从技术角度来思考数据治理和数据驱动型产品,数据从本质上来说是一条“流”。
从最开始的数据采集(数据来源),数据传输(上游),发送到服务器进行数据建模和存储(中游),再对数据进行可视化展示和数据分析(下游),再往后就是数据应用(入海口),形成三角洲地带,多项应用各显神通,用户画像、辅助智能营销,辅助产品(AB)和商业决策(BI+AI)等等。
数据采集
数据采集解决数据从哪来的问题,没有数据来源,数据驱动就是无本之木无源之水。数据采集主要来自以下几个方面:
- 客户端用户行为,App、网页、各类小程序,主要通过埋点 SDK 进行采集;
- 服务端用户行为,可以通过服务端埋点 SDK 采集;
- 已经存储在客户数据库的数据,大型公司一般都有 CDP 平台,形成一定的历史数据;
- 社交平台,如微信、企业微信,授权后是有开放接口拿到对应用户的数据;
- 本地的 csv 、excel 文件也是数据采集的重要来源;
-
数据传输
采集到的数据,需要通过一定手段传输到统一的服务器上,按技术手段可分为实时和批量,push 和 pull。
实时采集的埋点数据,通过 http 请求进行推送;
- 社交平台的数据需要进行订阅,官方会实时或批量发送给第三方;
- 数据库或本地文件数据一般采用单次批量上报的方式,如每日凌晨发送全量 excel,接收方一般会有数据校验模块进行去重操作。
数据建模 / 存储
数据存储之前需要定义一个数据模型,一方面采集的数据需要按照这样的格式入库,另一方面查询应用也是基于该模型。前两部分采集到的各种数据来源,归根结底描述的还是用户行为,描述用户行为需要清楚几个要素即可,who(是谁),when(在什么时间)、where(什么地点)、how(通过什么方式)、what(做了什么事情)。
