引言
在图节点预测或边预测任务中,需要先构造节点表征(representation),节点表征是图节点预测和边预测任务成功的关键。
在节点预测任务中,我们拥有一个图,图上有很多节点,部分节点的预测标签已知,部分节点的预测标签未知。我们的任务是根据节点的属性(可以是类别型、也可以是数值型)、边的信息、边的属性(如果有的话)、已知的节点预测标签,对未知标签的节点做预测。
我们将以Cora数据集为例子进行说明,Cora是一个论文引用网络,节点代表论文,如果两篇论文存在引用关系,那么认为对应的两个节点之间存在边,每个节点由一个1433维的词包特征向量描述。我们的任务是推断每个文档的类别(共7类)。
为了展现图神经网络的强大,我们通过节点分类任务来比较MLP和GCN、GAT(两个知名度很高的图神经网络)三者的节点表征学习能力。
1. 模型介绍
1.1 图卷积神经网络(GCN)
GCN是一个神经网络层,层与层间传播信息的公式为:
%7D%7D%20%3D%20%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Cmathbf%7B%5Chat%7BA%7D%7D%0A%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Cmathbf%7BH%5E%7B(l)%7D%7D%20%5Cmathbf%7BW%7D%2C%0A#card=math&code=%5Cmathbf%7BH%5E%7B%28l%2B1%29%7D%7D%20%3D%20%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Cmathbf%7B%5Chat%7BA%7D%7D%0A%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Cmathbf%7BH%5E%7B%28l%29%7D%7D%20%5Cmathbf%7BW%7D%2C%0A&id=vqKow)
其中,
,
表示单位矩阵
表示其对角线度矩阵。
- 邻接矩阵可以包括不为
的值,当邻接矩阵不为
{0,1}值时,表示邻接矩阵存储的是边的权重。 对称归一化矩阵。
- 它的节点式描述为
%7Di%20%3D%20%5Cmathbf%7BW%7D%20%5Csum%7Bj%20%5Cin%20%5Cmathcal%7BN%7D(v)%20%5Ccup%0A%5C%7B%20i%20%5C%7D%7D%20%5Cfrac%7Be%7Bj%2Ci%7D%7D%7B%5Csqrt%7B%5Chat%7Bd%7D_j%20%5Chat%7Bd%7D_i%7D%7D%20%5Cmathbf%7Bx%7D_j%5E%7B(l)%7D%0A#card=math&code=%5Cmathbf%7Bx%7D%5E%7B%28l%2B1%29%7D_i%20%3D%20%5Cmathbf%7BW%7D%20%5Csum%7Bj%20%5Cin%20%5Cmathcal%7BN%7D%28v%29%20%5Ccup%0A%5C%7B%20i%20%5C%7D%7D%20%5Cfrac%7Be_%7Bj%2Ci%7D%7D%7B%5Csqrt%7B%5Chat%7Bd%7D_j%20%5Chat%7Bd%7D_i%7D%7D%20%5Cmathbf%7Bx%7D_j%5E%7B%28l%29%7D%0A&id=jrOo4)
对公式的理解:
由上述公式可知,每层GCN的输入都只有两个,邻接矩阵和当前层的节点特征
。往简单的方向考虑,不妨直接把这两个矩阵做个内积,然后再乘以一个参数矩阵
,然后用一个激活函数激活,这就相当于一个简单的神经网络,如下式:
%7D%2C%20A)%20%3D%20%5Csigma(AH%5E%7B(l)%7DW%5E%7B(l)%7D)%0A#card=math&code=f%28H%5E%7B%28l%29%7D%2C%20A%29%20%3D%20%5Csigma%28AH%5E%7B%28l%29%7DW%5E%7B%28l%29%7D%29%0A&id=PwC43)
这个网络已经有一定的分类效果了,但是,有几个局限性:
- 只用邻接矩阵
的话,由于
的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算中心节点的所有邻居的特征的加权和,而没有考虑到当前节点的特征。因此,我们可以做一个小小的改动,给
加上一个单位矩阵
,这样就让对角线元素变成1了,这个操作反映在图里,相当于给图中的节点增加了自环边。
是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我们对
做一个标准化处理,即让
的每一行加起来为1,可以通过乘以一个度矩阵
的逆来实现但是这样我们的A就不对称了。所以,可以进一步把
拆开与
相乘,得到一个对称且归一化的矩阵,即
(这里将D拆开成两部分)。
通过对上面两个局限性的改进,我们便得到了最终的层与层间的特征传播公式:
