所以,需要尽可能的提供 曝光事件 辅助归因模型的搭建,通过特定的属性值,可以找到 曝光事件 。
由 目标事件 , 曝光事件 , 归因触点 可以组成以下逻辑关系:[ 曝光事件1,曝光事件2,曝光事件3 ] → [ 购买转化 ]
- [ 推送消息(19:00) ] → [ 曝光事件3 ]
- [ 推荐系统(18:30) ] → [ 曝光事件2 ]
- [ 浏览广告(18:00) ] → [ 曝光事件1 ]
[ 浏览广告(18:00) , 推荐系统(18:30) , 推送消息(19:00) ] → [ 购买转化 ]
3、计算模型输入及作用
目标转化事件
- 是否可以缺省:否
- 范围:全部事件(不包含虚拟事件)
- 作用:作为归因的目标事件
- 前项关键事件
- 是否可以缺省:是
- 范围:全部事件(不能与目标转化事件相同)
- 作用:作为目标转化事件的曝光事件,同时作为向前回溯寻找待归因事件的切割断点。
- 目标事件_关联属性
- 是否可以缺省:是
- 范围:目标转化事件的事件属性
- 作用:与前项关键事件进行关联
- 前项关键事件_关联属性
- 是否可以缺省:是
- 范围:前项关键事件的事件属性
- 作用:与目标转化事件进行关联
- 待归因事件(触点)
- 是否可以缺省:否
- 范围:全部事件
- 作用:作为归因触点参与计算,分配功劳。通过前项关键事件进行关联时,返回最近的一次待归因事件。
- 回溯时长
- 是否可以缺省:否
- 范围:分钟/小时/天
- 作用:从目标转化事件进行前项关键事件的关联时,作为切割点;
- 归因模型
- 是否可以缺省:否
- 范围:预置提供的归因模型
- 作用:得到待归因事件与目标转化事件的关系后,进行分配功劳的计算依据。
- 目标事件时间范围
- 是否可以缺省:否
- 范围:上线至今任意时间段
- 作用:用来控制目标转化事件的时间范围
目标事件的计算指标
M 代表目标事件
- G 代表前项关联事件
-
4.1 目标转化事件
通过目标事件时间范围及目标转化事件,计算出每个 userid 的目标转化事件:

需要进行拆分,认为是两次购买转化,得到:{M1}{M2}
后续进行下一步独立计算4.2 找到前项关联事件
通过目标事件和前项关联事件,关联属性,进行前项关联事件的匹配,回溯时长作为回溯停止的切割点:

得到结果 M1 → { G1_3 , G1_2 , G1_1} G1_1 因为超过了回溯时长被抛掉4.3 找到归因触点
