引言
虽然PyG内置了许多数据集,但用户可能希望使用自行记录或非公开可用的数据创建自己的数据集。
基于此,PyG为数据集提供了两个抽象类:[torch_geometric.data.Dataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Dataset)和[torch_geometric.data.InMemoryDataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset)。torch_geometric.data.InMemoryDataset继承自torch_geometric.data.Dataset。如果整个数据集适合存于CPU中,则应使用torch_geometric.data.InMemoryDataset。
按照torchvision的惯例,每个数据集都有一个根文件夹,该文件夹用于标识数据集的存储位置。根文件夹下又有两个文件夹:
- 一个文件夹为
**raw_dir**,它用于存储未处理的文件,从网络上下载的数据集文件会被存放到这里; - 另一个文件夹为
**processed_dir**,处理后的数据集被保存到这里。
此外,每个数据集都可以传递一个transform函数、 一个pre_transform函数和一个pre_filter函数,它们的默认值均为None。
**transform**函数接受[Data](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)对象为参数,对其转换后返回。此函数在每一次数据访问时被调用,所以它应该用于数据增广(Data Augmentation)。**pre_transform**函数接受Data对象为参数,对其转换后返回。此函数在样本Data对象保存到文件前调用,所以它最好用于只需要做一次的大量预计算。**pre_filter**函数可以在保存前手动过滤掉数据对象。该函数的一个用例是,过滤样本类别。
1. 创建存于内存的数据集
1.1 InMemoryDataset基类介绍
在PyG中,我们通过继承[InMemoryDataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset)类来自定义一个数据可全部存储到内存的数据集类。
class InMemoryDataset(root: Optional[str] = None, transform: Optional[Callable] = None, pre_transform: Optional[Callable] = None, pre_filter: Optional[Callable] = None)
如上方的[InMemoryDataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset)类的构造函数接口所示
- 每个数据集都要有一个根文件夹(
**root**),根文件夹下又有两个文件夹,分别是raw_dir和processed_dir。 - 继承
[InMemoryDataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset)类的每个数据集类可以传递一个**transform**函数,一个**pre_transform**函数和一个**pre_filter**函数。
为了创建一个[InMemoryDataset](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset),我们需要实现四个基本方法:
**raw_file_names()**:是一个属性方法,返回一个文件名列表,包含在raw_dir文件夹中的文件,如果没有则调用process()函数下载文件到raw_dir文件夹。**processed_file_names()**:是一个属性方法,返回一个文件名列表,包含在processed_dir文件夹中的文件,如果没有则调用process()函数对样本做预处理然后保存到processed_dir文件夹。**download()**: 将原始数据文件下载到raw_dir文件夹。**process()**: 对样本做预处理然后保存到processed_dir文件夹。
下面是一个PyG中的例子
import torchfrom torch_geometric.data import InMemoryDataset, download_urlclass MyOwnDataset(InMemoryDataset):def __init__(self, root, transform=None, pre_transform=None, pre_filter=None):super().__init__(root=root, transform=transform, pre_transform=pre_transform, pre_filter=pre_filter)self.data, self.slices = torch.load(self.processed_paths[0])@propertydef raw_file_names(self):return ['some_file_1', 'some_file_2', ...]@propertydef processed_file_names(self):return ['data.pt']def download(self):# Download to `self.raw_dir`.download_url(url, self.raw_dir)...def process(self):# Read data into huge `Data` list.data_list = [...]if self.pre_filter is not None:data_list = [data for data in data_list if self.pre_filter(data)]if self.pre_transform is not None:data_list = [self.pre_transform(data) for data in data_list]data, slices = self.collate(data_list)torch.save((data, slices), self.processed_paths[0])
样本从原始文件转换成 [Data](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)类对象的过程定义在process函数中。在该函数中,有时我们需要读取和创建一个 [Data](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)对象的列表,并将其保存到processed_dir中。由于python保存一个巨大的列表是相当慢的,因此我们在保存之前通过[collate()](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset.collate)函数将该列表集合成一个巨大的 [Data](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Data)对象。该函数还会返回一个切片字典,以便从这个对象中重构单个样本。最后,我们需要在构造函数中把这Data对象和切片字典分别加载到属性self.data和self.slices中。我们通过下面的例子来介绍生成一个[**InMemoryDataset**](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.InMemoryDataset)子类对象时程序的运行流程。
1.2 定义一个InMemoryDataset子类
由于我们手头没有实际应用中的数据集,因此我们以公开数据集PubMed为例子。PubMed数据集存储的是文章引用网络,文章对应图的结点,如果两篇文章存在引用关系(无论引用与被引),则这两篇文章对应的结点之间存在边。下面参考PyG中的Planetoid类来实现PlanetoidPubMed数据集类,Planetoid类的代码如下。
