一、 大模型的切换
首先是这个界面左上角,在这里可以切换你所安装的模型。
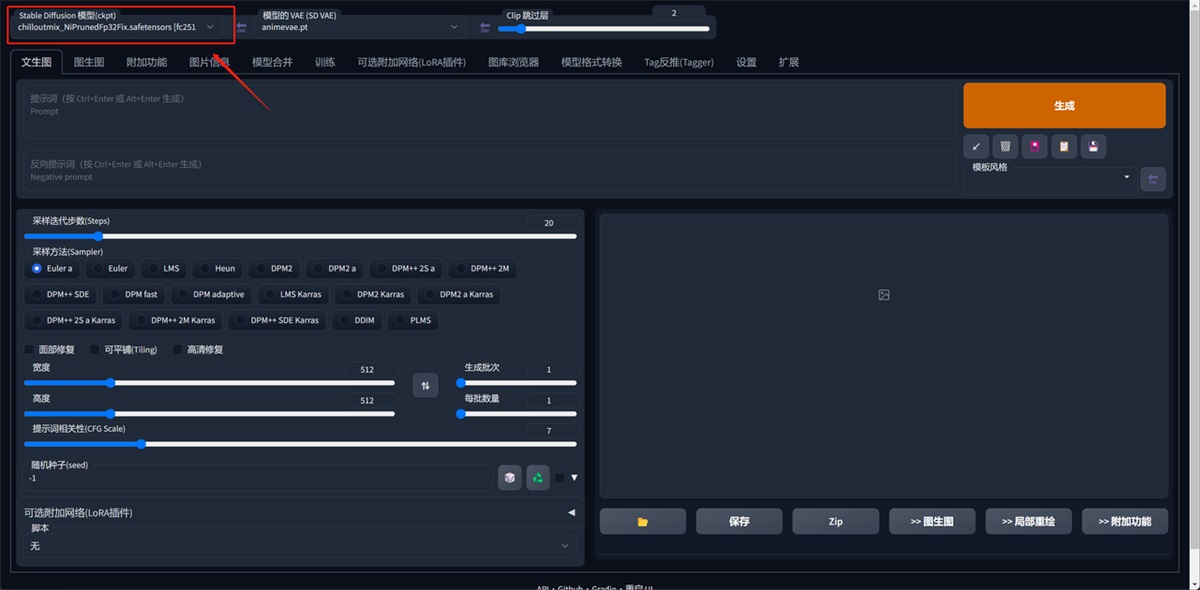
这里我先推荐一下我常用的模型网站:C 站: https://civitai.com/
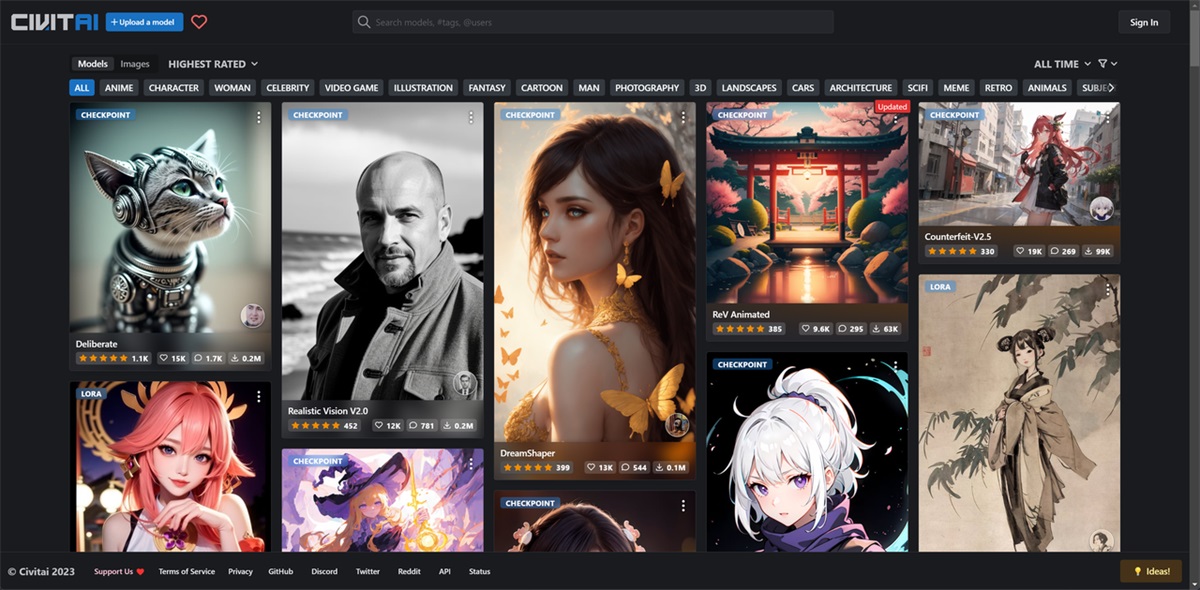
然后我们在 C 站上下载一些模型:

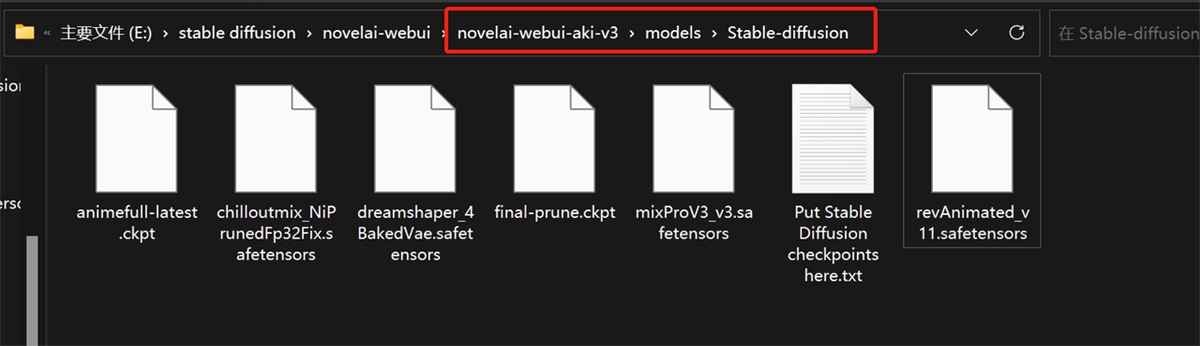
接下来就是安装了,很简单,把下载的模型放到这个路径文件夹中。然后刷新 web UI 界面(就是 SD 操作界面)
二、模型的 VAE(Sd 的 VAE)
VAE 的全称是 Variational Auto-Encoder,翻译过来是变分自动编码器,本质上是一种训练模型,Stable Diffusion 里的 VAE 主要是模型作者将训练好的模型“解压”的解码工具。
这里可以切换 VAE。一般情况下我们就选择第一个自动就行了。

在 C 站下载模型,在下载页面会有文件显示,如图。
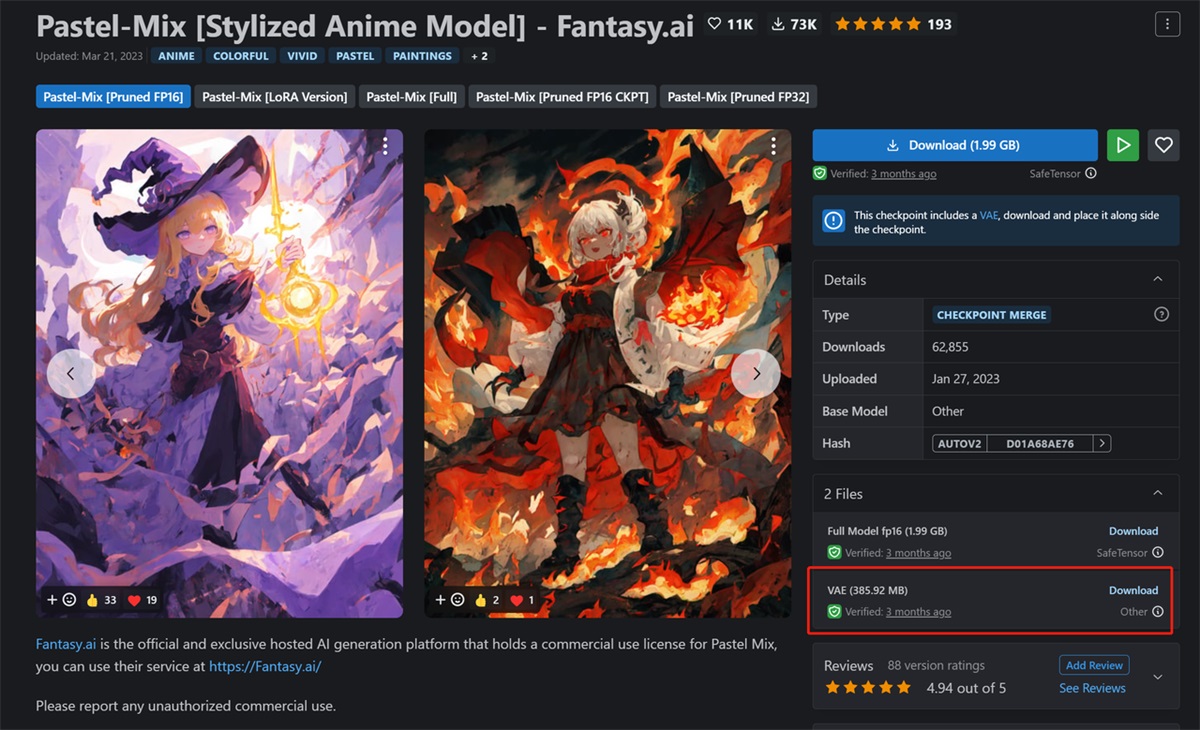
VAE 的安装路径看我这里,把下载的文件复制粘贴,然后把 web UI 界面刷新一下(就是 SD 操作界面)
总结:
- 总的来说就是你在 C 站上下载的模型有些内置就有 VAE 的属性(不需要下载 VAE 文件),有些没有内置下载的时候我们就把 VAE 文件下载。(VAE 文件一般大小在几百兆左右)
- VAE 的作用就是没有加载 VAE 的图片是灰灰的,加载之后就是会产生一个润色的效果,色彩更加丰富。
三、功能选项
这里我挑选几个重要的功能讲解下。
文生图,这里与 Midjourney 不同的是,SD 有一个反向关键词(意思是不要图片出现什么),文生图的关键词格式与 Midjourney 基本一致
文生图,这里与 Midjourney 不同的是,SD 有一个反向关键词(意思是不要图片出现什么),文生图的关键词格式与 Midjourney 基本一致。

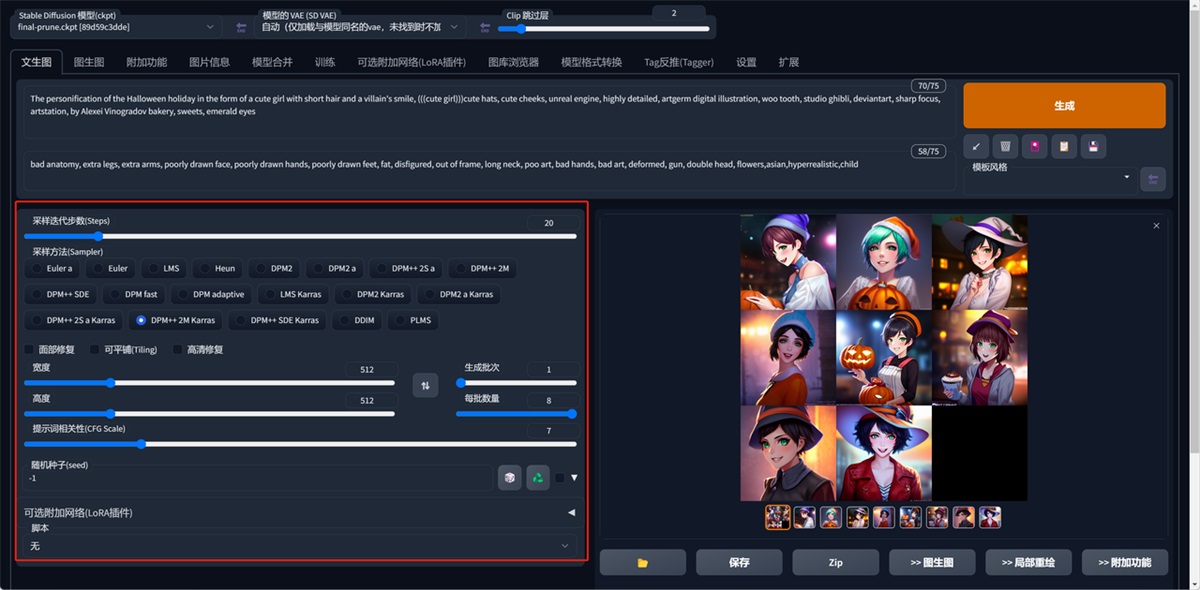
下面这块参数就是设置图片的一些基本参数,分辨率、尺寸等等,具体参数见下文。
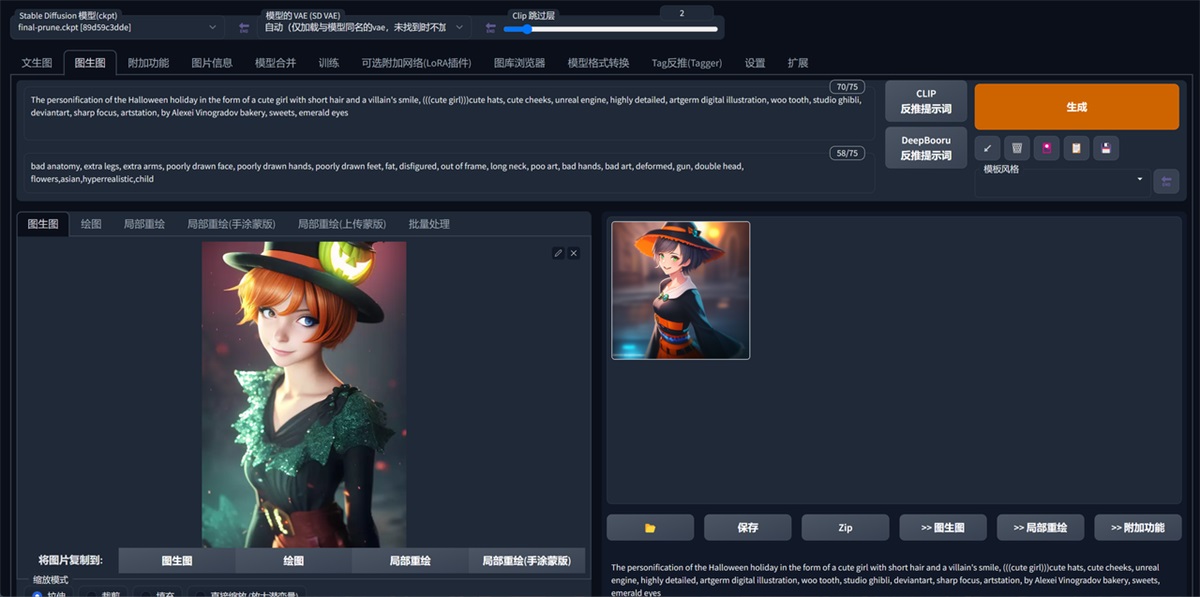
图生图,这个也很好理解,放参考图然后输入提示词,与其他 AI 绘画软件一致。
图片信息,意思是你用 SD 画的图,放在这里来,右边会显示这个图片的一些参数,包括关键词。
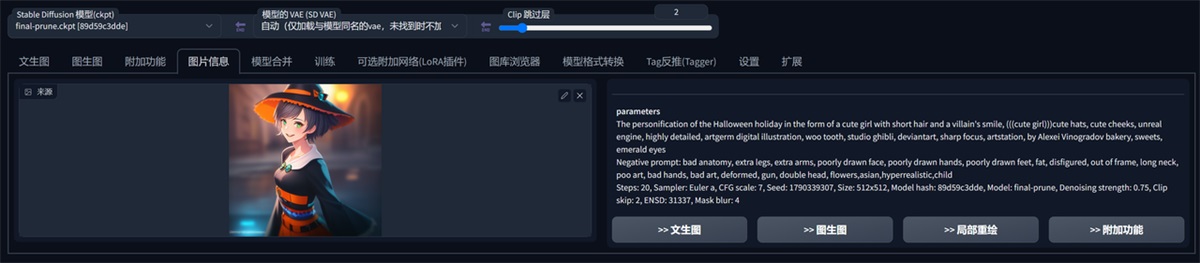
然后你可以选择右下角的一些功能,比如“文生图”。