%7D%2C%20A)%20%3D%20%5Csigma(%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Chat%7BA%7D%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7DH%5E%7B(l)%7DW%5E%7B(l)%7D)%0A#card=math&code=f%28H%5E%7B%28l%29%7D%2C%20A%29%20%3D%20%5Csigma%28%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7D%20%5Chat%7BA%7D%5Cmathbf%7B%5Chat%7BD%7D%7D%5E%7B-1%2F2%7DH%5E%7B%28l%29%7DW%5E%7B%28l%29%7D%29%0A&id=QbOx5)
1.2 图注意力网络(GAT)
1.2.1 GCN的局限性
GCN是转导学习(transductive learning,即训练与测试都基于同样的图结构,且GCN在训练时也用到了测试集的信息,比如说测试集中有节点是训练集中节点的邻居节点)的一把利器,但是其有两大缺点:
- 在归纳学习(inductive learning,即训练阶段与测试阶段需要处理的graph不同。通常是训练阶段只是在子图上进行,测试阶段需要处理未知的顶点)中效果不是很明显,不易处理动态图问题。
- 由于其参数共享的特性(类似于CNN),处理有向图时,不容易实现分配不同的学习权重给不同的邻居节点
【补充】: 转导学习(transductive learning)与归纳学习(inductive learning)
- 转导学习:所有的数在训练阶段均可拿到,学习过程是在这个固定的数据上的,一旦数据发生改变,需要重新进行学习训练
- 归纳学习:可以队训练阶段见不到的数据(在图中可以指新的节点,也可以指新的图)直接预测,而不需要重新训练。
1.2.2 GAT的两种运算方式
以下图为例介绍下GAT的两种计算方式
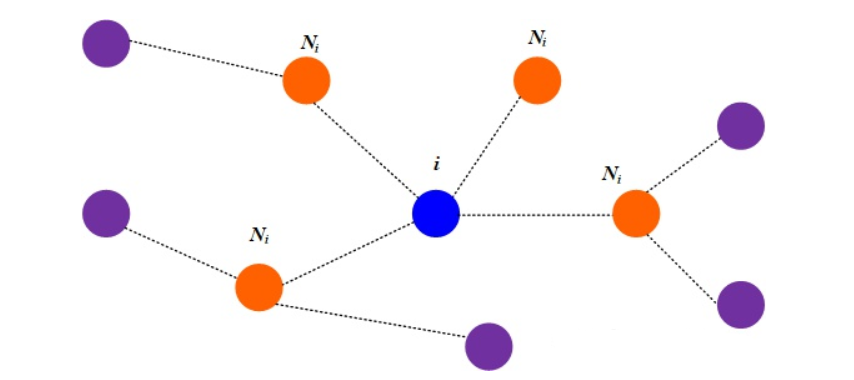
- Global graph attention
顾名思义,每一个顶点都对于图上任意一个顶点进行注意力计算。可以理解为图中的蓝色节点对于其余的全部节点都进行一次运算。这种方式的优点就是完全不依赖于图的结构,在归纳学习上效果很好,但是这样相当于把图结构特征给丢了,反而会达不到预期的效果。
- Mask graph attention
注意力机制的运算只在邻居顶点上进行,也就是说上图的蓝色顶点只计算和橙色顶点的注意力系数。论文中采用的就是这种方式。
1.2.3 GAT原理
和所有的注意力机制一样,GAT的计算也分为两步
1.2.3.1 计算注意力系数
对于顶点,逐个计它的邻居节点(
)和它自己之间的相关系数,公式如下:
%2C%5C%20j%20%5Cin%20Ni%0A#card=math&code=e%7Bij%7D%20%3D%20a%28%5BWh_i%7C%7CWh_j%5D%29%2C%5C%20j%20%5Cin%20N_i%0A&id=lkUAQ)
对公式的理解:
- 首先一个共享参数
的线性映射对于顶点的特征进行了增维,这是一种常见的特征增强(feature augment)方法
对顶点
的变换后的特征进行了拼接(concatenate)
- 最后
#card=math&code=a%28%C2%B7%29&id=ZPLSk) 把拼接后的高维特征映射到一个实数上,这里作者是通过单层前向传播神经网络实现的。
显然,学习顶点间的相关性,就是通过可学习的参数
和映射
#card=math&code=a%28%C2%B7%29&id=D718h)实现的。
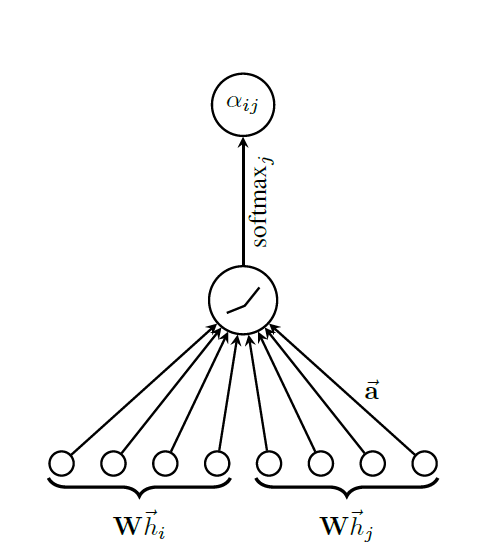
有了相关系数,离注意力系数就差归一化了,这里可以采用softmax计算注意力系数,公式如下:
%5Cright)%7D%0A%7B%5Csum%7Bk%20%5Cin%20%5Cmathcal%7BN%7D(i)%20%5Ccup%20%5C%7B%20i%20%5C%7D%7D%0A%5Cexp%5Cleft(%5Cmathrm%7BLeakyReLU%7D%5Cleft(%5Cmathbf%7Ba%7D%5E%7B%5Ctop%7D%0A%5B%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7D_i%20%5C%2C%20%5CVert%20%5C%2C%20%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7D_k%5D%0A%5Cright)%5Cright)%7D.