1.节点预测任务实践
1.1 读取数据
本节我们将利用在前一节中构造的PlanetoidPubMed数据集类来实践节点预测任务。读取数据集的代码如下:
import os.path as ospimport torchfrom torch_geometric.data import InMemoryDataset, download_urlfrom torch_geometric.io import read_planetoid_datafrom torch_geometric.transforms import NormalizeFeatures# 本节采用基于Planetoid类修改的方式得到PlanetoidPubMed数据类class PlanetoidPubMed(InMemoryDataset):r""" 节点代表文章,边代表引文关系。训练、验证和测试的划分通过二进制掩码给出。参数:root (string): 存储数据集的文件夹的路径transform (callable, optional): 数据转换函数,每一次获取数据时被调用。pre_transform (callable, optional): 数据转换函数,数据保存到文件前被调用。"""url = 'https://github.com/kimiyoung/planetoid/raw/master/data'def __init__(self, root, split="public", num_train_per_class=20,num_val=500, num_test=1000, transform=None,pre_transform=None):super(PlanetoidPubMed, self).__init__(root, transform, pre_transform)self.data, self.slices = torch.load(self.processed_paths[0])self.split = splitassert self.split in ['public', 'full', 'random']if split == 'full':data = self.get(0)data.train_mask.fill_(True)data.train_mask[data.val_mask | data.test_mask] = Falseself.data, self.slices = self.collate([data])elif split == 'random':data = self.get(0)data.train_mask.fill_(False)for c in range(self.num_classes):idx = (data.y == c).nonzero(as_tuple=False).view(-1)idx = idx[torch.randperm(idx.size(0))[:num_train_per_class]]data.train_mask[idx] = Trueremaining = (~data.train_mask).nonzero(as_tuple=False).view(-1)remaining = remaining[torch.randperm(remaining.size(0))]data.val_mask.fill_(False)data.val_mask[remaining[:num_val]] = Truedata.test_mask.fill_(False)data.test_mask[remaining[num_val:num_val + num_test]] = Trueself.data, self.slices = self.collate([data])@propertydef raw_dir(self):return osp.join(self.root, 'raw')@propertydef processed_dir(self):return osp.join(self.root, 'processed')@propertydef raw_file_names(self):names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']return ['ind.pubmed.{}'.format(name) for name in names]@propertydef processed_file_names(self):return 'data.pt'def download(self):for name in self.raw_file_names:download_url('{}/{}'.format(self.url, name), self.raw_dir)def process(self):data = read_planetoid_data(self.raw_dir, 'pubmed')data = data if self.pre_transform is None else self.pre_transform(data)torch.save(self.collate([data]), self.processed_paths[0])def __repr__(self):return 'PubMed()'dataset = PlanetoidPubMed('/Dataset/Planetoid/PubMed', transform=NormalizeFeatures())print('data.num_features:', dataset.num_features)device = torch.device('cuda' if torch.cuda.torch.cuda.is_available() else 'cpu')data = dataset[0].to(device)# data.num_features: 500
1.1 定义GAT图神经网络
之前我们学过实现由2层GATConv组成的图神经网络,现在我们重定义一个GAT图神经网络,使其能够通过参数来定义**GATConv**的层数,以及每一层**GATConv**的**out_channels**。代码如下
import torchimport torch.nn.functional as Ffrom torch_geometric.nn import GATConv, Sequentialfrom torch.nn import Linear, ReLUclass GAT(torch.nn.Module):def __init__(self, num_features, hidden_channnels_list, num_classes):super(GAT, self).__init__()torch.manual_seed(12345)hns = [num_features] + hidden_channnels_listconv_list = []for idx in range(len(hidden_channnels_list)):conv_list.append((GATConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))conv_list.append(ReLU(inplace=True), ) # inplace表示是否将得到的值计算得到的值覆盖之前的值self.convseq = Sequential('x, edge_index', conv_list)self.linear = Linear(hidden_channnels_list[-1], num_classes)def forward(self, x, edge_index):x = self.convseq(x, edge_index)x = F.dropout(x, p=0.5, training=self.training)x = self.linear(x)return x