模型合并,这个功能很厉害,后面我出一篇关于这个功能的教学,大致就是把多个模型混合起来。
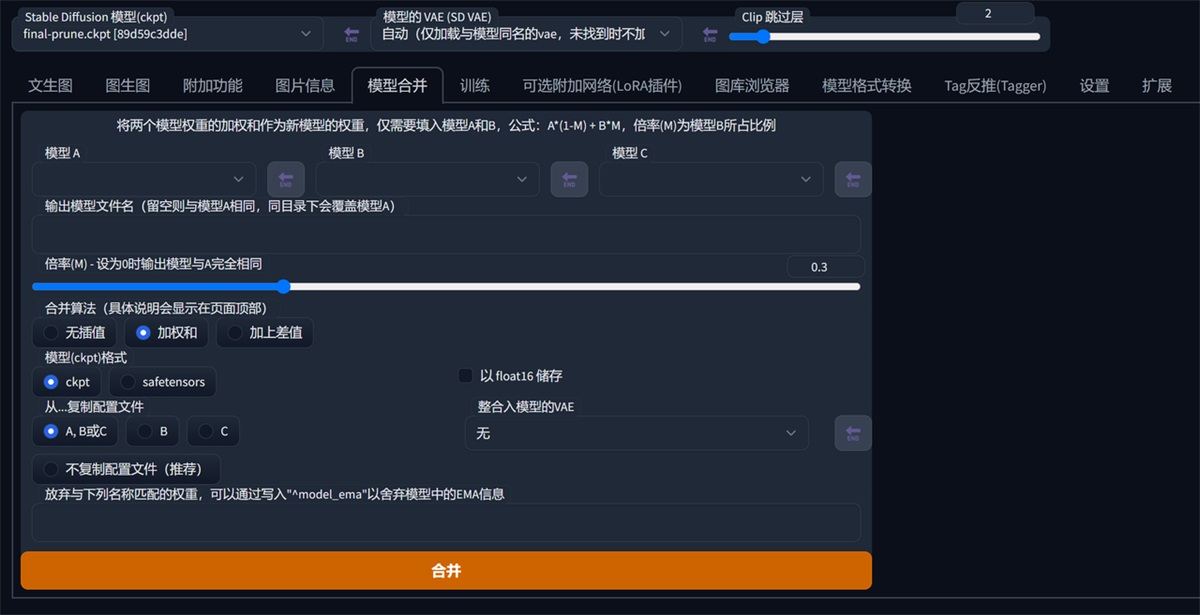
训练,这个就是训练自己的模型,新手用的比较少,后面可用作工作流的部署。(这个才是我推荐的核心哦)
设置,然后就是设置,大家自己去研究下就好了。
扩展,这个就是跟插件扩展相关的了,后面再讲。
四、提示词和反向提示词
提示词内输入的东西就是你想要画的东西,反向提示词内输入的就是你不想要画的东西。
提示框内只能输入英文,所有符号都要使用英文半角,词语之间使用半角逗号隔开。

一般来说越靠前的词汇权重就会越高,比如我这张图的提示词:
The personification of the Halloween holiday in the form of a cute girl with short hair and a villain’s smile, (((cute girl)))cute hats, cute cheeks, unreal engine, highly detailed, artgerm digital illustration, woo tooth, studio ghibli, deviantart, sharp focus, artstation, by Alexei Vinogradov bakery, sweets, emerald eyes。