%0A#card=math&code=%5Calpha%7Bi%2Cj%7D%20%3D%0A%5Cfrac%7B%0A%5Cexp%5Cleft%28%5Cmathrm%7BLeakyReLU%7D%5Cleft%28%5Cmathbf%7Ba%7D%5E%7B%5Ctop%7D%0A%5B%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7Di%20%5C%2C%20%5CVert%20%5C%2C%20%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7D_j%5D%0A%5Cright%29%5Cright%29%7D%0A%7B%5Csum%7Bk%20%5Cin%20%5Cmathcal%7BN%7D%28i%29%20%5Ccup%20%5C%7B%20i%20%5C%7D%7D%0A%5Cexp%5Cleft%28%5Cmathrm%7BLeakyReLU%7D%5Cleft%28%5Cmathbf%7Ba%7D%5E%7B%5Ctop%7D%0A%5B%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7D_i%20%5C%2C%20%5CVert%20%5C%2C%20%5Cmathbf%7B%5CTheta%7D%5Cmathbf%7Bx%7D_k%5D%0A%5Cright%29%5Cright%29%7D.%0A&id=OnCRq)
这里作者采用了LeakyReLU激活函数。
上述运算的示意图如下:
1.2.3.2 加权求和(aggregate)
然后,我们需要根据计算好的注意力系数,把特征加权求和,公式如下:
%7Di%20%3D%20%5Csigma(%5Csum%7Bj%20%5Cin%20Ni%7D%5Calpha%7Bij%7DWhj%5E%7B(l)%7D)%0A#card=math&code=h%5E%7B%28l%2B1%29%7D_i%20%3D%20%5Csigma%28%5Csum%7Bj%20%5Cin%20Ni%7D%5Calpha%7Bij%7DWh_j%5E%7B%28l%29%7D%29%0A&id=Wfj59)
其中,
%7D_i#card=math&code=h%5E%7B%28l%2B1%29%7D_i&id=HhOu4)是第
层GAT输出的每个顶点
的融合了邻域信息的新特征
#card=math&code=%5Csigma%28%C2%B7%29&id=ZnTvO)是激活函数
同样的,GAT也可以引入多头注意力机制,公式如下:
%7Di(K)%20%3D%5Cprod%7Bk%3D1%7D%5EK%20%5Csigma(%5Csum%7Bj%20%5Cin%20N_i%7D%5Calpha%7Bij%7DWhj%5E%7B(l)%7D)%0A#card=math&code=h%5E%7B%28l%2B1%29%7D_i%28K%29%20%3D%5Cprod%7Bk%3D1%7D%5EK%20%5Csigma%28%5Csum%7Bj%20%5Cin%20N_i%7D%5Calpha%7Bij%7DWh_j%5E%7B%28l%29%7D%29%0A&id=UXFTw)
上述计算过程可以按下图来理解
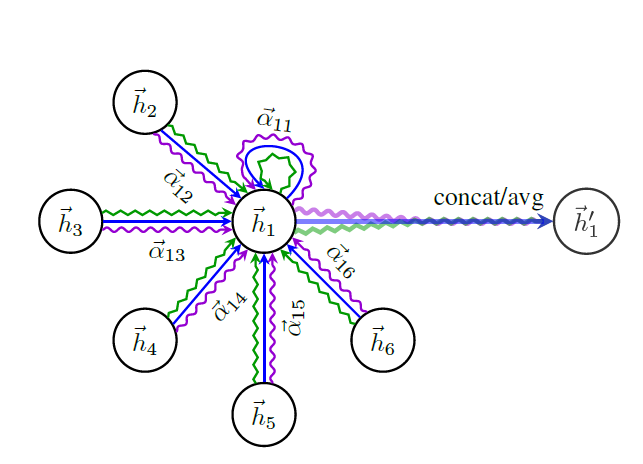
从图中可以看出,这个计算过程是把自环边,也就是节点自身的信息考虑进去了。
2. 准备工作
2.1 获取并分析数据集
from torch_geometric.datasets import Planetoidfrom torch_geometric.transforms import NormalizeFeaturesdataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures())print()print(f'Dataset: {dataset}:')print('======================')print(f'Number of graphs: {len(dataset)}')print(f'Number of features: {dataset.num_features}')print(f'Number of classes: {dataset.num_classes}')'''Dataset: Cora():======================Number of graphs: 1Number of features: 1433Number of classes: 7'''data = dataset[0]print()print(data)print('======================')'''Data(edge_index=[2, 10556], test_mask=[2708], train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])======================'''# Gather some statistics about the graph.print(f'Number of nodes: {data.num_nodes}')print(f'Number of edges: {data.num_edges}')print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')print(f'Number of training nodes: {data.train_mask.sum()}')print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')print(f'Contains isolated nodes: {data.contains_isolated_nodes()}')print(f'Contains self-loops: {data.contains_self_loops()}')print(f'Is undirected: {data.is_undirected()}')'''Number of nodes: 2708Number of edges: 10556Average node degree: 3.90Number of training nodes: 140Training node label rate: 0.05Contains isolated nodes: FalseContains self-loops: FalseIs undirected: True'''
可以看到,Cora图拥有2,708个节点和10,556条边,平均节点度为3.9。我们仅使用140个有真实标签的节点(每类20个)用于训练。有标签的节点的比例只占到5%。进一步我们可以看到,这个图是无向图,不存在孤立的节点(即每个文档至少有一个引文)。数据转换在将数据输入到神经网络之前修改数据,这一功能可用于实现数据规范化或数据增强。在此例子中,我们使用NormalizeFeatures,进行节点特征归一化,使各节点特征总和为1。其他数据转换方法请参阅torch-geometric-transforms。
2.2 可视化节点表征分布的方法
import matplotlib.pyplot as pltfrom sklearn.manifold import TSNEdef visualize(out, color):z = TSNE(n_components=2).fit_transform(out.detach().cpu().numpy())plt.figure(figsize=(10, 10))plt.xticks([])plt.xticks([])plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap='Set2')plt.show()
为了实现节点表征分布的可视化,我们先利用TSNE将高维节点表征嵌入到二维平面空间,然后在二维平面空间画出节点。
3. MLP在图节点分类任务中的应用
理论上,我们应该能够仅根据文件的内容,即它的词包特征表示来推断文件的类别,而无需考虑文件之间的任何关系信息。可以通过构建一个简单的MLP来验证这一点,该网络只对输入节点的特征进行操作,它在所有节点之间共享权重。
3.1 MLP图节点分类器
class MLP(torch.nn.Module):def __init__(self, hidden_channels):super(MLP, self).__init__()torch.manual_seed(12345) # 设置随机种子是为了确保每次生成固定的随机数,使得每次实验结果显示一致self.lin1 = Linear(dataset.num_features, hidden_channels)self.lin2 = Linear(hidden_channels, dataset.num_classes)def forward(self, x):x = self.lin1(x)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.lin2(x)return xmodel = MLP(hidden_channels=16)print(model)'''MLP((lin1): Linear(in_features=1433, out_features=16, bias=True)(lin2): Linear(in_features=16, out_features=7, bias=True))'''
我们的MLP由两个线程层、一个ReLU非线性层和一个dropout操作。第一线程层将1433维的特征向量嵌入(embedding)到低维空间中(hidden_channels=16),第二个线性层将节点表征嵌入到类别空间中(num_classes=7)。
我们利用交叉熵损失和Adam优化器来训练这个简单的MLP网络。