通过前项关联事件,向前进行回溯,与最近的待归因事件进行关联

匹配结果为: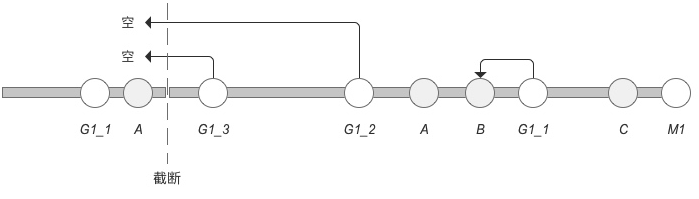
M1 不作为回溯起点,所以 C 被抛掉 { G1_1:B }只匹配最近的待归因事件,所以结果为B { G1_2:空 }G2在向前回溯过程中,直到匹配到回溯时长(切割点)没有匹配结果,返回空 { G1_3:空 }G3在向前回溯过程中,直到匹配到回溯时长(切割点)没有匹配结果,返回空4.4 得到归因序列关系
M1 → { G1_3 , G1_2 , G1_1 } → { 空,空,B}
4.5 模型带入和返回结果
首次模型
- M1 → { 空(1),空(0),B(0)} → { B=0,空=1 }
- 末次模型
- M1 → { 空(0),空(0),B(1)} → { B=1,空=0 }
- 位置模型
- M1 → { 空(0.4),空(0.2),B(0.4)} → { B=0.4,空=0.6 }
- 线性模型
- M1 → { 空(1/3),空(1/3),B(1/3)} → { B=1/3,空=2/3 }
- 时间衰减
- M1(21:00) → { 空(19:00),空(19:30),B(20:00) }
- 时间差转换 { 空(120),空(90),B(60) }
- 倒数标准化结果 { 空(3/13),空(4/13),B(6/13) }
- 求和得到结果 M1 → { B=(6/13),空(7/13) }
- 指标带入
- 目标事件指标选择指标为 总次数 M1=1
- 目标事件指标选择指标为 SUM(某个num类型) M1=SUM(num)
分配功劳
支持缺少前项关联事件
- 直接使用目标事件作为回溯起点进行回溯,匹配回溯窗口期内的全部待归因事件
- 支持缺少关联属性
- 缺少关联属性时,只能进行模糊匹配,目前事件与符合回溯时间窗口内的全部前项关联事件进行关联
- 前项关联事件和待归因事件相同
- 前项关联事件进行回溯时,是包含自身的
5、例子
为了便于理解,给出几个示例,方便理解计算过程 设定 M 为目标事件,G 为前项关联事件,A/B/C 为待归因事件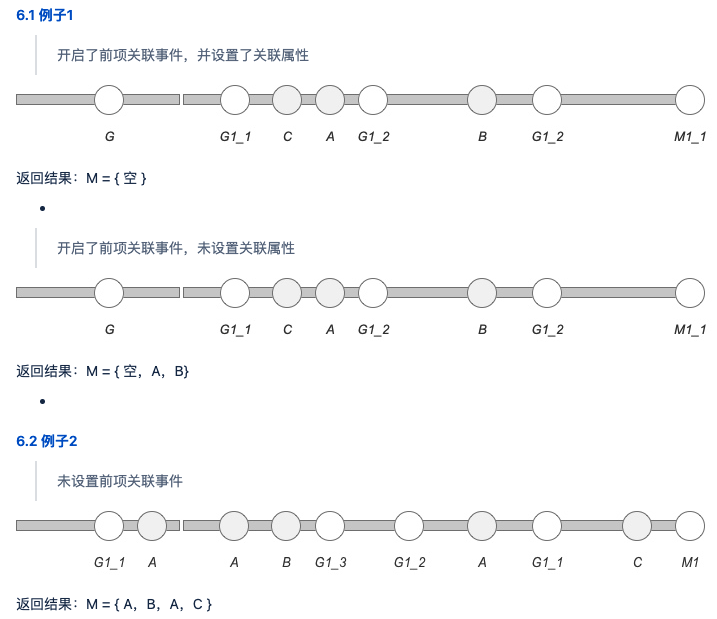
归因分析表格中数据逻辑
点击规模
