- 66 | 不断在表中插入数据时,物理存储是如何进行页分裂的
- 67 | 基于主键的索引是如何设计的,以及如何根据主键索引查询
- 68 | 索引的页存储物理结构,是如何用B+树来实现的
- 69 | 更新数据的时候,自动维护的聚簇索引到底是什么
- 70 | 针对主键之外的字段建立的二级索引,又是如何运作的
- 71 | 插入数据时到底是如何维护好不同索引的B+树的
- 72 | 一个表里是不是索引搞的越多越好?那你就大错特错了
- 73 | 通过一步一图来深入理解联合索引查询原理以及全值匹配规则
- 74 | 再来看看几个最常见和最基本的索引使用规则
- 75 | 当我们在SQL里进行排序的时候,如何才能使用索引
- 76 | 当我们在SQL里进行分组的时候,如何才能使用索引
- 77 | 回表查询对性能的损害以及覆盖索引是什么
- 78 | 设计索引的时候,我们一般要考虑哪些因素呢?(上)
- 79 | 设计索引的时候,我们一般要考虑哪些因素呢?(中)
- 80 | 设计索引的时候,我们一般要考虑哪些因素呢?(下)
- 81 | 案例实战:陌生人社交APP的MySQL索引设计实战(一)
- 82 | 案例实战:陌生人社交APP的MySQL索引设计实战(二)
- 83 | 案例实战:陌生人社交APP的MySQL索引设计实战(三)