model = MLP(hidden_channels=16)criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)def train():model.train()optimizer.zero_grad() # 清空梯度out = model(data.x)loss = criterion(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()return lossfor epoch in range(1, 201):loss = train()print(f'Epoch:{epoch:03d}, Loss:{loss:.4f}')
在训练过程结束后,我们检测GCN节点分类器在测试集上的准确性:
def test():model.eval()out = model(data.x, data.edge_index)pred = out.argmax(dim=1) # Use the class with highest probability.test_correct = pred[data.test_mask] == data.y[data.test_mask] # Check against ground-truth labels.test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # Derive ratio of correct predictions.return test_acctest_acc = test()print(f'Test Accuracy: {test_acc:.4f}')'''Test Accuracy:0.5740'''
正如我们所看到的,MLP表现相当糟糕,只有大约57.5%的测试准确性。
为什么MLP没有表现得更好呢?
- 其中一个重要原因是,用于训练此神经网络的有标签节点数量过少,此神经网络被过拟合,它对未见过的节点泛化性很差。
可以通过可视化我们训练过的模型输出的节点表征看看分类情况。
model.eval()
out = model(data.x)
visualize(out, color=data.y)
经过visualize函数的处理,7维特征的节点被嵌入到2维的平面上,结果如下图
 )
)
可以看到,节点并没有被有效的分类
4. GCN及其在图节点分类任务中的应用
4.1 PyG中GCNConv 模块说明
GCNConv构造函数接口:
GCNConv(in_channels: int, out_channels: int, improved: bool = False, cached: bool = False, add_self_loops: bool = True, normalize: bool = True, bias: bool = True, **kwargs)
其中,
in_channels:输入数据维度;out_channels:输出数据维度;improved:如果为true,,其目的在于增强中心节点自身信息;
cached:是否存储的计算结果以便后续使用,这个参数只应在归纳学习(transductive learning)的景中设置为
**true**;add_self_loops:是否在邻接矩阵中增加自环边;normalize:是否添加自环边并在运行中计算对称归一化系数;bias:是否包含偏置项。
详细内容请参阅GCNConv官方文档。
4.2 基于GCN图神经网络的图节点分类
通过将torch.nn.Linear层替换为PyG的torch_geometric.nn.XXX层,我们可以轻松地将MLP模型转化为GNN模型。我们将MLP例子中的linear层替换为GCNConv层,来看看效果,代码如下:
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
print(model)
'''
GCN(
(conv1): GCNConv(1433, 16)
(conv2): GCNConv(16, 7)
)
'''
先让我们可视化未训练的GCN网络的节点表征
model = GCN(hidden_channels=16)
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
结果如下图,可以看到不同类的节点目前还是混合在一起的
现在训练GCN节点分类器
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
for epoch in range(1, 201):
loss = train()
print(f'Epoch:{epoch:03d}, Loss:{loss:.4f}')
在训练过程结束后,我们检测GCN节点分类器在测试集上的准确性:
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # Use the class with highest probability.
test_correct = pred[data.test_mask] == data.y[data.test_mask] # Check against ground-truth labels.