总点击数:时间控件选的范围内的待归因事件发生总次数,开始时间向前推移归因窗口天数
例如时间控件选择 4 月 4 日 - 4 月 6 日,窗口期为 3 天,则统计 4 月 1 日 - 4 月 6 日 的待归因事件发生总次数
有效转化点击率:待归因事件发生后,窗口期内有目标转化事件的总次数
目标转化
总次数:目标转化的窗口期内有前序待归因事件的事件数 * 100,按选择的归因模型分配后除以 100
贡献度:目标转化事件的总次数 / 所有目标转化事件的总次数之和
间隔分析
产品,运营,市场等人员的日常工作都需要观察某某业务的转化情况。如何衡量转化,除了用漏斗看转化率,还需要看转化时长的分布情况,间隔分析即是解决这类问题和需求的。通过计算用户行为序列中两个事件的时间间隔,得到业务转化环节的转化时长分布。
间隔分析可以帮助你回答以下问题:
包含了实名认证等复杂操作的注册流程,想知道用户从开始注册到注册结束,整个过程花费的时长分布。
电商类产品分析用户首次打开 App 或完成注册,到完成首次下单所花费的时长分布。
投资理财类产品分析新用户完成绑卡到完成首次投资的时间间隔分布。
初始和后续行为是如何配对的
用户分群
基础概念
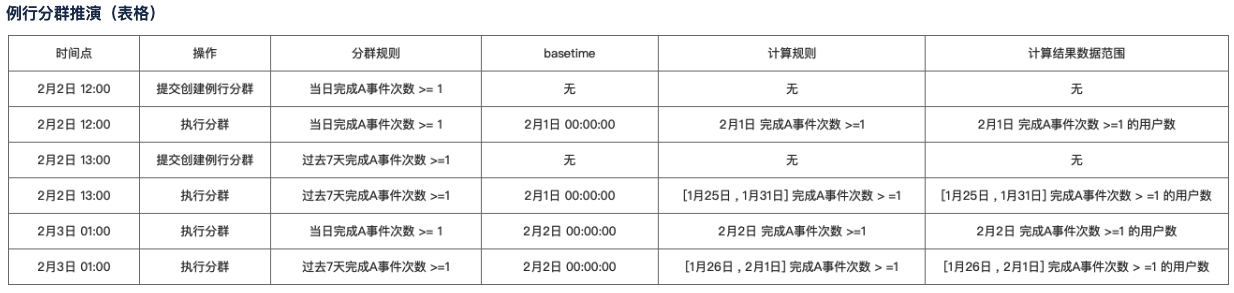
basetime:基准时间,当计算动态时间时,使用该基准时间转换为绝对时间进行计算,basetime 在分群的重新计算时起到重要作用。
- 比如:basetime 为 2月3日,选择时间为动态,过去2天,那么转换为绝对时间为 2月1日——2月2日两天
partition:每次例行计算的结果都认为是一个 partition
数据完备:需要计算的数据都已经入库的状态。目前后端没有一个主动发起校验的工具,所以我们默认为在期望时间点后延迟1个小时,数据都已入库。
计算逻辑
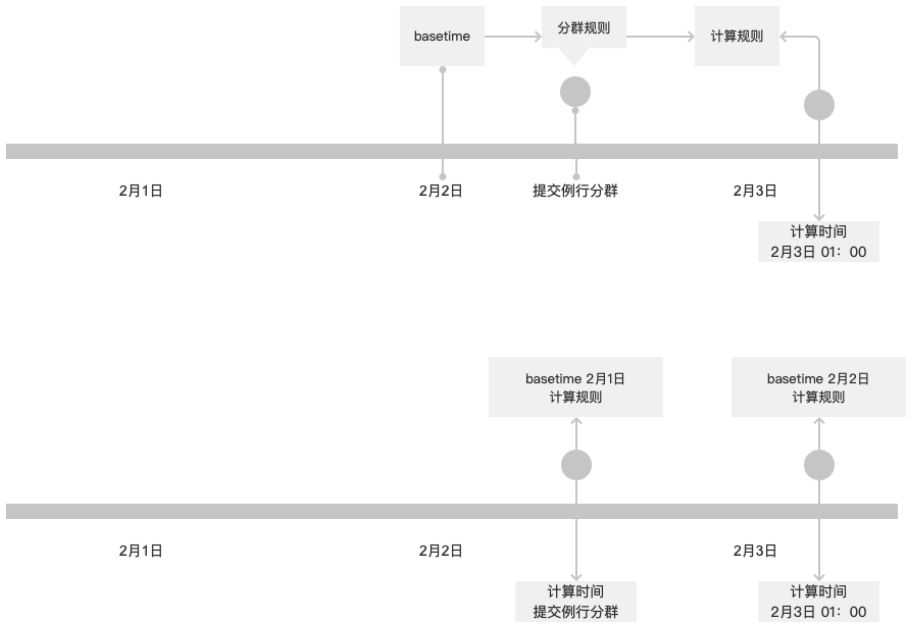
整体的计算策略
分群在执行时,会记录该次计算的 basetime,通过 basetime 可以将描述规则全都转置为绝对的时间对应的数据范围。
根据描述规则,计算分群的结果,将结果保存在数据库中。
单次的分群仅计算一次,例行的分群会有多个 partition,每个 partition 都是使用 basetime 进行区分。
单次分群

若有收获,就点个赞吧
0 人点赞