万圣节假期的拟人化形式是一个留着短发和恶棍笑容的可爱女孩,可爱的帽子,可爱的脸颊,虚幻的引擎,高度详细,艺术种子数字插图,woo tooth,吉卜力工作室,deviantart,锐利的焦点,artstation,由 Alexei Vinogradov 面包店,糖果,绿宝石般的眼睛。
第一句关键词词组:万圣节假期的拟人化形式是一个留着短发和恶棍笑容的可爱女孩。那生成的图片主体画面就会是万圣节短发可爱笑容女孩
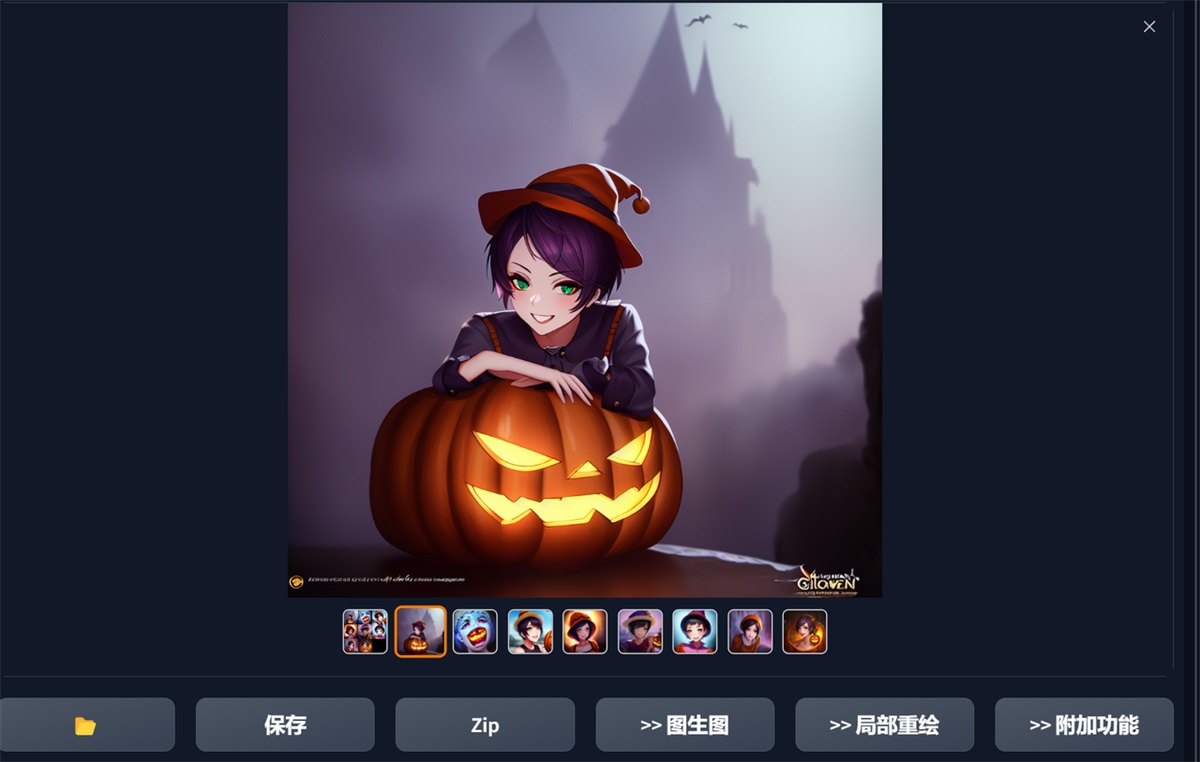
这里可能有用过 Midjourney 的小伙伴们就有疑问了,(((cute girl)))是什么意思,为啥有这么多括号,我来为大家解答下,这个是权重调节,类似 Midjourney 的 ::
① 最直接的权重调节就是调整词语顺序,越靠前权重越大,越靠后权重越低,上面说过。
② 可以通过下面的语法来对关键词设置权重,一般权重设置在 0.5~2 之间,可以通过选中词汇,按 ctrl+↑↓来快速调节权重,每次调节为0.1,也可以直接输入。