由于我们的神经网络由多个GATConv顺序相连而构成,因此我们使用了torch_geometric.nn.Sequential容器。其参数描述如下
**hidden_channels_list**:来设置每一层**GATConv**的**outchannel**,所以**hidden_channels_list**长度即为**GATConv**的层数。
通过修改hidden_channels_list参数,我们就可构造出不同的图神经网络。
【补充】:
PyG 的Sequential容器:
**CLASS Sequential(args: str,modules: List[Union[Tuple[Callable, [str], Callable]])**
扩展自torch.nn.Sequential容器,用于定义顺序的GNN模型。因为GNN的运算符接收多个输入参数,所以torch_geometric.nn.Sequential需要全局输入参数和单个运算符的函数头定义。如果省略,中间模块将对前一个模块的输出进行操作。
参数说明:
**args**(str):模型的全局输入参数**modules**([(str, Callable) 或 Callable]) :模块列表(带有可选的函数头定义)
下面先来看一个简单的例子:
from torch.nn import Linear, ReLUfrom torch_geometric.nn import Sequential, GCNConvmodel = Sequential('x, edge_index', [(GCNConv(in_channels, 64), 'x, edge_index -> x'),ReLU(inplace=True),(GCNConv(64, 64), 'x, edge_index -> x'),ReLU(inplace=True),Linear(64, out_channels),])
其中,
'x, edge_index'定义了模型的全局输入参数'x,edge_index->x'定义了函数头,即GCNConv层的输入参数与返回类型
此外,PyG 的Sequential容器还允许定义更复杂的模型,比如使用[JumpingKnowledge](https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.models.JumpingKnowledge):
from torch.nn import Linear, ReLU, Dropoutfrom torch_geometric.nn import Sequential, GCNConv, JumpingKnowledgefrom torch_geometric.nn import global_mean_poolmodel = Sequential('x, edge_index, batch', [(Dropout(p=0.5), 'x -> x'),(GCNConv(dataset.num_features, 64), 'x, edge_index -> x1'),ReLU(inplace=True),(GCNConv(64, 64), 'x1, edge_index -> x2'),ReLU(inplace=True),(lambda x1, x2: [x1, x2], 'x1, x2 -> xs'),(JumpingKnowledge("cat", 64, num_layers=2), 'xs -> x'),(global_mean_pool, 'x, batch -> x'),Linear(2 * 64, dataset.num_classes),])
1.2 模型训练与测试
定义模型,选择损失函数与优化器的代码如下
model = GAT(num_features=dataset.num_features, hidden_channnels_list=[200, 100], num_classes=dataset.num_classes).to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)criterion = torch.nn.CrossEntropyLoss()print(model)'''GAT((convseq): Sequential((0): GATConv(500, 200, heads=1)(1): ReLU(inplace=True)(2): GATConv(200, 100, heads=1)(3): ReLU(inplace=True))(linear): Linear(in_features=100, out_features=3, bias=True))'''
定义训练方法与测试方法的代码如下
def train():
model.train()
optimizer.zero_grad() # 清空梯度
out = model(data.x, data.edge_index) # 执行一次前向传播
# 基于训练的节点计算损失
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 反向传播
optimizer.step() # 基于梯度更新所有的参数
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # 采用可能性最高的进行预测
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 选择预测正确的标签
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算准确率
return test_acc
模型训练与预测的代码如下
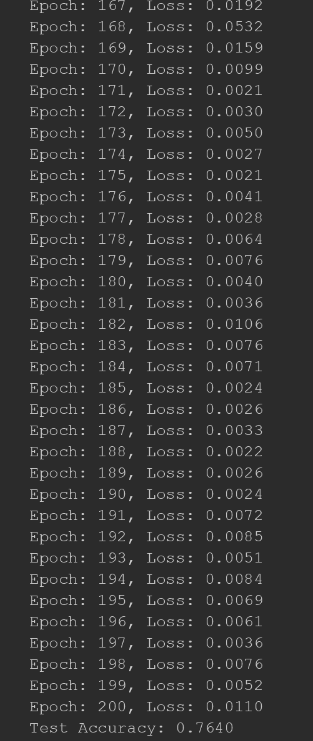
for epoch in range(1, 201):
loss =train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
结果如下图所示
2. 边预测任务实践
边预测任务的目标是预测两个节点间是否有边。本节我们将采用Cora数据集进行边预测任务。
2.1 获取数据集并分析
拿到一个图数据集,我们有节点属性x,边端点edge_index。edge_index存储的便是正样本。为了构建边预测任务,我们需要生成一些负样本,即采样一些不存在边的节点对作为负样本边,正负样本数量应平衡。此外要将样本分为训练集、验证集和测试集三个集合。
PyG中为我们提供了现成的采样负样本边的方法,train_test_split_edges(data, val_ratio=0.05, test_ratio=0.1),参数说明如下
- 第一个参数为
torch_geometric.data.Data对象, - 第二参数为验证集所占比例,
