人们常说“前端开发”(Front-End Development)、“后端开发”(Back-End Development)等术语,但很少会留意所谓“前端”与“后端”究竟指什么。其实它们都属于“Web 系统”的范畴,即 “Web 前端” 与 “Web 后端”。
编译器领域也有前端与后端的概念,编译器前端负责词法分析、语法分析、语义分析部分,后端负责中间代码生成、代码优化、目标代码生成部分。所以说在描述 Web 开发相关的“前端”与“后端”的时候,最好都带上前缀 Web,如“Web 前端开发”、“Web 后端开发”,显得更专业一些。
在继续之前,我们首先明确下 Web 系统的一些基本概念。
1.1 internet 与 Web
internet (因特网 / 互联网)是物理意义上的概念,意为全球最大的计算机互联网络,设备连上因特网后,可互相收发数据,各种应用也在 internet 网络通信的基础之上进行(如 Web、邮件、类似微信 QQ 的 IM 应用等等)。
Web 全称为 World Wide Web,也简称 WWW,中文称为“万维网”,是一个互相链接的文档系统。用户可以通过文档里的“链接”,找到另一个文档,这里的文档与文档之间的链接之间的组合,形成了巨大的“网络”。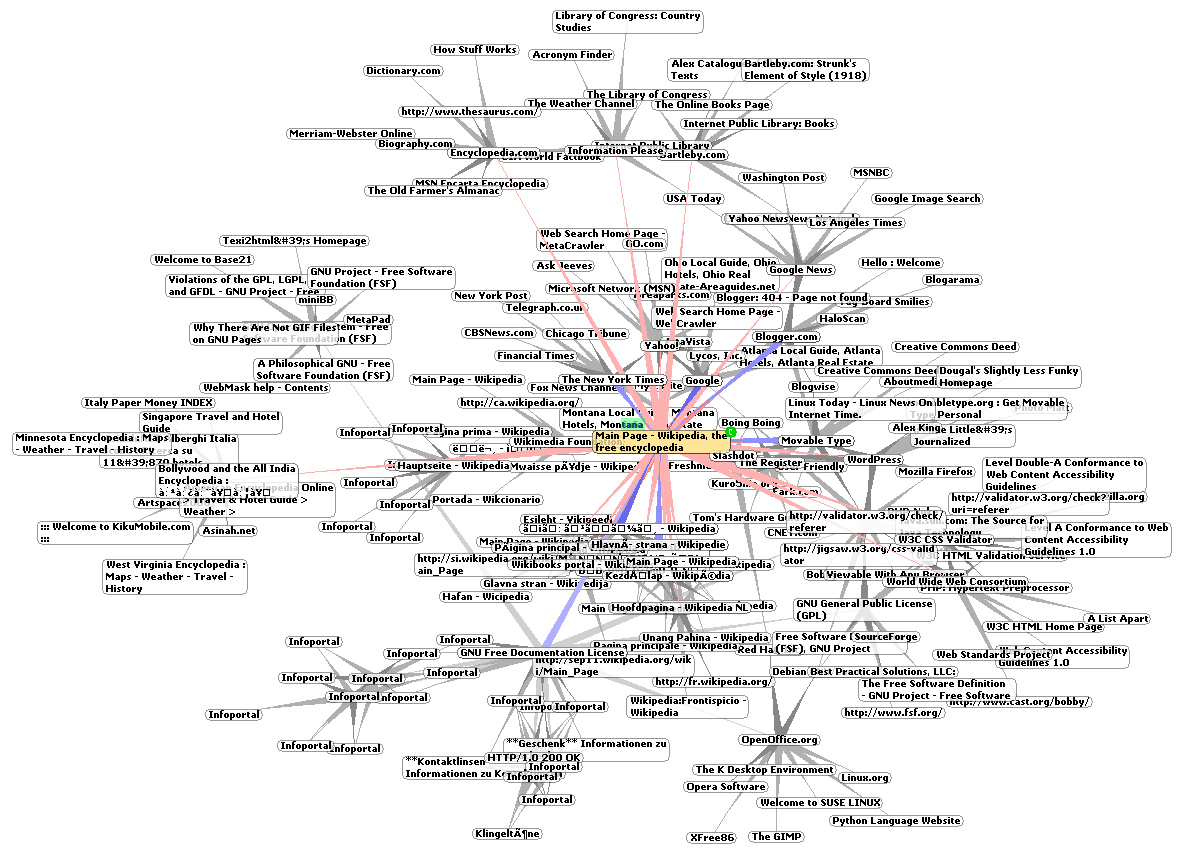
超链接组成的网络,来源 维基百科
Web 开发,也是围绕着这样的一个文档系统展开各种工作。
1.2 超文本与超链接
上面说到的“文档系统”概念十分笼统,它可以是 PDF、可以是 Word 的 docx 格式、也可以是其他各种各样的文件,我们接触最多的还是 网页,网页是专门为万维网设计的一种文档类型。
网页由超文本构成,超文本与一般文档的区别,主要在于它强调其中超链接的属性,用户可借助超链接跳转到其他的网页,也可以通过超链接加载到文档内嵌的资源,以此构造出上述的文档网络。
我们需要一些方式去表达超链接,链接实现的方式多种多样,类似某些海报上的地址、QQ号、微信文章链接、公众号、微信小程序码等,凡是可以帮助用户找到某个资源的东西,我们都可以称为“超链接”。
为了实现不同平台的链接统一,早期的万维网设计者们达成了统一的超链接标准,名叫 URL(Uniform Resource Locator,统一资源定位符)。URL 是一段特定格式的字符串,俗称“网址”,告诉计算机如何获取某一资源。三个字母分别为三个单词的缩写,对应了它的三个属性:
- Uniform: 统一的标准
- Resource: 针对某个特定资源,如文档、图片、音频、视频等等文件
- Locator: 定位器,也就是获取这个资源的途径和方法
以下是一些常见的 URL:
- http://www.baidu.com/
- http://202.115.72.8:80/dzzn.htm
- https://m.weibo.cn/u/1251000504?jumpfrom=weibocom
- https://zhuanlan.zhihu.com/p/22561084
- https://tools.ietf.org/rfc/rfc2616.txt
- https://cs50.harvard.edu/college/2019/fall/guide.pdf
- ftp://ftp.freebsd.org/pub/FreeBSD/
在 URL 的定义下,网页以一种“资源”(即一段数据、一个文件)的形式存在,浏览器访问某个 URL,首先获得的也正是这一段超文本数据,然后再解析与展示这段数据的内容。
一个网页组成不仅限于超文本,还可能包括样式表、脚本、图片、音频、视频等等,乃至于内嵌新的网页(递归套娃)。它们在超文本中以特定的元素存在,浏览器在解析超文本时,若遇到对应的元素,则会访问元素中定义的 URL,拉取对应的资源。
URL的具体语法最早是在 RFC 1738 中定义的,一段URL符合以下格式:
URI = scheme:[//authority]path[?query][#fragment]
一台计算机向另外一台计算机请求资源时,需要确认三点信息,这三点信息分别与 URL 的组成成分的关系如下:
- 该找谁获取资源:服务器的IP/域名、端口号 (authority)
- 怎么样获取资源:通信协议(scheme)
- 获取对方什么资源:资源路径 (path)
1.3 超文本传输协议
由上节内容我们可以发现,URL 的 scheme 部分各不相同,我们可以看到 http / https / ftp 三种协议。其中最常见的,还是 HTTP 或 HTTPS 协议,HTTPS 与 HTTP 的区别在于,HTTPS 在 HTTP 的基础上,多了一层安全加密传输的包装。所以说,对于 Web 开发而言,最最核心的,还是 HTTP 协议。
小知识: 在互联网早期,在 HTTP 之前,还流行一种名叫 gopher) 的协议,现在基本已淘汰了(目前安全领域会 用 gopher 来做 SSRF 攻击)。
HTTP 协议全称 Hypertext Transfer Protocol,中文名是“超文本传输协议”,这一协议主要是针对超文本的数据传输而设计的。HTTP 协议分为 HTTP 请求与 HTTP 响应两个过程,客户端向服务端发送 HTTP 请求,服务端收到请求处理后,将对应数据返回到客户端。
类似这样由客户端和服务端组成的应用形态又叫客户端-服务器架构,英文简称 C/S 架构,如图:
图源:万维网是如何工作的 - MDN
这里我们只做一个概览,具体协议细节暂不做深究,若想更深入地了解,可以阅读 MDN 官网上的教程:万维网是如何工作的 - MDN。
1.4 Web 浏览器
Web 浏览器是我们最常用的软件之一,在不知不觉之中你就可能有用到它,然而在习以为常以后,人们常常会忘记它究竟是什么样的存在。所以这里我们需要做的,是从回归本源的角度再认识它。
从回归本源的角度来看,浏览器就是一个浏览网页的工具,它工作在上述 C/S架构 模型的客户端“Client”这一侧,帮助我们请求某个目标页面的网址(URL)、下载页面和嵌入的资源、展示页面内容供我们浏览。常用的浏览器至少包含三个元素:导航条、地址栏、展示超文本的内容区域。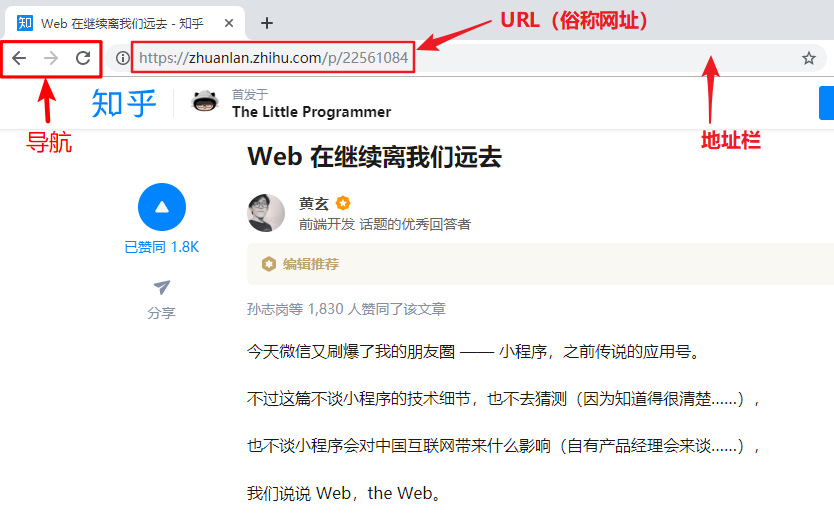
在客户端开发中,系统为应用提供了 WebView 组件,WebView 相当于一个隐藏了地址栏和导航的浏览器,主要用途是在 App 中嵌入网页内容。
随着手机性能的提高,HTML5 网页在移动端体验越来越好,有的 App 直接用 WebView 承载应用向的逻辑,这样的 App 又叫作 Hybrid App。
Hybrid App 之手机QQ的“兴趣部落”
1.5 Web 服务器
我们常说的“服务器”一般指的是硬件层面的机器,而 “Web 服务器” 并不是指某台具体的机器,而是和浏览器一样,属于应用软件层面的概念,它工作在 C/S 架构 的 Server 这一侧,负责接收客户端的请求,生成响应并返回给客户端。
客户端请求与响应的形态以 HTTP 请求与 HTTP 响应为主。前面我们提到,Web 主要依赖 HTTP 协议工作,但随着 Web 的发展,还涉及到 WebSocket、WebRTC 等特定应用领域的协议。其中细节较为繁杂,不太适合在入门时展开,所以这里只讨论 HTTP 协议部分,待你对这里涉及的主干知识有所把握的时候,再入手也不迟。
1.5.1 原始形态
最早期的网站提供的资源都是“静态”的,在网站中以文件系统的“文件”和“文件夹”的概念组织所有的资源,每一个资源在文件系统中都有一个确定的“文件路径”。访问某个资源的过程,也正是从远程服务器的文件系统中拉取某个文件数据的过程。
这里举一个例子:中科大为教师提供了一个主页服务器(http://staff.ustc.edu.cn/),它是一个完整的网站。每一位老师都可以建立一个属于自己的课程或个人、实验室介绍的子站点。
搜索引擎随手找到两个“静态网站”的例子:
- 计算机体系结构课程:http://staff.ustc.edu.cn/~comparch/
- 金属稳定同位素实验室:http://staff.ustc.edu.cn/~fhuang/