- 84 | 案例实战:陌生人社交APP的MySQL索引设计实战(四)
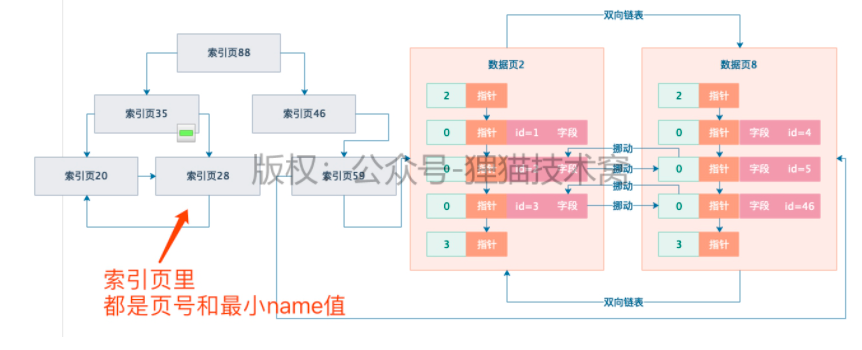
66 | 不断在表中插入数据时,物理存储是如何进行页分裂的
1、页分裂
2、数据页的单向链表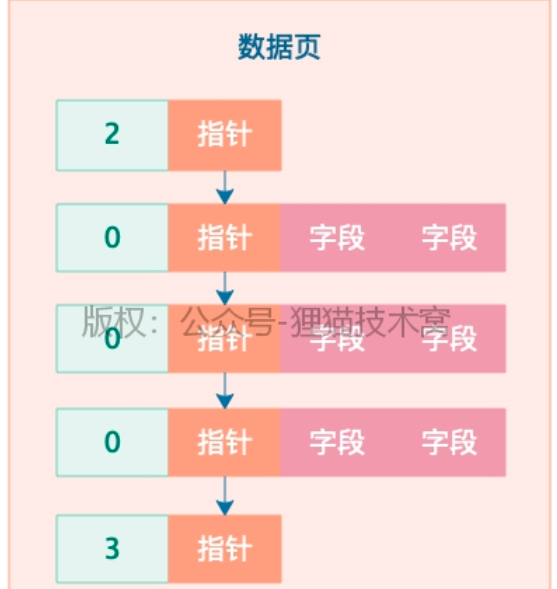
1) 2表示 最小的一行
3 标识最大的一行
2)不停的往数据页插数据,就需要另一个数据页了
3)索引运作的一个核心基础:要求你后一个数据页的主键值都大于前面一个数据页的主键值
4)如果主键自增可以满足3),如果不是自增的,会出现一个过程,页分裂
5)页分裂:在增加一个新的数据页的时候,实际上回把前一个数据页里主键值较大的,挪动到新的数据页里,然后把新插入的主键值较小的数据挪动到上一个数据页里去,保证新的数据页里主键值一定比上一个数据页的主键值大
67 | 基于主键的索引是如何设计的,以及如何根据主键索引查询
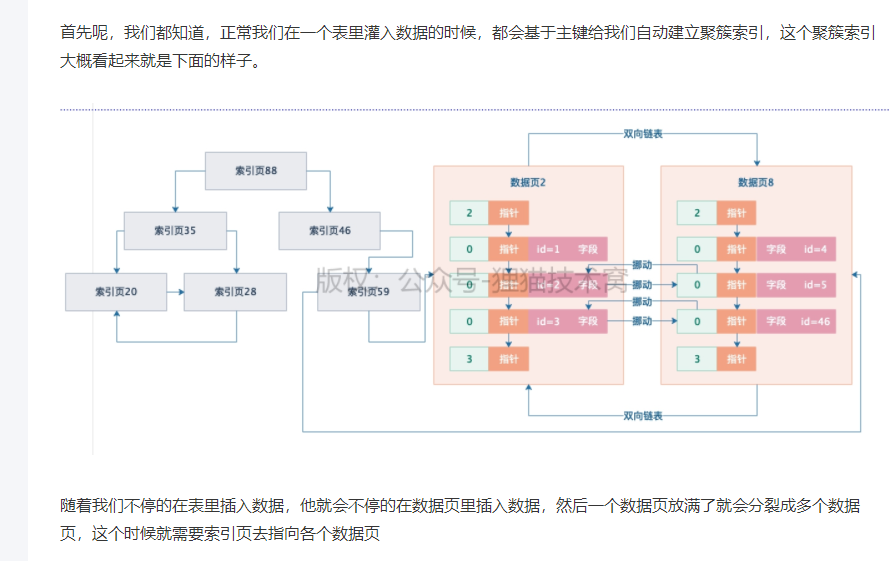
68 | 索引的页存储物理结构,是如何用B+树来实现的
1、数据页里有多个索引页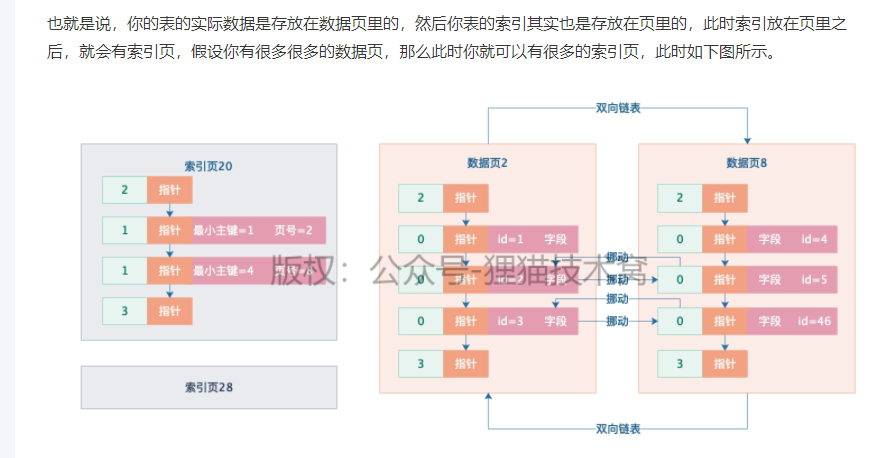
2、如何确定查询哪个索引页?