- 第三个参数为测试集所占比例。
该函数将自动地采样得到负样本,并将正负样本分成训练集、验证集和测试集三个集合。它用train_pos_edge_index、train_neg_adj_mask、val_pos_edge_index、val_neg_edge_index、test_pos_edge_index和test_neg_edge_index,六个属性取代edge_index属性。
【注意】:train_neg_adj_mask与其他属性格式不同,其实该属性在后面并没有派上用场,后面我们仍然需要进行一次训练集负样本采样。
获取并分析数据集的代码如下:
import os.path as osp
from torch_geometric.utils import negative_sampling
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as T
from torch_geometric.utils import train_test_split_edges
dataset = Planetoid('/Dataset/Planetoid/Cora/', 'Cora', transform=T.NormalizeFeatures())
data = dataset[0]
data.train_mask = data.val_mask = data.test_mask = data.y = None # 这几个属性在边预测中用不到,记为None
print(data.edge_index.shape)
# torch.Size([2, 10556])
data = train_test_split_edges(data)
print(data)
# Data(test_neg_edge_index=[2, 527], test_pos_edge_index=[2, 527], train_neg_adj_mask=[2708, 2708], train_pos_edge_index=[2, 8976], val_neg_edge_index=[2, 263], val_pos_edge_index=[2, 263], x=[2708, 1433])
for key in data.keys:
print(key, getattr(data, key).shape)
'''
x torch.Size([2708, 1433])
val_pos_edge_index torch.Size([2, 263])
test_pos_edge_index torch.Size([2, 527])
train_pos_edge_index torch.Size([2, 8976])
train_neg_adj_mask torch.Size([2708, 2708])
val_neg_edge_index torch.Size([2, 263])
test_neg_edge_index torch.Size([2, 527])
'''
注意这里训练集、验证集和测试集中的正样本边数之和为263+527+8976=9766不等于原始边的数量10556。这是因为现在所用的Cora图是无向图,在统计原始边数量时,每一条边的正向与反向各统计了一次,训练集也包含边的正向与反向,但验证集与测试集都只包含了边的一个方向。按这种思路计算的话,有263 + 527 + 8976/2 = 5278,正好为10556的一半。
那么,为什么训练集要包含边的正向与反向,而验证集与测试集都只包含了边的一个方向?
- 这是因为,训练集用于训练,训练时一条边的两个端点要互传信息,只考虑一个方向的话,只能由一个端点传信息给另一个端点,而验证集与测试集的边用于衡量检验边预测的准确性,只需考虑一个方向的边即可。
2.2 边预测图神经网络的构造
用于边预测的神经网络主要由两部分组成:
- 编码(encode):它与我们前面介绍的节点表征生成是一样的
- 解码(decode):它根据边两端节点的表征生成边为真的几率(odds)。
构造边预测神经网络的代码如下:
import torch
from torch_geometric.nn import GCNConv
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(Net, self).__init__()
self.conv1 = GCNConv(in_channels, 128)
self.conv2 = GCNConv(128, out_channels)
def encode(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
return self.conv2(x, edge_index)
def decode(self, z, pos_edge_index, neg_edge_index):
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1)
return (z[edge_index[0]] * z[edge_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t() # @ 表示矩阵乘法
return (prob_adj > 0).nonzero(as_tuple=False).t()
其中,
decode_all(self, z)用于推理(inference)阶段,我们要对所有的节点对预测存在边的几率。
2.3 边预测图神经网络的训练与测试
2.3.1 定义单个epoch的训练过程
# 构造标签
def get_link_labels(pos_edge_index, neg_edge_index):
num_links = pos_edge_index.size(1) + neg_edge_index.size(1)
link_labels = torch.zeros(num_links, dtype=torch.float)
link_labels[:pos_edge_index.size(1)] = 1
return link_labels
def train(data, model, optimizer):
model.train()
neg_edge_index = negative_sampling(
edge_index = data.train_pos_edge_index,
num_nodes = data.num_nodes,
num_neg_samples = data.train_pos_edge_index.size(1)
)
train_neg_edge_set = set(map(tuple, neg_edge_index.T.tolist()))
val_pos_edge_set = set(map(tuple, data.val_pos_edge_index.T.tolist()))
test_pos_edge_set = set(map(tuple, data.test_pos_edge_index.T.tolist()))
if (len(train_neg_edge_set & val_pos_edge_set) > 0) or (len(train_neg_edge_set & test_pos_edge_set) > 0):
print('wrong!')