根据 “人、货、场” 理论,将事件模型拆分成事件和用户,对应底层的两个大宽表,events 和 users。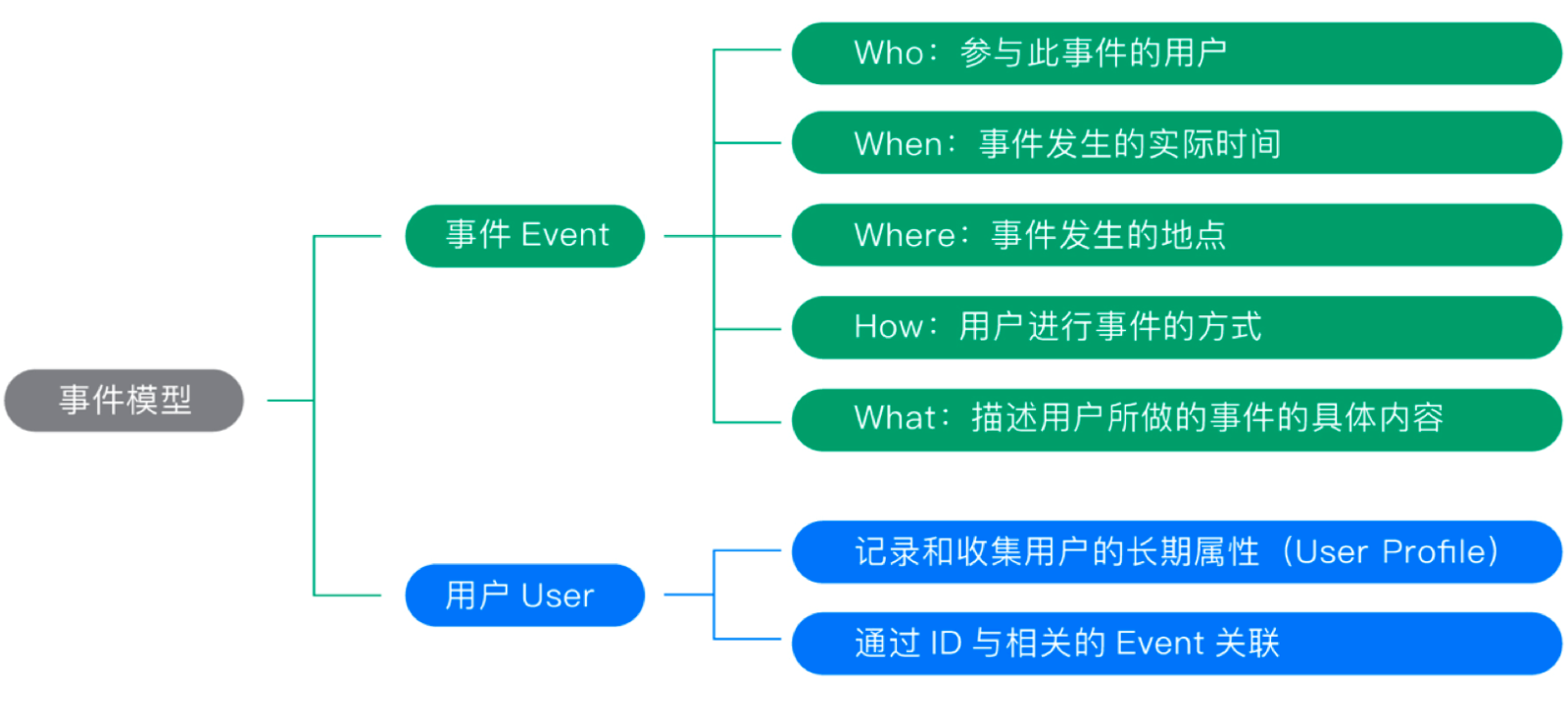
有时候这个“货”无法直接描述清楚,可以再加上 items 表进一步描述。比如我买了个苹果,我的个人信息存储在 users 表中,通过 userid 跟 events 表关联,events 表存储我做的所有行为,苹果是个物品,详细信息存储在 items 表中,通过 itemid 和 itemtype 关联 events 中的物品信息,如此,“人货场”都齐活。数据可视化与分析
通过前端页面进行数据的查询,查询出通过 echarts 等可视化插件实现数据的可视化展示。
基于数据模型会有一些常用的数据分析方法,如事件分析、漏斗分析、留存分析、分布分析、LTV分析(用户生命周期价值)、归因分析、间隔分析等。
将用户关心的数据归总在一个大屏展示,每天更新,形成数据看板。
可视化和数据分析是数据驱动最简单的应用。数据挖掘与产品应用
基于采集的各种数据产生的应用五花八门,犹如长江出海口的三角洲一样星罗密布,各家公司八仙过海各显神通,只要有自己的一套数字化解决方案,就会有客户买单。
比如根据 AARRR 指标划分创建的用户画像;发送ABtest,用来做产品优化;基于广告转化人群数据来做广告投放策略优化;数字化运营工具的使用;千人千面;大数据训练AI辅助商业决策;等等。
各项应用获得的用户数据又反过来通过数据采集入库,进行分析和优化产品或运营活动,结合前文的数据流,形成数据驱动的闭环。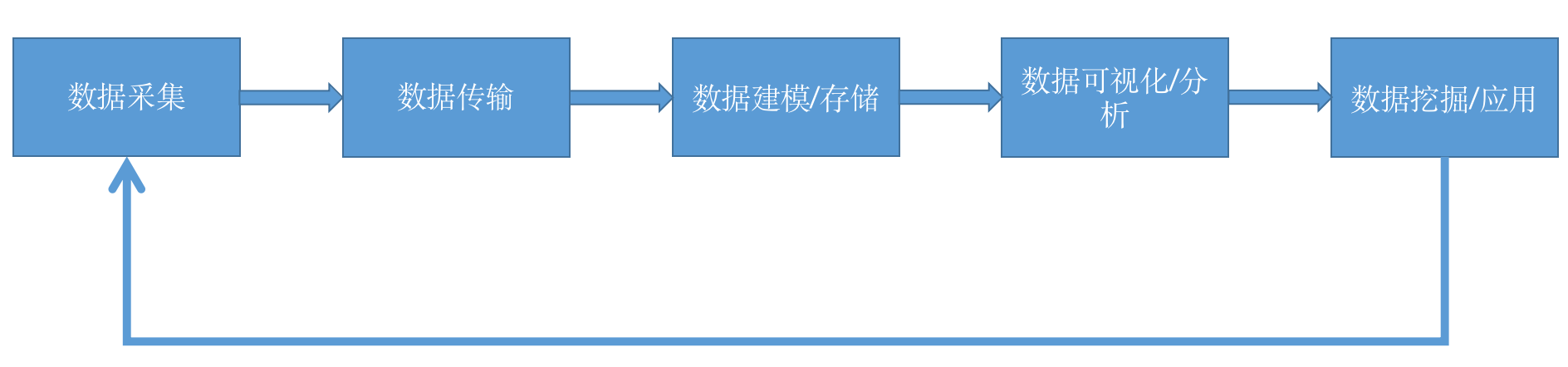

若有收获,就点个赞吧
0 人点赞