它们对应的本地目录结构是这样的: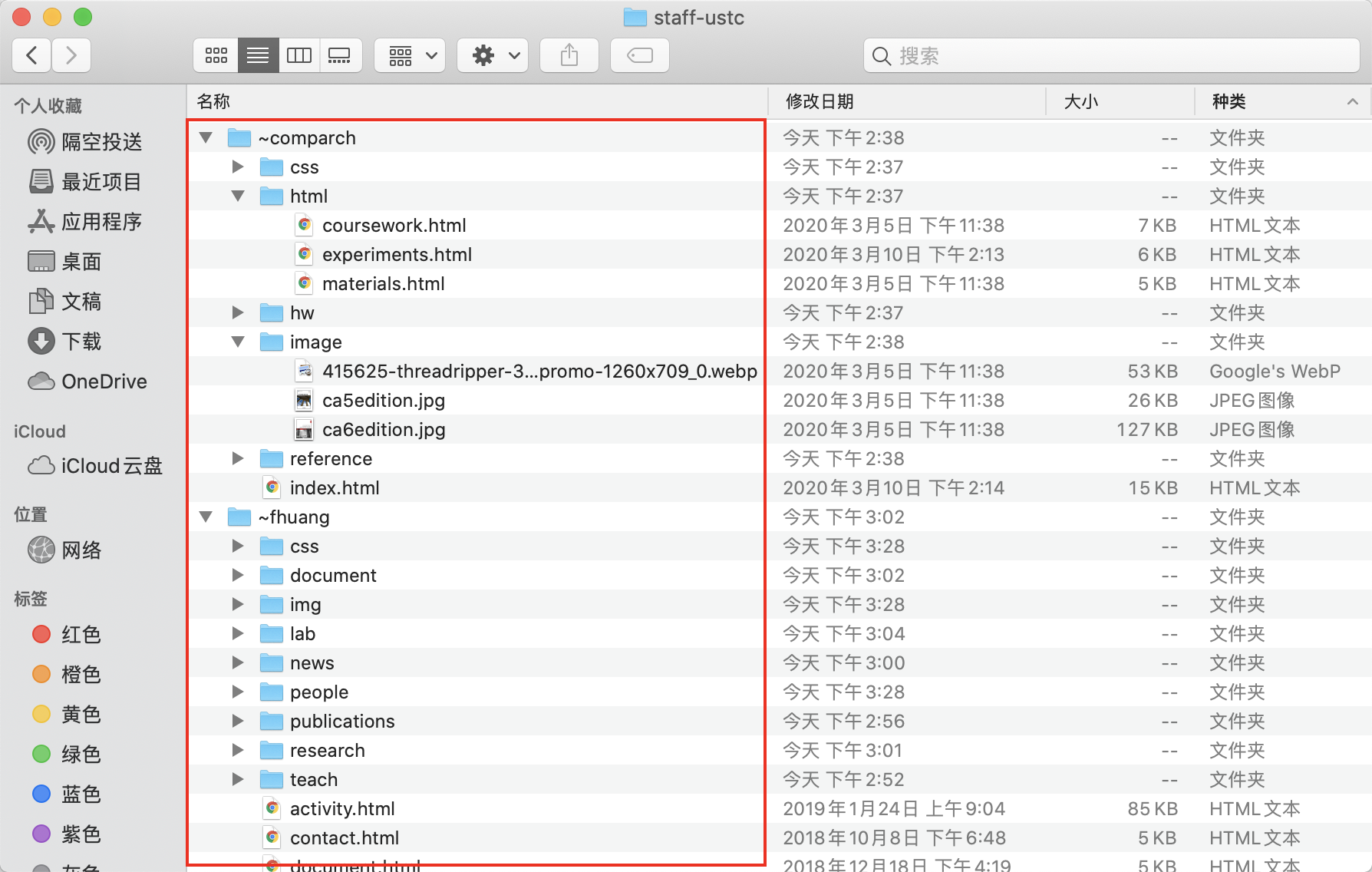
http://staff.ustc.edu.cn/ 的目录结构
Web 服务器要做的,便是根据请求 URL 中的 path,和站点在文件系统的根路径(WebRoot)拼接,形成对应资源在文件系统中的完整路径,然后读取这个路径的文件数据,将数据以 HTTP 响应的形式返回给客户端(浏览器)。
一般 Web 服务器软件会部署在机房的一台一直保持不关机运行的机器上,用户可以用 FTP 协议访问服务器,上传下载站点对应的资源文件,机器上的 Web 服务器软件会配置好网站的 WebRoot、域名、端口等信息。
在 http://staff.ustc.edu.cn/ 你可以看到对应的说明:
http://staff.ustc.edu.cn/ 主页
1.5.2 当下形态
Web 发展到现在,已不仅仅是传统的文档资源分享与链接系统。基于文档的动态脚本(JavaScript)能力、后端动态生成数据的能力,Web 体系已衍生出一种新的应用形态:Web App。
对 Web App 来说,服务器端也不仅有简单的读取文件返回数据的功能,需要承载许多业务流程和数据交互,且可能涉及到巨大请求量的处理(比如淘宝)。由此,人们对 Web 服务器的功能与性能,有了更多的要求。这一切不是一个软件就能实现的,而是多个软件组成的完整应用架构(技术栈)。
在这个背景下的 Web 服务器软件,除了读取静态文件并输出以外,还需要做一些请求分发的工作,涉及规则匹配与路由分发、协议转换、请求转发(反向代理)等步骤,对应调用后端程序的处理逻辑。后端程序维护与用户的访问会话 (session),将用户的请求,转向对应的业务逻辑处理,这其中可能涉及到数据库数据的增删改查操作,还有对其他各种服务(缓存、消息队列、支付 API 等等)的调用。
实现 Web 服务和后端的逻辑,并不局限于特定的编程语言,只要按照对应协议(主要是 HTTP)处理数据即可。业界有但不限于 Java, Golang, PHP, PHP, Node.js, Ruby, C#, Rust, C++ 等语言下的后端实现。代码与架构的复杂程度,取决于业务的复杂度和站点的访问压力。
后端工程师通常需要根据业务形态、语言生态、开发效率、维护难度等方面综合考虑,得出一套适合当下业务模式的后端方案。因此后端的领域也是千奇百怪,满足所有场景的银弹是不存在的。
1.6 理念
Web 技术的方方面面都透着它的核心理念,那就是开放(Open)、去中心化(Decentralized)。在 internet 之下,任何人都可以部署服务器发布网站,任何网站内容都能相互链接,任何厂商都能开发浏览器和服务器,开发者们通过这样的约定,共同构建属于全人类的信息网络。