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # Derive ratio of correct predictions.
return test_acc
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
# Accuracy: 0.8050
通过简单地将线性层替换成GCN层,我们可以达到80.5%的测试准确率!与前面的仅获得57.5%的测试准确率的MLP分类器相比,现在的分类器准确性要高得多。这表明节点的邻接信息在取得更好的准确率方面起着关键作用。
最后,还可以通过可视化我们训练过的模型输出的节点表征来再次验证这一点,现在同类节点的聚集在一起的情况更加明显了。
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
可视化结果如下图

5. GAT及其在图节点分类任务中的应用
5.1 PyG中GATConv 模块说明
GATConv构造函数接口:
GATConv(in_channels: Union[int, Tuple[int, int]], out_channels: int, heads: int = 1, concat: bool = True, negative_slope: float = 0.2, dropout: float = 0.0, add_self_loops: bool = True, bias: bool = True, **kwargs)
其中,
in_channels:输入数据维度;out_channels:输出数据维度;heads:在GATConv使用多少个注意力模型(Number of multi-head-attentions);concat:如为true,不同注意力模型得到的节点表征被拼接到一起(表征维度翻倍),否则对不同注意力模型得到的节点表征求均值;
详细内容请参阅GATConv官方文档
5.2 基于GAT图神经网络的图节点分类
本节将MLP例子中的linear层替换为GATConv层,来实现基于GAT的图节点分类神经网络,代码如下:
from torch_geometric.nn import GATConv
class GAT(torch.nn.Module):
def __init__(self, hidden_channels):
super(GAT, self).__init__()
torch.manual_seed(12345)
self.conv1 = GATConv(dataset.num_features, hidden_channels)
self.conv2 = GATConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GAT(hidden_channels=16)
print(model)
'''
GAT(
(conv1): GATConv(1433, 16, heads=1)
(conv2): GATConv(16, 7, heads=1)
)
'''
训练及测试代码如下
odel = GAT(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss =criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
for epoch in range(1, 201):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
# Test Accuracy: 0.7380
可以看到,在当前设定的参数下对Cora数据集进行节点分类,使用GAT的准确率反而不如GCN。
下面再来可视化结果看看
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
结果如下图

6. 作业
使用PyG中不同的图卷积层在PyG的不同数据上实现节点分类或回归任务,这里我选择使用GraphSage在Cora数据集上实现节点分类任务
6.1 GraphSAGE原理
GraphSAGE是Graph Sample and Aggregate的缩写,他是一个归纳学习的模型,训练时它仅仅保留训练样本到训练样本的边。其运行流程如下图所示,