optimizer.zero_grad()
z = model.encode(data.x, data.train_pos_edge_index)
link_logits = model.decode(z, data.train_pos_edge_index, neg_edge_index)
link_labels = get_link_labels(data.train_pos_edge_index, neg_edge_index).to(data.x.device)
loss = F.binary_cross_entropy_with_logits(link_logits, link_labels)
loss.backward()
optimizer.step()
return loss
【注意】:在训练阶段,我们应该只见训练集,对验证集与测试集都是不可见的。所以我们没有使用所有的边,而是只用了训练集正样本边。
【补充】:
binary_cross_entropy()和binary_cross_entropy_with_logits()的区别:
binary_cross_entropy_with_logits()内部自带了计算对数的操作,无需在传入给这个loss函数之前手动使用sigmoid/softmax将之前网络的输入映射到[0,1]之间- 将
sigmoid层和binaray_cross_entropy合在一起计算比分开依次计算有更好的数值稳定性,这主要是运用了log-sum-exp技巧,可以有效防止数据溢出,公式如下:%20%3D%20log(%5Csum%7Bk%3D1%7D%5Ene%5E%7Bx_i%7D)%0A#card=math&code=logsumexp%28x_1%2C%20..%2C%20x_n%29%20%3D%20log%28%5Csum%7Bk%3D1%7D%5Ene%5E%7Bxi%7D%29%0A&id=ex3lE)
对于上式,当很大时,
就很容易溢出,为了避免这样的问题,可以做如下变换: %20%3D%20log(e%5Ec%5Csum%7Bk%3D1%7D%5Ene%5E%7Bxi-c%7D)%20%3D%20cloge%20%2B%20log(%5Csum%7Bk%3D1%7D%5Ene%5E%7Bxi-c%7D)%0A#card=math&code=log%28%5Csum%7Bk%3D1%7D%5Ene%5E%7Bxi%7D%29%20%3D%20log%28e%5Ec%5Csum%7Bk%3D1%7D%5Ene%5E%7Bxi-c%7D%29%20%3D%20cloge%20%2B%20log%28%5Csum%7Bk%3D1%7D%5Ene%5E%7Bx_i-c%7D%29%0A&id=X55YQ)
于是这样就可以避免数据溢出了。
2.3.2 定义单个epoch验证与测试过程
from sklearn.metrics import roc_auc_score
# 测试部分不需要计算梯度
@torch.no_grad()
def test(data, model):
model.eval()
z = model.encode(data.x, data.train_pos_edge_index)
results = []
for prefix in ['val', 'test']:
pos_edge_index = data[f'{prefix}_pos_edge_index']
neg_edge_index = data[f'{prefix}_neg_edge_index']
link_logits = model.decode(z, pos_edge_index, neg_edge_index)
link_probs = link_logits.sigmoid()
link_labels = get_link_labels(pos_edge_index, neg_edge_index)
results.append(roc_auc_score(link_labels.cpu(), link_probs.cpu()))
return results
【注意】:在验证与测试阶段,我们也应该只见训练集,对验证集与测试集都是不可见的。所以在验证与测试阶段,我们依然只用训练集正样本边。
2.3.3 运行完整的训练、验证与测试
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# dataset = 'Cora'
# # 路径拼接
# path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', dataset)
# dataset = Planetoid(path, dataset, transform=T.NormalizeFeatures())
dataset = Planetoid('/Dataset/Planetoid/Cora', 'Cora', transform=T.NormalizeFeatures())
data = dataset[0]
ground_truth_edge_index = data.edge_index.to(device)
data.train_mask = data.val_mask = data.test_mask = data.y = None
data = train_test_split_edges(data)
data = data.to(device)
model = Net(dataset.num_features, 64).to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
best_val_auc = test_auc = 0
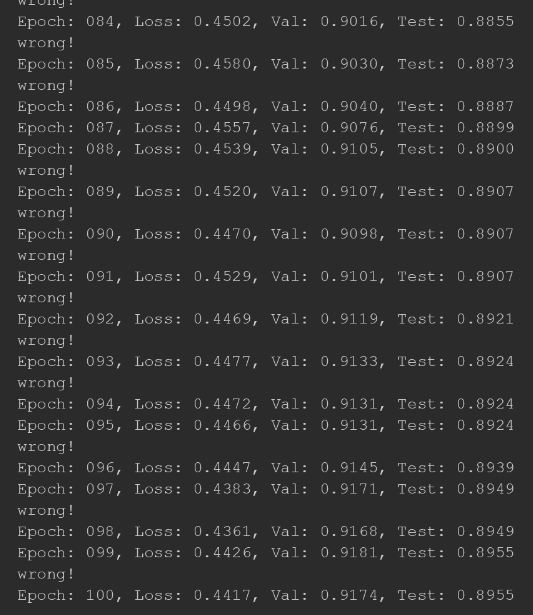
for epoch in range(1, 101):
loss = train(data, model, optimizer)
val_auc, tmp_test_auc = test(data, model)
if val_auc > best_val_auc:
best_val_auc = val_auc
test_auc = tmp_test_auc
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_auc:.4f}, '
f'Test: {test_auc:.4f}')
z = model.encode(data.x, data.train_pos_edge_index)
final_edge_index = model.decode_all(z)
if __name__ == "__main__":
main()
结果如下图所示
3. 作业
3.1 作业一
- 尝试使用PyG中的不同的网络层去代替
GCNConv,以及不同的层数和不同的out_channels,来实现节点分类任务
这里我选择用GCN和GraphSage代替GAT进行节点分类
3.1.1 使用GCNConv进行节点分类任务
代码如下:
import os.path as osp
import torch
import torch.nn.functional as F
from torch.nn import Linear, ReLU
from torch_geometric.data import InMemoryDataset, download_url
from torch_geometric.io import read_planetoid_data
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import GCNConv, Sequential
class PlanetoidPubMed(InMemoryDataset):
r""" 节点代表文章,边代表引文关系。
训练、验证和测试的划分通过二进制掩码给出。
参数:
root (string): 存储数据集的文件夹的路径
transform (callable, optional): 数据转换函数,每一次获取数据时被调用。
pre_transform (callable, optional): 数据转换函数,数据保存到文件前被调用。
"""
url = 'https://github.com/kimiyoung/planetoid/raw/master/data'
def __init__(self, root, split="public", num_train_per_class=20,
num_val=500, num_test=1000, transform=None,
pre_transform=None):
super(PlanetoidPubMed, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
self.split = split
assert self.split in ['public', 'full', 'random']
if split == 'full':
data = self.get(0)
data.train_mask.fill_(True)
data.train_mask[data.val_mask | data.test_mask] = False
self.data, self.slices = self.collate([data])
elif split == 'random':
data = self.get(0)
data.train_mask.fill_(False)