③ 加英文输入的(),一个括号代表这组关键词的权重是 1.1,两个括号是 1.1*1.1 的权重,不要加太多了哈。可以结合第二点固定权重,比如(((cute girl:1.2))),那这个关键词的权重就很高了。
五、功能按钮
我们来介绍下右边这几个功能,生成就不说了,输入关键词生成就跑图了。

第一按钮的意思是读取你上一张图的所有参数信息(包括关键词),比如你画一张图之后,关掉了软件,再次启动点击这个就会把参数复制进来。
第二个按钮就是删除了,清空关键词;这里可以和第一个按钮结合用哦
第三个按钮就是模型选择管理
这个按钮就是点击就会出现这些功能,你安装的模型和 Lora 都可以在这边调整。
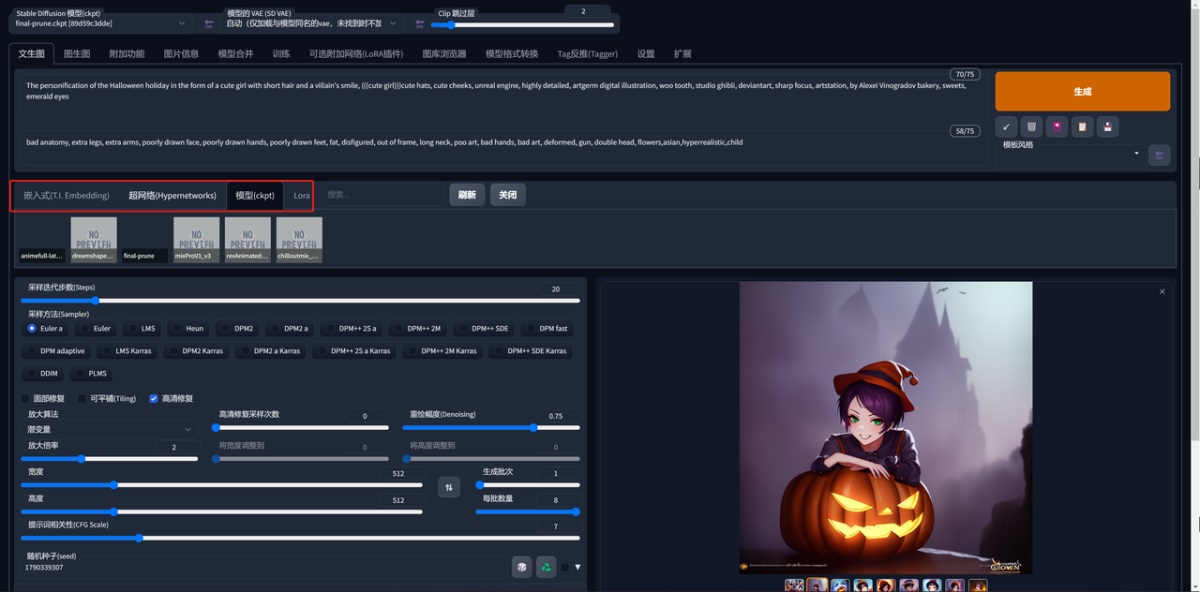
:::warning
💡小知识:这里可以把你生成的图片添加到模型的封面上,方便你后面看这个模型的效果,看我怎么做:
:::
找到这个模型的名称,然后我这里是跑出来一张图片的,点击这个按钮(lora 一样)
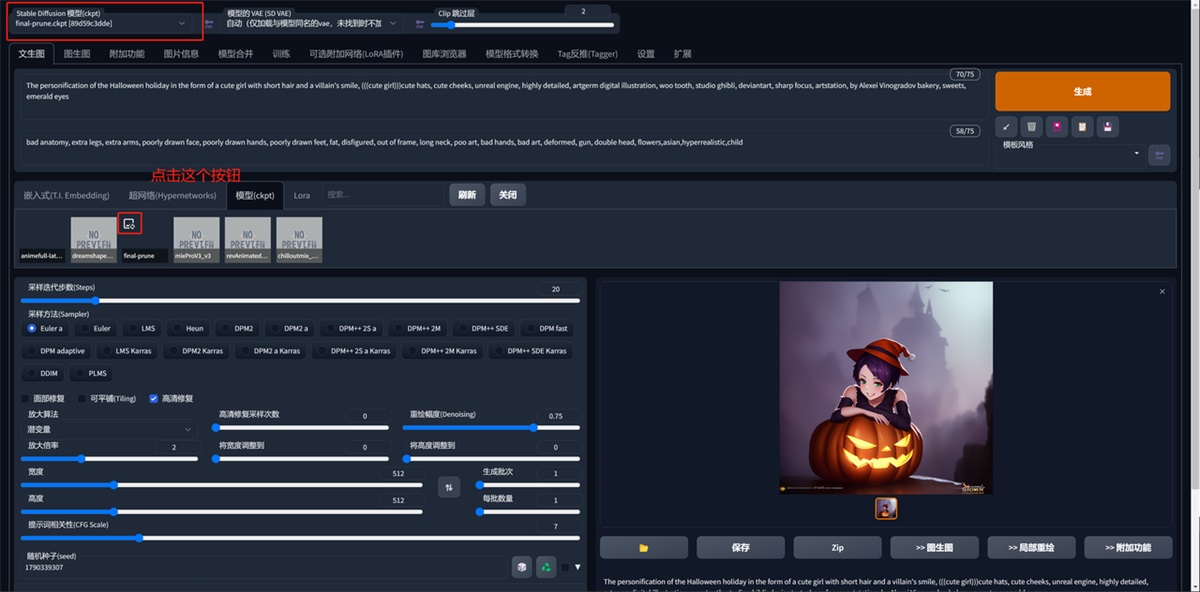
最终效果:

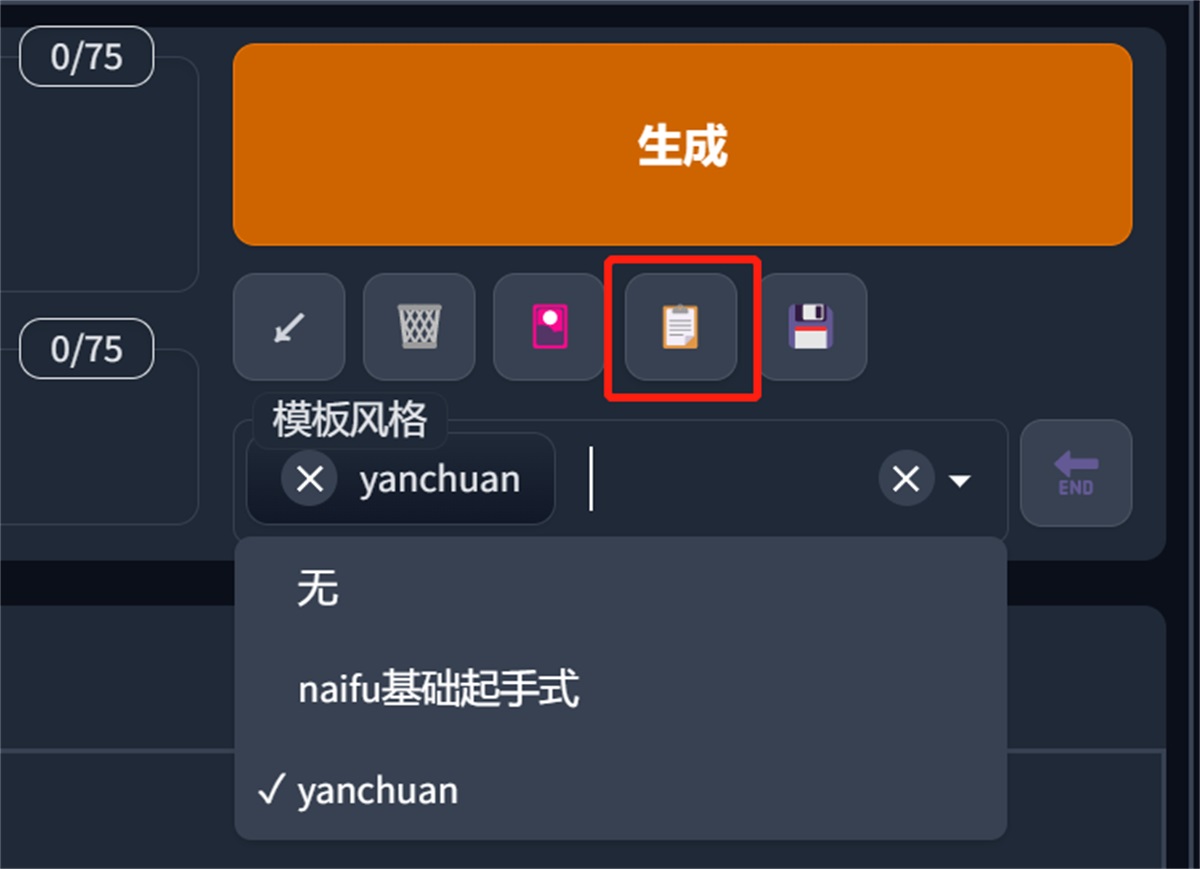
后面两个就是一个提示词模板功能:
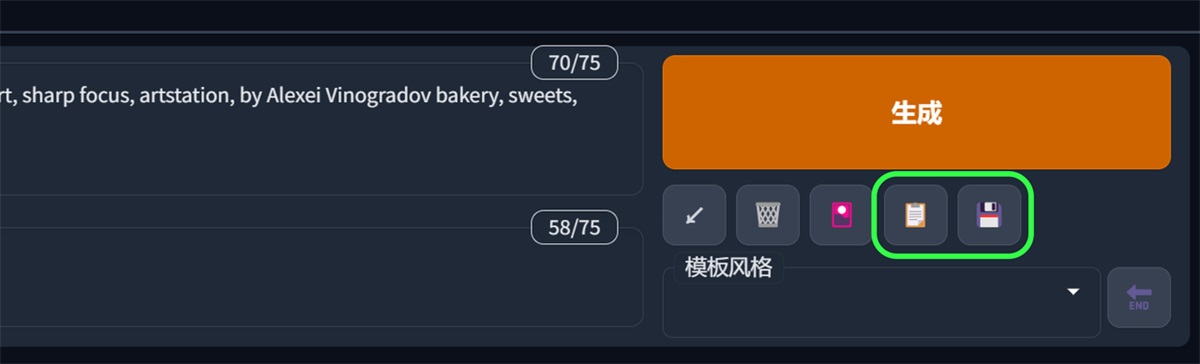
我们可以先点最后一个按钮,把现在的关键词创建一下,取个名字