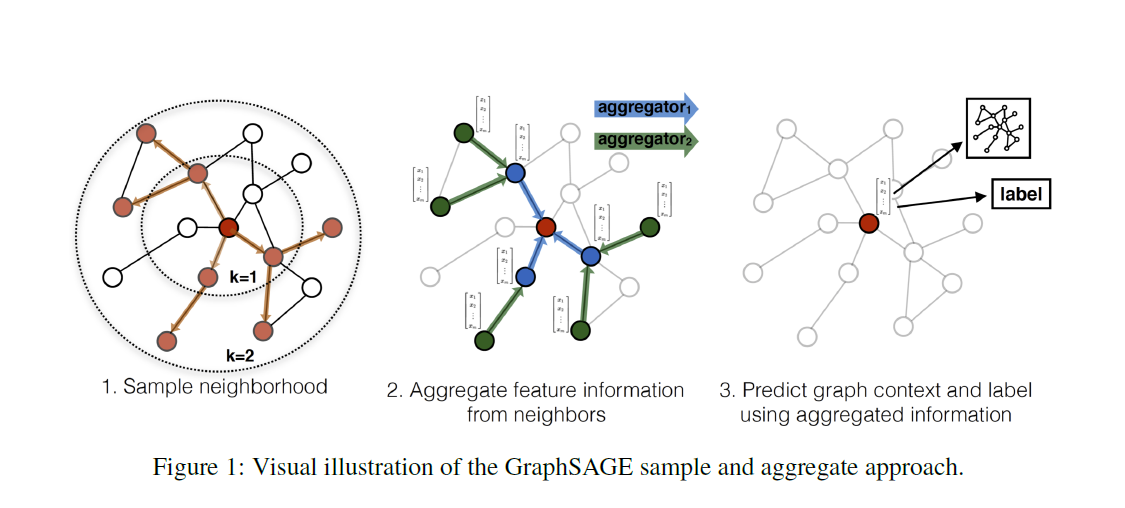
主要分为如下三个步骤
- 对图中每个节点的邻居节点进行采样
- 根据聚合函数聚合邻居节点的特征
- 更新图中各节点的表征供下游任务使用
6.1.1 生成节点表征的前向传播算法
GraphSAGE的前向传播算法的伪代码如下图所示

其中,
- K是网络的层数,也代表着每个顶点能够聚合的邻居节点的跳数,如K=2的时候每个顶点可以最多根据其2跳邻接点的信息学习其自身的表征。
#card=math&code=N%28v%29&id=Nt3Vc)定义为从集合$u \in \mathcal{V}: (u, v) \in \mathcal{E}
S
S
S
S
S$,则采用无放回的抽样。
在第k层的传播中,对每个顶点v,首先使用v的邻接点的第k-1层的表征来产生其邻居顶点的第k层聚合表征
%7D#card=math&code=h%5Ek%7BN%28v%29%7D&id=NmXAa),之后将%7D#card=math&code=h%5Ek_%7BN%28v%29%7D&id=y6Er5)和顶点v的第k-1层表示
进行拼接,经过一个非线性变换与正则化(第7行)产生顶点v的第k层表征
。
6.1.2 聚合函数的选取
在图中节点的邻居是无序的,所以希望构造出的聚合函数是对称的(即也就是对它输入的各种排列,函数的输出结果不变),同时具有较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型可以被训练且可以应用于任意顺序的顶点邻居特征集合上。
Mean Aggregator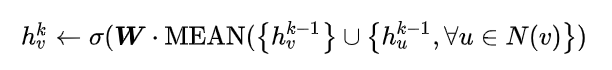
对应伪代码的4-5行,直接生成节点的表征。Mean Aggregator将目标节点和邻居节点的第k-1层的表征拼接起来,然后对向量的每个维度进行求均值的操作,将所得的结果做一次非线性变换产生目标节点的第k层表征。Pooling Aggregator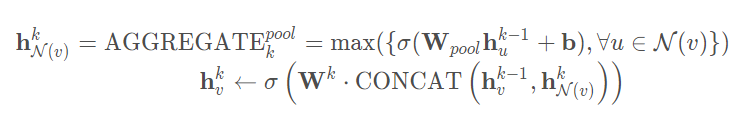
Pooling Aggregator先对目标节点的邻居节点表征进行一次非线性变换,之后进行一次pooling操作(max pooling 或 mean pooling),将得到的结果与目标节点的表征拼接,最后再经过一次非线性变换得到目标节点的第k层表征。LSTM Aggregator
LSTM相比简单的求平均操作具有更强的表达能力,然而由于LSTM函数不是关于输入对称的,所以在使用时需要对顶点的邻居进行一次乱序操作。
6.1.3 参数的学习
6.1.3.1 无监督学习形式
基于图的损失函数倾向于使得相邻的节点有相似的表征,但这会使距离远的节点的表征差异变大:
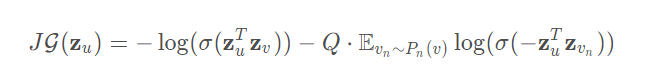
其中,
是节点
通过GraphSAGE生成的表征
- 节点
是节点
经过随机游走到达的节点(这里不一定是邻居节点)
为负采样的概率分布
为负样本的数量
这里的顶点表征是通过聚合顶点的邻居(不一定是邻居节点,只要随机游走可达即可)特征产生的,上式的含义就是在保证相邻的节点的表征的相似度尽量大的情况下使距离较远的节点的表征的期望相似度尽量小。
6.1.3.2 监督学习形式
监督学习形式根据任务的不同直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。
6.2 PyG中SAGEConv模块说明
SAGEConv构造函数接口:
CLASS SAGEConv(in_channels: Union[int, Tuple[int, int]], out_channels: int, normalize: bool = False, root_weight: bool = True, bias: bool = True, **kwargs)
其中,
in_channels:输入数据维度;out_channels:输出数据维度;normalize:正则化,如果其值设为True,则输出特征会采用正则化,即
root_weight:根节点权重,如果其值设为False,则该层不会在输出中加入转换后的根节点的特征;bias:偏移量,如果其值设为False,该层将不会学习增加的偏移量。