for c in range(self.num_classes):
idx = (data.y == c).nonzero(as_tuple=False).view(-1)
idx = idx[torch.randperm(idx.size(0))[:num_train_per_class]]
data.train_mask[idx] = True
remaining = (~data.train_mask).nonzero(as_tuple=False).view(-1)
remaining = remaining[torch.randperm(remaining.size(0))]
data.val_mask.fill_(False)
data.val_mask[remaining[:num_val]] = True
data.test_mask.fill_(False)
data.test_mask[remaining[num_val:num_val + num_test]] = True
self.data, self.slices = self.collate([data])
@property
def raw_dir(self):
return osp.join(self.root, 'raw')
@property
def processed_dir(self):
return osp.join(self.root, 'processed')
@property
def raw_file_names(self):
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return ['ind.pubmed.{}'.format(name) for name in names]
@property
def processed_file_names(self):
return 'data.pt'
def download(self):
for name in self.raw_file_names:
download_url('{}/{}'.format(self.url, name), self.raw_dir)
def process(self):
data = read_planetoid_data(self.raw_dir, 'pubmed')
data = data if self.pre_transform is None else self.pre_transform(data)
torch.save(self.collate([data]), self.processed_paths[0])
def __repr__(self):
return 'PubMed()'
class GCN(torch.nn.Module):
def __init__(self, num_features, hidden_channnels_list, num_classes):
super(GCN, self).__init__()
torch.manual_seed(12345)
hns = [num_features] + hidden_channnels_list
conv_list = []
for idx in range(len(hidden_channnels_list)):
conv_list.append((GCNConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True), ) # inplace表示是否将得到的值计算得到的值覆盖之前的值
self.convseq = Sequential('x, edge_index', conv_list)
self.linear = Linear(hidden_channnels_list[-1], num_classes)
def forward(self, x, edge_index):
x = self.convseq(x, edge_index)
x = F.dropout(x, p=0.5, training=self.training)
x = self.linear(x)
return x
def train(data, model, optimizer, criterion):
model.train()
optimizer.zero_grad() # 清空梯度
out = model(data.x, data.edge_index) # 执行一次前向传播
# 基于训练的节点计算损失
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 反向传播
optimizer.step() # 基于梯度更新所有的参数
return loss
def test(data, model):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # 采用可能性最高的进行预测
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 选择预测正确的标签
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算准确率
return test_acc
def main():
device = torch.device('cuda' if torch.cuda.torch.cuda.is_available() else 'cpu')
dataset = PlanetoidPubMed('/Dataset/Planetoid/PubMed', transform=NormalizeFeatures())
# print('data.num_features:', dataset.num_features)
data = dataset[0].to(device)
model = GCN(num_features=dataset.num_features, hidden_channnels_list=[200, 100], num_classes=dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, 201):
loss =train(data, model, optimizer, criterion)
# print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test(data, model)
print(f'Test Accuracy: {test_acc:.4f}')
if __name__ == "__main__":
main()
结果如下图所示:

3.1.2 使用SAGEConv进行节点分类任务
代码如下:
import os.path as osp
import torch
import torch.nn.functional as F
from torch.nn import Linear, ReLU
from torch_geometric.data import InMemoryDataset, download_url
from torch_geometric.io import read_planetoid_data
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import SAGEConv, Sequential
class PlanetoidPubMed(InMemoryDataset):
r""" 节点代表文章,边代表引文关系。
训练、验证和测试的划分通过二进制掩码给出。
参数:
root (string): 存储数据集的文件夹的路径
transform (callable, optional): 数据转换函数,每一次获取数据时被调用。
pre_transform (callable, optional): 数据转换函数,数据保存到文件前被调用。
"""
url = 'https://github.com/kimiyoung/planetoid/raw/master/data'
def __init__(self, root, split="public", num_train_per_class=20,
num_val=500, num_test=1000, transform=None,
pre_transform=None):
super(PlanetoidPubMed, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
self.split = split
assert self.split in ['public', 'full', 'random']
if split == 'full':
data = self.get(0)
data.train_mask.fill_(True)
data.train_mask[data.val_mask | data.test_mask] = False
self.data, self.slices = self.collate([data])
elif split == 'random':
data = self.get(0)
data.train_mask.fill_(False)
for c in range(self.num_classes):
idx = (data.y == c).nonzero(as_tuple=False).view(-1)