class Planetoid(InMemoryDataset):r"""The citation network datasets "Cora", "CiteSeer" and "PubMed" from the`"Revisiting Semi-Supervised Learning with Graph Embeddings"<https://arxiv.org/abs/1603.08861>`_ paper.Nodes represent documents and edges represent citation links.Training, validation and test splits are given by binary masks.Args:root (string): Root directory where the dataset should be saved.name (string): The name of the dataset (:obj:`"Cora"`,:obj:`"CiteSeer"`, :obj:`"PubMed"`).split (string): The type of dataset split(:obj:`"public"`, :obj:`"full"`, :obj:`"random"`).If set to :obj:`"public"`, the split will be the public fixed splitfrom the`"Revisiting Semi-Supervised Learning with Graph Embeddings"<https://arxiv.org/abs/1603.08861>`_ paper.If set to :obj:`"full"`, all nodes except those in the validationand test sets will be used for training (as in the`"FastGCN: Fast Learning with Graph Convolutional Networks viaImportance Sampling" <https://arxiv.org/abs/1801.10247>`_ paper).If set to :obj:`"random"`, train, validation, and test sets will berandomly generated, according to :obj:`num_train_per_class`,:obj:`num_val` and :obj:`num_test`. (default: :obj:`"public"`)num_train_per_class (int, optional): The number of training samplesper class in case of :obj:`"random"` split. (default: :obj:`20`)num_val (int, optional): The number of validation samples in case of:obj:`"random"` split. (default: :obj:`500`)num_test (int, optional): The number of test samples in case of:obj:`"random"` split. (default: :obj:`1000`)transform (callable, optional): A function/transform that takes in an:obj:`torch_geometric.data.Data` object and returns a transformedversion. The data object will be transformed before every access.(default: :obj:`None`)pre_transform (callable, optional): A function/transform that takes inan :obj:`torch_geometric.data.Data` object and returns atransformed version. The data object will be transformed beforebeing saved to disk. (default: :obj:`None`)"""url = 'https://github.com/kimiyoung/planetoid/raw/master/data'def __init__(self, root, name, split="public", num_train_per_class=20,num_val=500, num_test=1000, transform=None,pre_transform=None):# 这里也可以直接删去self.name与接口中的name,然后把后面self.name的值改为“PubMed”(部分位置要改为小写),即可实现我们的需求self.name = namesuper(PlanetoidPubMed, self).__init__(root, transform, pre_transform)self.data, self.slices = torch.load(self.processed_paths[0])self.split = splitassert self.split in ['public', 'full', 'random']if split == 'full':data = self.get(0)data.train_mask.fill_(True)data.train_mask[data.val_mask | data.test_mask] = Falseself.data, self.slices = self.collate([data])elif split == 'random':data = self.get(0)data.train_mask.fill_(False)for c in range(self.num_classes):idx = (data.y == c).nonzero(as_tuple=False).view(-1)idx = idx[torch.randperm(idx.size(0))[:num_train_per_class]]data.train_mask[idx] = Trueremaining = (~data.train_mask).nonzero(as_tuple=False).view(-1)remaining = remaining[torch.randperm(remaining.size(0))]data.val_mask.fill_(False)data.val_mask[remaining[:num_val]] = Truedata.test_mask.fill_(False)data.test_mask[remaining[num_val:num_val + num_test]] = Trueself.data, self.slices = self.collate([data])@propertydef raw_dir(self):return osp.join(self.root, self.name, 'raw')@propertydef processed_dir(self):return osp.join(self.root, self.name, 'processed')@propertydef raw_file_names(self):names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']return ['ind.{}.{}'.format(self.name.lower(), name) for name in names]@propertydef processed_file_names(self):return 'data.pt'def download(self):for name in self.raw_file_names:download_url('{}/{}'.format(self.url, name), self.raw_dir)def process(self):data = read_planetoid_data(self.raw_dir, self.name)data = data if self.pre_transform is None else self.pre_transform(data)torch.save(self.collate([data]), self.processed_paths[0])def __repr__(self):return '{}()'.format(self.name)
实现PlanetoidPubMed数据集类的代码如下:
class PlanetoidPubMed(InMemoryDataset):
url = 'https://github.com/kimiyoung/planetoid/raw/master/data'
def __init__(self, root='/Dataset/Planetoid/PubMed', transform=None, pre_transform=None, pre_filter=None):
self.raw = osp.join(root,'raw')
self.processed = osp.join(root, 'processed')
super(PlanetoidPubMed, self).__init__(root=root, transform=transform, pre_transform=pre_transform, pre_filter=pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0]) # processed_paths来自于Dataset类
# 定义四个函数,其中前两个是属性获取,采用property修饰器
# 返回原始文件列表
@property
def raw_file_names(self):
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return ['ind.pubmed.{}'.format(name) for name in names]
# 返回需要跳过的文件列表
@property
def processed_file_names(self):
return ['data.pt']
# 下载原生文件
def download(self):
for name in self.raw_file_names:
download_url('{}/{}'.format(self.url, name), self.raw)
def process(self):
data = read_planetoid_data(self.raw, "pubmed")
data_list = [data]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
# 显示属性
def __rper__(self):
return 'PubMed()'
下面来查看这个数据集:
print(dataset.num_classes)
print(dataset[0].num_nodes)
print(dataset[0].num_edges)
print(dataset[0].num_features)
'''
3
19717
88648
500
'''
可以看到这个数据集包含三个分类任务,共19,717个结点,88,648条边,节点特征维度为500。
最后总结一下,在我们生成一个PlanetoidPubMed类的对象时,程序运行流程如下:
- 首先检查数据原始文件是否已下载:
- 检查
self.raw_dir目录下是否存在raw_file_names()属性方法返回的每个文件, - 如有文件不存在,则调用
download()方法执行原始文件下载。 - 其中
self.raw_dir为osp.join(self.root, 'raw')。
- 检查
其次检查数据是否经过处理:
- 首先检查之前对数据做变换的方法:检查
self.processed_dir目录下是否存在pre_transform.pt文件:如果存在,意味着之前进行过数据变换,则需加载该文件获取之前所用的数据变换的方法,并检查它与当前pre_transform参数指定的方法是否相同;如果不相同则会报出一个警告,“The pre_transform argument differs from the one used in ……”。 - 接着检查之前的样本过滤的方法:检查
self.processed_dir目录下是否存在pre_filter.pt文件,如果存在,意味着之前进行过样本过滤,则需加载该文件获取之前所用的样本过滤的方法,并检查它与当前pre_filter参数指定的方法是否相同,如果不相同则会报出一个警告,“The pre_filter argument differs from the one used in ……”。其中self.processed_dir为osp.join(self.root, 'processed')。 - 接着检查是否存在处理好的数据:检查
self.processed_dir目录下是否存在self.processed_paths方法返回的所有文件,如有文件不存在,意味着不存在已经处理好的样本的文件,如需执行以下的操作:- 调用
process方法,进行数据处理。 - 如果
pre_transform参数不为None,则调用pre_transform方法进行数据处理。 - 如果
pre_filter参数不为None,则进行样本过滤(此例子中不需要进行样本过滤,pre_filter参数始终为None)。 - 保存处理好的数据到文件,文件存储在
processed_paths()属性方法返回的路径。如果将数据保存到多个文件中,则返回的路径有多个。这些路径都在self.processed_dir目录下,以processed_file_names()属性方法的返回值为文件名。 - 最后保存新的
pre_transform.pt文件和pre_filter.pt文件,其中分别存储当前使用的数据处理方法和样本过滤方法。
- 调用
这点从Dataset类中也可以看出,如下图- 首先检查之前对数据做变换的方法:检查
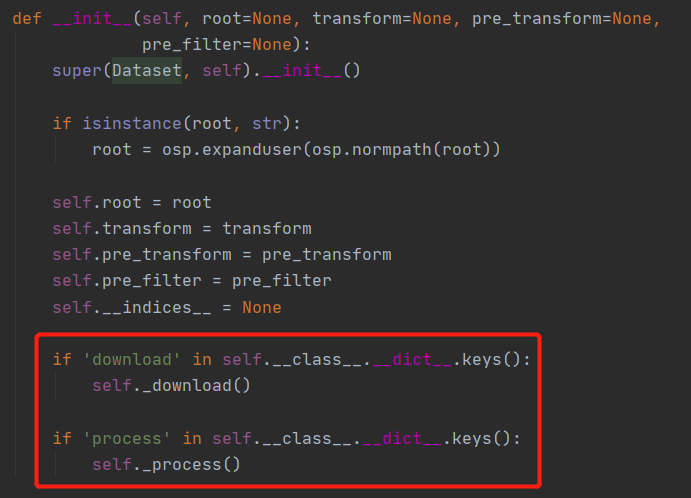
可以看到,程序都是默认先执行下载操作,再执行处理操作。
2. 创建大型数据集
为了创建并不能存入内存的数据集,可以使用:torch_geometric.data.Dataset类,。它需要自己实现两个方法:
torch_geometric.data.Dataset.len():返回数据集的长度。[torch_geometric.data.Dataset.get()](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Dataset.get): 实现加载单个图的逻辑。
在类的内部,由[torch_geometric.data.Dataset.__getitem__()](https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#torch_geometric.data.Dataset.__getitem__)从torch_geometric.data.Dataset.get()获取数据对象根据参数transform选择是否转换数据。
下面是PyG文档中的一个例子
import os.path as osp
import torch
from torch_geometric.data import Dataset, download_url
class MyOwnDataset(Dataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data_1.pt', 'data_2.pt', ...]
def download(self):
# Download to `self.raw_dir`.
path = download_url(url, self.raw_dir)
...
def process(self):
i = 0
for raw_path in self.raw_paths:
# Read data from `raw_path`.
data = Data(...)
if self.pre_filter is not None and not self.pre_filter(data):
continue
if self.pre_transform is not None:
data = self.pre_transform(data)
torch.save(data, osp.join(self.processed_dir, 'data_{}.pt'.format(i)))
i += 1
def len(self):
return len(self.processed_file_names)
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
可以看到,每个图数据对象单独保存在process()中,并且通过get()加载。
3. 参考资料

若有收获,就点个赞吧
0 人点赞