详细内容请参阅SAGEConv官方文档
6.3 基于GraphSAGE的图节点分类
将之前模型中的GCNConv替换成SAGEConv,代码如下:
import torch
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import SAGEConv
# 读取并分析数据集
dataset = Planetoid('/Dataset/Planetoid/Cora', 'Cora', transform=NormalizeFeatures())
data = dataset[0]
# print(f'Number of nodes: {data.num_nodes}')
# print(f'Number of edges: {data.num_edges}')
# print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
# print(f'Number of training nodes: {data.train_mask.sum()}')
# print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
# print(f'Contains isolated nodes: {data.contains_isolated_nodes()}')
# print(f'Contains self-loops: {data.contains_self_loops()}')
# print(f'Is undirected: {data.is_undirected()}')
class SAGE(torch.nn.Module):
def __init__(self, hidden_channels):
super(SAGE, self).__init__()
torch.manual_seed(12345)
self.conv1 = SAGEConv(dataset.num_features, hidden_channels)
self.conv2 = SAGEConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = SAGE(hidden_channels=16)
print(model)
'''
SAGE(
(conv1): SAGEConv(1433, 16)
(conv2): SAGEConv(16, 7)
)
'''
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
for epoch in range(1, 201):
loss =train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
结果如下图所示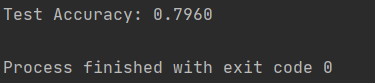
我们也可以可视化结果,代码如下
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
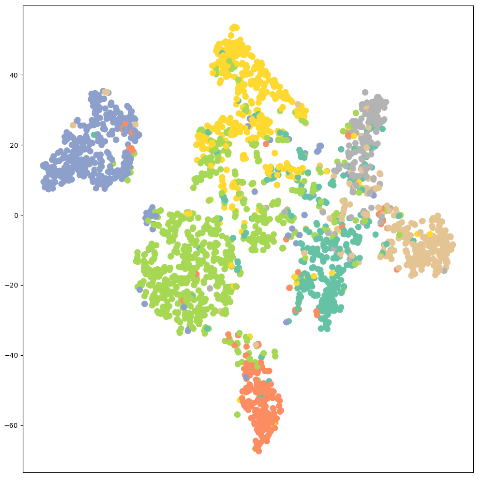
7. 参考资料
- DataWhale开源学习资料:https://github.com/datawhalechina/team-learning-nlp/tree/master/GNN
- PyG官方文档:https://pytorch-geometric.readthedocs.io/en/latest/index.html
- 知乎专栏:https://zhuanlan.zhihu.com/p/81350196
- 知乎专栏:https://zhuanlan.zhihu.com/p/79637787
- GitHub:https://github.com/rusty1s/pytorch_geometric
- GCN论文:https://arxiv.org/abs/1609.02907
- GAT论文:https://arxiv.org/abs/1710.10903
- GraphSage论文:https://arxiv.org/pdf/1706.02216.pdf
- 《深入浅出图神经网络》

若有收获,就点个赞吧
0 人点赞