idx = idx[torch.randperm(idx.size(0))[:num_train_per_class]]
data.train_mask[idx] = True
remaining = (~data.train_mask).nonzero(as_tuple=False).view(-1)
remaining = remaining[torch.randperm(remaining.size(0))]
data.val_mask.fill_(False)
data.val_mask[remaining[:num_val]] = True
data.test_mask.fill_(False)
data.test_mask[remaining[num_val:num_val + num_test]] = True
self.data, self.slices = self.collate([data])
@property
def raw_dir(self):
return osp.join(self.root, 'raw')
@property
def processed_dir(self):
return osp.join(self.root, 'processed')
@property
def raw_file_names(self):
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return ['ind.pubmed.{}'.format(name) for name in names]
@property
def processed_file_names(self):
return 'data.pt'
def download(self):
for name in self.raw_file_names:
download_url('{}/{}'.format(self.url, name), self.raw_dir)
def process(self):
data = read_planetoid_data(self.raw_dir, 'pubmed')
data = data if self.pre_transform is None else self.pre_transform(data)
torch.save(self.collate([data]), self.processed_paths[0])
def __repr__(self):
return 'PubMed()'
class SAGE(torch.nn.Module):
def __init__(self, num_features, hidden_channnels_list, num_classes):
super(SAGE, self).__init__()
torch.manual_seed(12345)
hns = [num_features] + hidden_channnels_list
conv_list = []
for idx in range(len(hidden_channnels_list)):
conv_list.append((SAGEConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True), ) # inplace表示是否将得到的值计算得到的值覆盖之前的值
self.convseq = Sequential('x, edge_index', conv_list)
self.linear = Linear(hidden_channnels_list[-1], num_classes)
def forward(self, x, edge_index):
x = self.convseq(x, edge_index)
x = F.dropout(x, p=0.5, training=self.training)
x = self.linear(x)
return x
def train(data, model, optimizer, criterion):
model.train()
optimizer.zero_grad() # 清空梯度
out = model(data.x, data.edge_index) # 执行一次前向传播
# 基于训练的节点计算损失
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 反向传播
optimizer.step() # 基于梯度更新所有的参数
return loss
def test(data, model):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # 采用可能性最高的进行预测
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 选择预测正确的标签
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算准确率
return test_acc
def main():
device = torch.device('cuda' if torch.cuda.torch.cuda.is_available() else 'cpu')
dataset = PlanetoidPubMed('/Dataset/Planetoid/PubMed', transform=NormalizeFeatures())
# print('data.num_features:', dataset.num_features)
data = dataset[0].to(device)
model = SAGE(num_features=dataset.num_features, hidden_channnels_list=[200, 100], num_classes=dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, 201):
loss =train(data, model, optimizer, criterion)
# print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test(data, model)
print(f'Test Accuracy: {test_acc:.4f}')
if __name__ == "__main__":
main()
结果如下图所示:

3.1.3 使用不同层数的GATConv进行节点分类任务
本次我采用一个三层的GAT进行节点分类,其中隐藏层的节点数分别为400、200和100,代码如下:
import os.path as osp
import torch
import torch.nn.functional as F
from torch.nn import Linear, ReLU
from torch_geometric.data import InMemoryDataset, download_url
from torch_geometric.io import read_planetoid_data
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import GATConv, Sequential
# 同样采用我们自定义的数据集
class PlanetoidPubMed(InMemoryDataset):
r""" 节点代表文章,边代表引文关系。
训练、验证和测试的划分通过二进制掩码给出。
参数:
root (string): 存储数据集的文件夹的路径
transform (callable, optional): 数据转换函数,每一次获取数据时被调用。
pre_transform (callable, optional): 数据转换函数,数据保存到文件前被调用。
"""
url = 'https://github.com/kimiyoung/planetoid/raw/master/data'
def __init__(self, root, split="public", num_train_per_class=20,
num_val=500, num_test=1000, transform=None,
pre_transform=None):
super(PlanetoidPubMed, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
self.split = split
assert self.split in ['public', 'full', 'random']
if split == 'full':
data = self.get(0)
data.train_mask.fill_(True)
data.train_mask[data.val_mask | data.test_mask] = False
self.data, self.slices = self.collate([data])
elif split == 'random':
data = self.get(0)
data.train_mask.fill_(False)
for c in range(self.num_classes):
idx = (data.y == c).nonzero(as_tuple=False).view(-1)
idx = idx[torch.randperm(idx.size(0))[:num_train_per_class]]