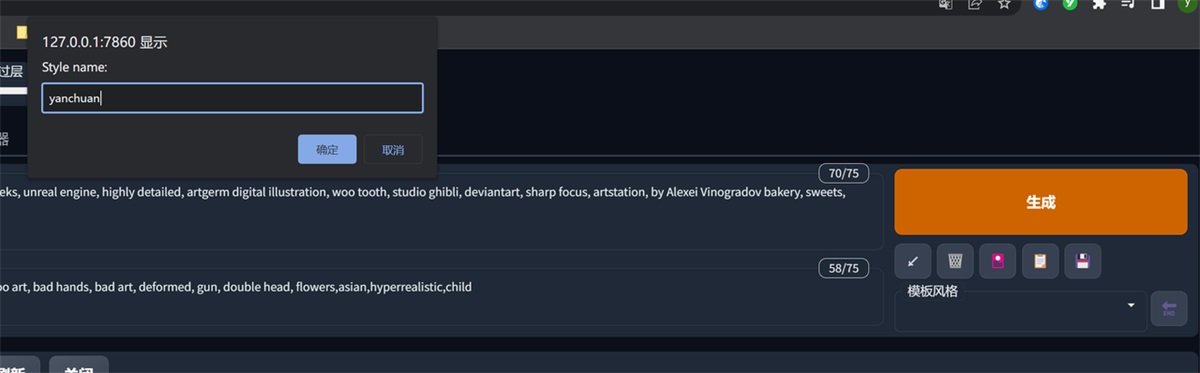
然后在模板风格这里选中我们刚刚创建的模板(可以多选)

选中之后按一下第四个按钮,我们创建的关键词就被填入进去了,这块收工!
六、采样步数
一般来说大部分时候采样部署只需要保持在 20~30 之间即可,更低的采样部署可能会导致图片没有计算完全,更高的采样步数的细节收益也并不高,只有非常微弱的证据表明高步数可以小概率修复肢体错误,所以只有想要出一张穷尽细节可能的图的时候才会使用更高的步数。(加大这个会导致出图变慢)
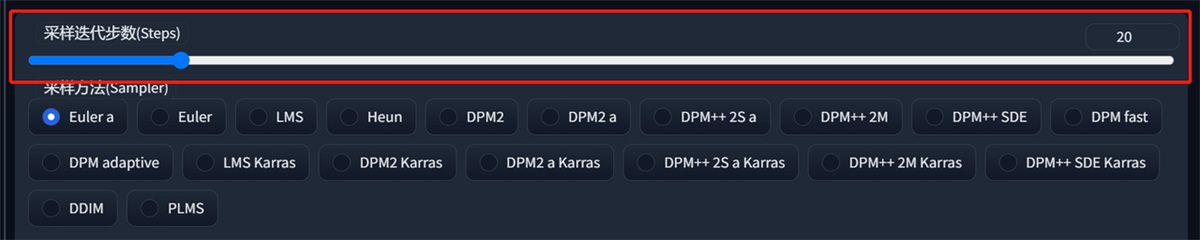
七、采样方法
Stable diffusion webui 是 Stable diffusion 的 GUI 是将 stable diffusion 实现可视化的图像用户操作界面,它本身还集成了很多其它有用的扩展脚本。
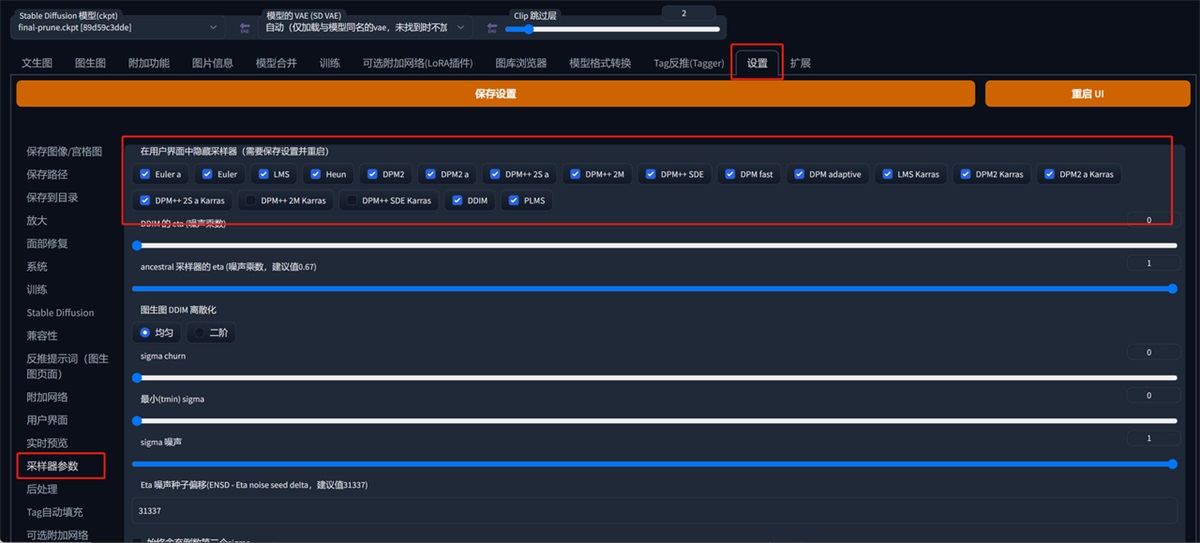
SD 的采样方法有很多,大家有兴趣了解的可以去知乎看看@刘登宇的一篇文章《stable diffusion webui 如何工作以及采样方法的对比》。这里我们只介绍两个种常用的。

这里的采用方式有很多,但是我们常用的就那几个,我们可以去设置里面把不需要用到的关掉,不展示在这个界面中。然后点击右边的重启 UI 就好了。