保持这样的开放需要的是标准化,万维网联盟 World Wide Web Consortium (W3C) 正是面向 Web 标准化工作的一个非盈利组织,通过标准解决不同平台、技术的不兼容问题,促进网络信息的顺利完整流通;另外还有一个由浏览器厂商发起的组织 Web Hypertext Application Technology Working Group (WHATWG),相较于 W3C,WHATWG 事实上决定了 Web 的未来发展方向。
这也体现了 Web 的设计初衷和当下的定位的差异,原教旨的 Web 开发,核心点在于一个去中心化、分布式的文档资料库,秉承着“知识属于全人类,应该尽可能开发普惠”的朴素愿景;而更多的时候,人们 Web 的价值在于一个与人连接的业务系统,核心在于“解决业务问题的工具”,在跨平台应用开发技术中,Web 在开发效率和兼容性方面占据了极大优势,也意味着绝大多数的开发者,并不太 care Web 作为资料库的那部分角色的细节。
在价值的驱动下,在中国大陆通行的是类似微信的封闭生态,更倾向于封闭与管控,而不在于开放与互联。为实现商业利益的最大化,它把蓬勃发展的 Web 技术作为辅助客户端表达的一种工具,对用户隐藏了 URL 等相对复杂概念,取而代之的是笼统的“链接”和二维码/小程序码等只能在平台内通行的链接。微信所谓的“开放“的前提,在于一切都在它的控制之下,将生态牢牢控制在手中。
作为 Web 开发者,虽说理想总要对现实作出让步,无论于内容还是技术,尽可能让其接近互联网开放、普惠、人人都可平等地接收知识的初衷,能走得更远。尤其值得关注的是,类似微信这样的 App,如公众号文章、小程序等场景,还是重度依赖 Chromium 与 iOS 的 WKWebView,所以也受制于 Web 技术的发展。
1.7 分工
Web 开发一般我们也按前端与后端分工:
- Web 前端:主要负责 浏览器/WebView 端的页面开发,主要处理文档与内容的展示,以及页面与用户的交互的问题
- Web 后端:负责服务器端的架构与业务开发,着力于如何生成与输出前端需要的内容,还有与前端需要的各种后台业务逻辑的接口(如用户会话的登录与退出、订单、用户输入内容的处理等等)、相关软件的底层开发
细分下还会涉及到运维、还有互相配合的产品、设计、测试的角色等等。
由于技术的发展,前后端的边界事实上越来越模糊,前端也不仅仅是 “Web 前端”,因此也有了类似 “Web 全栈工程师” 的角色,以 Web 开发为核心,不设限地去承接和处理各类 Web 系统相关的问题。

若有收获,就点个赞吧
0 人点赞