data.train_mask[idx] = True
remaining = (~data.train_mask).nonzero(as_tuple=False).view(-1)
remaining = remaining[torch.randperm(remaining.size(0))]
data.val_mask.fill_(False)
data.val_mask[remaining[:num_val]] = True
data.test_mask.fill_(False)
data.test_mask[remaining[num_val:num_val + num_test]] = True
self.data, self.slices = self.collate([data])
@property
def raw_dir(self):
return osp.join(self.root, 'raw')
@property
def processed_dir(self):
return osp.join(self.root, 'processed')
@property
def raw_file_names(self):
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return ['ind.pubmed.{}'.format(name) for name in names]
@property
def processed_file_names(self):
return 'data.pt'
def download(self):
for name in self.raw_file_names:
download_url('{}/{}'.format(self.url, name), self.raw_dir)
def process(self):
data = read_planetoid_data(self.raw_dir, 'pubmed')
data = data if self.pre_transform is None else self.pre_transform(data)
torch.save(self.collate([data]), self.processed_paths[0])
def __repr__(self):
return 'PubMed()'
class GAT(torch.nn.Module):
def __init__(self, num_features, hidden_channnels_list, num_classes):
super(GAT, self).__init__()
torch.manual_seed(12345)
hns = [num_features] + hidden_channnels_list
conv_list = []
for idx in range(len(hidden_channnels_list)):
conv_list.append((GATConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True), ) # inplace表示是否将得到的值计算得到的值覆盖之前的值
self.convseq = Sequential('x, edge_index', conv_list)
self.linear = Linear(hidden_channnels_list[-1], num_classes)
def forward(self, x, edge_index):
x = self.convseq(x, edge_index)
x = F.dropout(x, p=0.5, training=self.training)
x = self.linear(x)
return x
def train(data, model, optimizer, criterion):
model.train()
optimizer.zero_grad() # 清空梯度
out = model(data.x, data.edge_index) # 执行一次前向传播
# 基于训练的节点计算损失
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 反向传播
optimizer.step() # 基于梯度更新所有的参数
return loss
def test(data, model):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # 采用可能性最高的进行预测
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 选择预测正确的标签
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算准确率
return test_acc
def main():
device = torch.device('cuda' if torch.cuda.torch.cuda.is_available() else 'cpu')
dataset = PlanetoidPubMed('/Dataset/Planetoid/PubMed', transform=NormalizeFeatures())
# print('data.num_features:', dataset.num_features)
data = dataset[0].to(device)
model = GAT(num_features=dataset.num_features, hidden_channnels_list=[400, 200, 100], num_classes=dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, 201):
loss =train(data, model, optimizer, criterion)
# print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test(data, model)
print(f'Test Accuracy: {test_acc:.4f}')
if __name__ == "__main__":
main()
结果如下图所示:

3.2 作业二
- 在边预测任务中,尝试用
torch_geometric.nn.Sequential容器构造图神经网络
代码如下:
import os.path as osp
import torch
import torch.nn.functional as F
from torch.nn import ReLU
import torch_geometric.transforms as T
from sklearn.metrics import roc_auc_score
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv, Sequential
from torch_geometric.utils import negative_sampling, train_test_split_edges
class Net(torch.nn.Module):
def __init__(self, in_channels, hidden_channnels_list, out_channels):
super(Net, self).__init__()
torch.manual_seed(12345)
hns = [in_channels] + hidden_channnels_list
conv_list = []
for idx in range(len(hidden_channnels_list)-1):
conv_list.append((GCNConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True), )
conv_list.append((GCNConv(hns[-2], hns[-1]), 'x, edge_index -> x'))
self.convseq = Sequential('x, edge_index', conv_list)
def encode(self, x, edge_index):
return self.convseq(x, edge_index)
def decode(self, z, pos_edge_index, neg_edge_index):
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1)
return (z[edge_index[0]] * z[edge_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t()
return (prob_adj > 0).nonzero(as_tuple=False).t()
def get_link_labels(pos_edge_index, neg_edge_index):
num_links = pos_edge_index.size(1) + neg_edge_index.size(1)
link_labels = torch.zeros(num_links, dtype=torch.float)
link_labels[:pos_edge_index.size(1)] = 1.