8. 高清修复和图片尺寸参数
前面两个做个简单的介绍,面部修复对写实的风格有点效果,可平铺就不要用了,生成的图片很奇怪,可以自己试试。

我们说说高清修复,高清修复的意思是把基础生成的图片,按照你选择放大的倍率放大到指定分辨率之后再重新绘制图片,受到你重复幅度调节的数值影响。
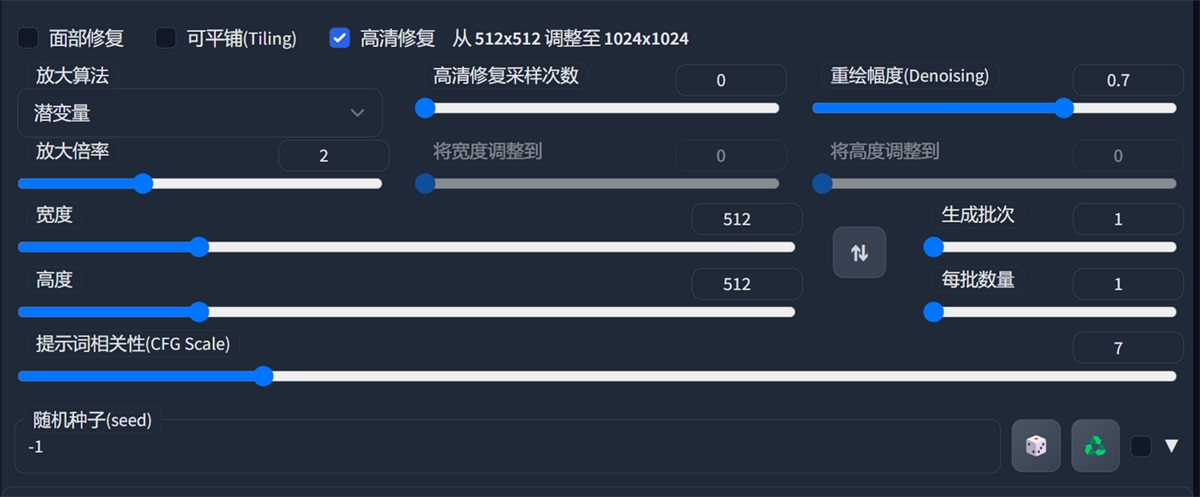
宽度、高度就是图片的长宽比,很容易理解,生成批次和数量就是几批,一批几张图,配置好的可以直接拉满,增加效率哦。
提示词相关性:图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示(根据模型),但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。
默认未选中高清修复是这样的,当前图片的参数。
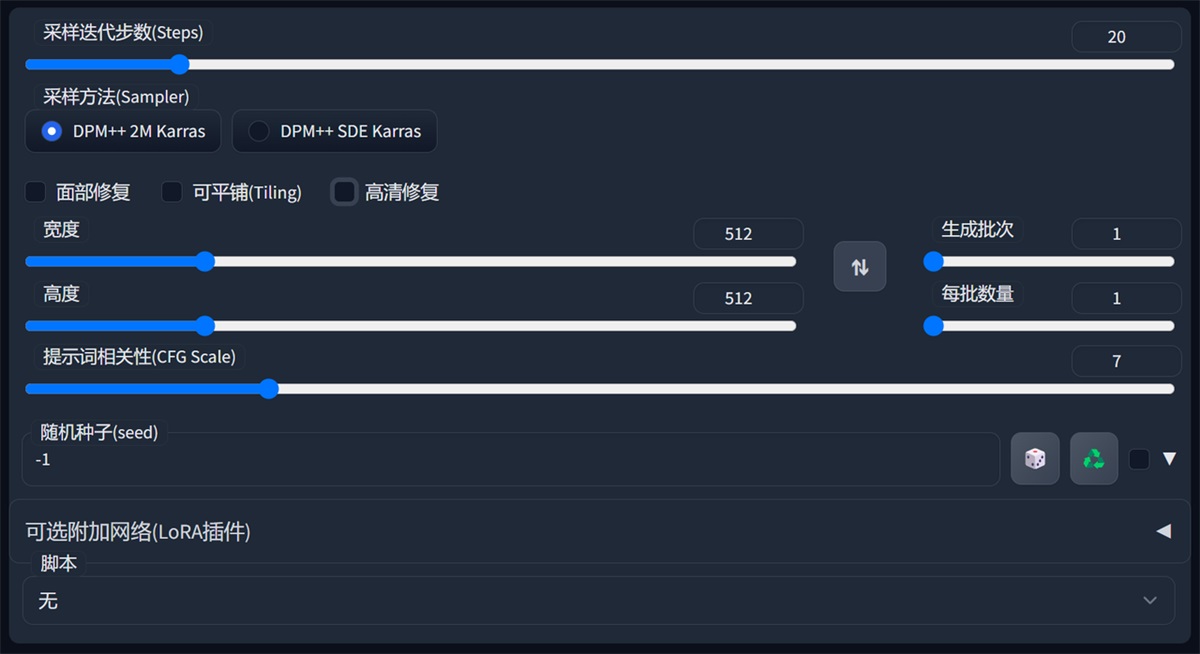
9. 随机种子(seed)
这个功能与 Midjourney 的 Seed 功能一样。
随机数的起点。保持这个值不变,可以多次生成相同(或几乎相同,如果启用了 xformers)的图像。没有什么种子天生就比其他的好,但如果你只是稍微改变你的输入参数,以前产生好结果的种子很可能仍然会产生好结果。