return link_labels
def train(data, model, optimizer):
model.train()
neg_edge_index = negative_sampling(
edge_index=data.train_pos_edge_index,
num_nodes=data.num_nodes,
num_neg_samples=data.train_pos_edge_index.size(1))
train_neg_edge_set = set(map(tuple, neg_edge_index.T.tolist()))
val_pos_edge_set = set(map(tuple, data.val_pos_edge_index.T.tolist()))
test_pos_edge_set = set(map(tuple, data.test_pos_edge_index.T.tolist()))
if (len(train_neg_edge_set & val_pos_edge_set) > 0) or (len(train_neg_edge_set & test_pos_edge_set) > 0):
print('wrong!')
optimizer.zero_grad()
z = model.encode(data.x, data.train_pos_edge_index)
link_logits = model.decode(z, data.train_pos_edge_index, neg_edge_index)
link_labels = get_link_labels(data.train_pos_edge_index, neg_edge_index).to(data.x.device)
loss = F.binary_cross_entropy_with_logits(link_logits, link_labels)
loss.backward()
optimizer.step()
return loss
@torch.no_grad()
def test(data, model):
model.eval()
z = model.encode(data.x, data.train_pos_edge_index)
results = []
for prefix in ['val', 'test']:
pos_edge_index = data[f'{prefix}_pos_edge_index']
neg_edge_index = data[f'{prefix}_neg_edge_index']
link_logits = model.decode(z, pos_edge_index, neg_edge_index)
link_probs = link_logits.sigmoid()
link_labels = get_link_labels(pos_edge_index, neg_edge_index)
results.append(roc_auc_score(link_labels.cpu(), link_probs.cpu()))
return results
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# dataset = 'Cora'
# path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', dataset)
# dataset = Planetoid(path, dataset, transform=T.NormalizeFeatures())
dataset = Planetoid('/Dataset/Planetoid/Cora', 'Cora', transform=T.NormalizeFeatures())
data = dataset[0]
ground_truth_edge_index = data.edge_index.to(device)
data.train_mask = data.val_mask = data.test_mask = data.y = None
data = train_test_split_edges(data)
data = data.to(device)
model = Net(dataset.num_features, [128], 64).to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
best_val_auc = test_auc = 0
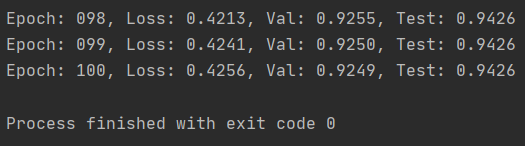
for epoch in range(1, 101):
loss = train(data, model, optimizer)
val_auc, tmp_test_auc = test(data, model)
if val_auc > best_val_auc:
best_val_auc = val_auc
test_auc = tmp_test_auc
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_auc:.4f}, '
f'Test: {test_auc:.4f}')
z = model.encode(data.x, data.train_pos_edge_index)
final_edge_index = model.decode_all(z)
if __name__ == "__main__":
main()
3.3 作业三
- 如下方代码所示,我们以
data.train_pos_edge_index为实际参数来进行训练集负样本采样,但这样采样得到的负样本可能包含一些验证集的正样本与测试集的正样本,即可能将真实的正样本标记为负样本,由此会产生冲突。但我们还是这么做,这是为什么?neg_edge_index = negative_sampling( edge_index=data.train_pos_edge_index, num_nodes=data.num_nodes, num_neg_samples=data.train_pos_edge_index.size(1))
4. 参考资料

若有收获,就点个赞吧
0 人点赞