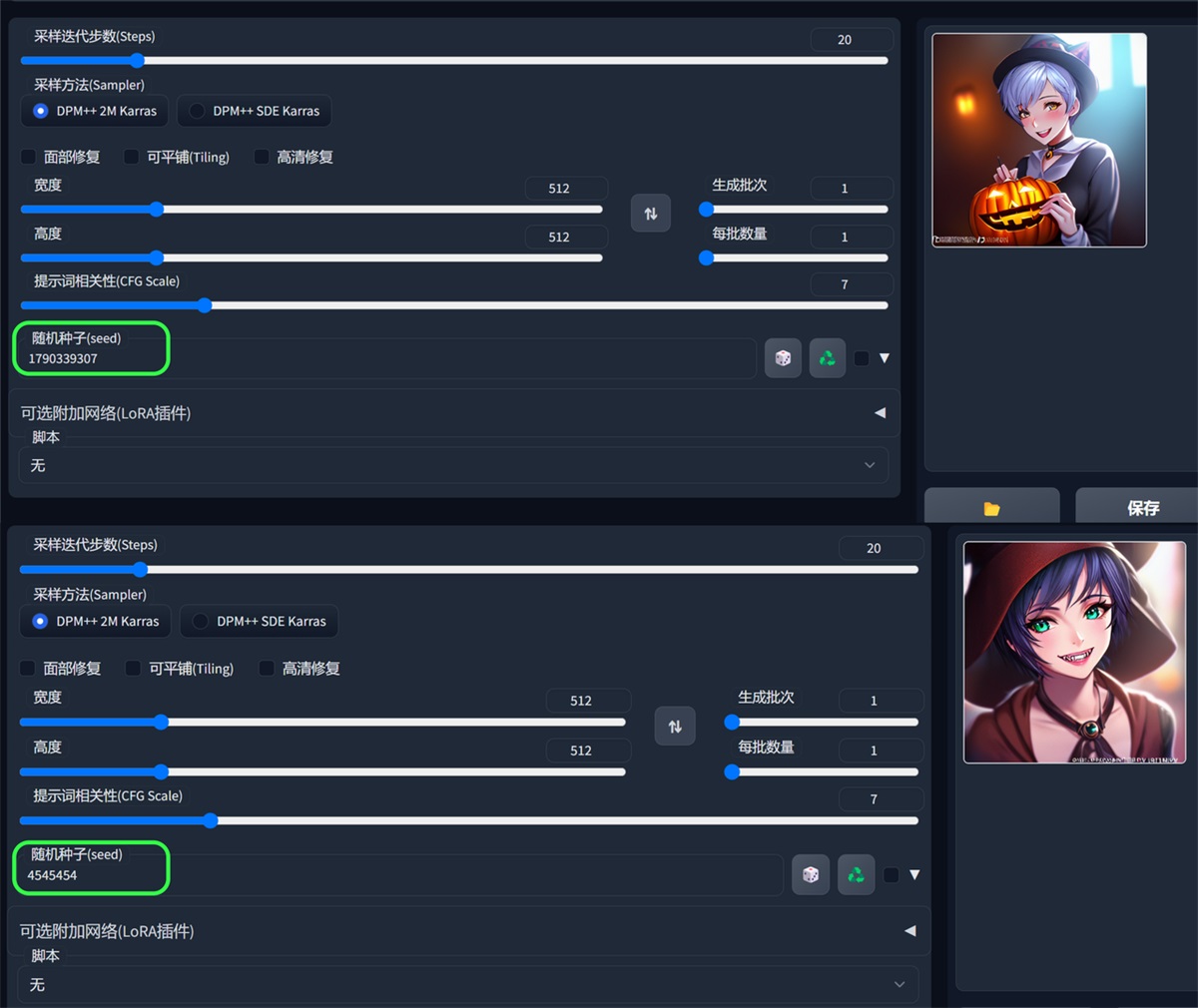
输入不同的种子,生成的图片不一样,seed 值一样,那生成的图片也是一样。
差异随机种子,需要勾选这个按钮:
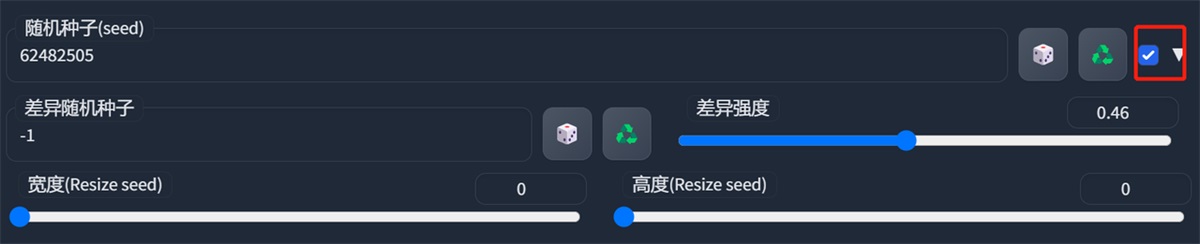
这个功能是固定一个种子,然后调整差异强度来生成图片,因为是固定的 seed 值,所以生成的图风格都是类似的。
直接看图吧。
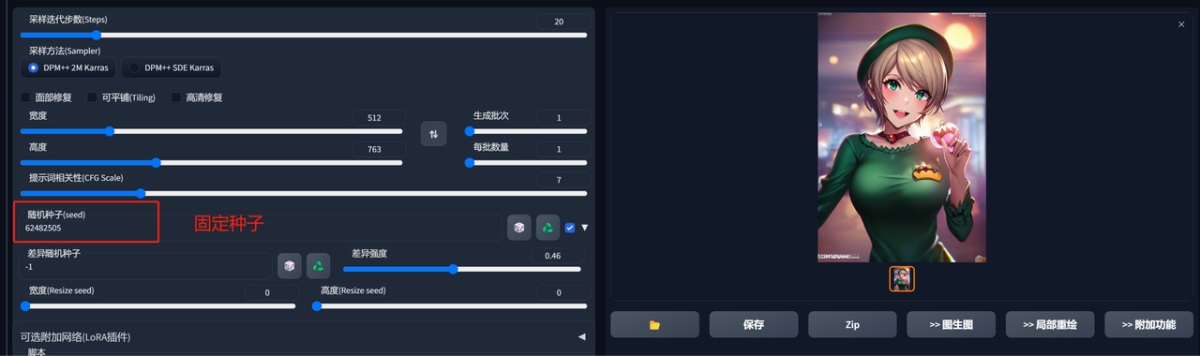
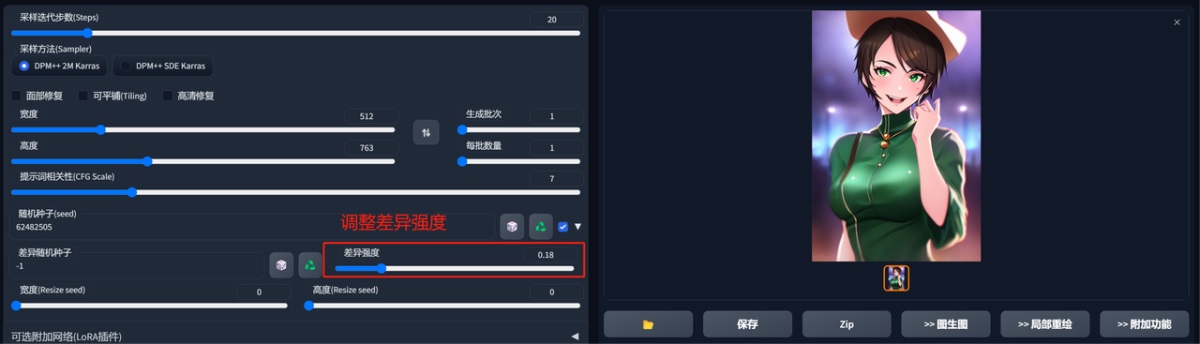
这边的几个功能都很简单,大家尝试下就能理解了,那基础操作我们就先讲到这里,大家赶紧玩起来吧!!

七、结语
这篇入门教学就先讲到这里,大家先消化一下这篇文章的内容。
如果你对Stable Diffusion感兴趣或者想深入的了解AI绘画,请加入我们的俱乐部!和1000+AIGC研究员一起探讨交流!学习分享!


:::warning AIGC研究社俱乐部周边🌈
工具站(资源导航工具):www.aigcyjs.com
帕克的博客(AI黑科技分享):blog.aigcyjs.com
:::

若有收获,就点个赞吧
0 人点赞