用一个更高的索引层级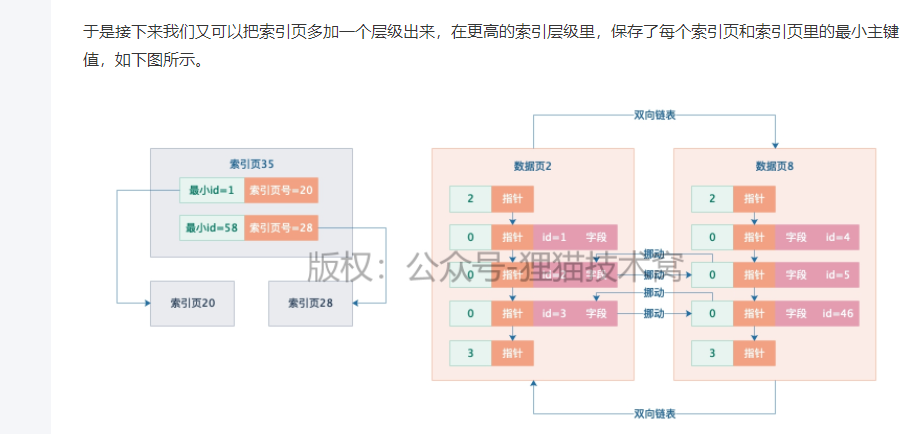
3、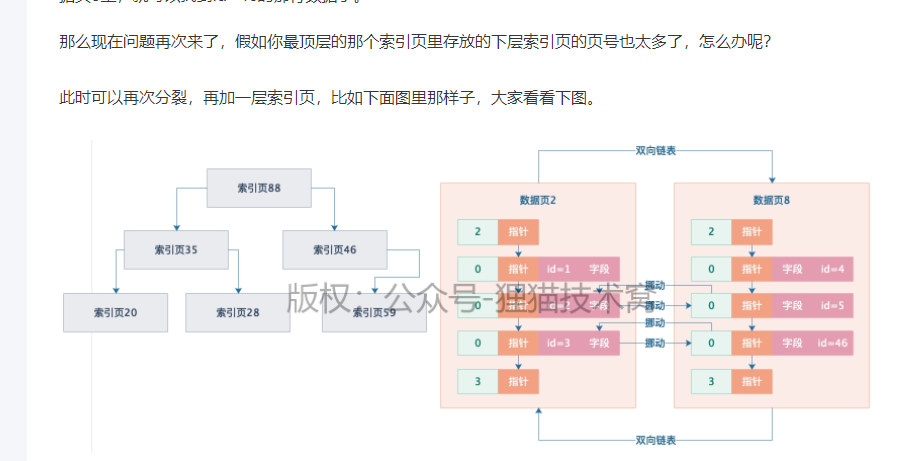
4、B+树
69 | 更新数据的时候,自动维护的聚簇索引到底是什么

70 | 针对主键之外的字段建立的二级索引,又是如何运作的

name字段的B+树,叶子节点的数据页里仅仅存放的主键和name字段的值
select * from table where name = ‘xxxx’
1)根据name字段的索引在B+树里找,找到对应的主键值
2)根据主键值,再到聚簇索引里从根节点开始,一路找到叶子节点对应的数据页,定位到主键对应的完整数据行
(回表)
71 | 插入数据时到底是如何维护好不同索引的B+树的
72 | 一个表里是不是索引搞的越多越好?那你就大错特错了
索引多,缺点:
1、空间上
如果给很多字段创建很多的索引,必然有很多B+树,每一棵树都占很多磁盘空间
2、时间上
1)在增删改时,每次都要维护索引的数据有序性,每个索引的B+树都要求页内是按主键大小排序的,且页之间也是有序的。
2)不停的增删改,必然导致数据页的无序,只能进行数据页的挪动,维护顺序
3)不停的插入数据,各个索引的数据页也不要不停的分裂
以上都耗时
73 | 通过一步一图来深入理解联合索引查询原理以及全值匹配规则
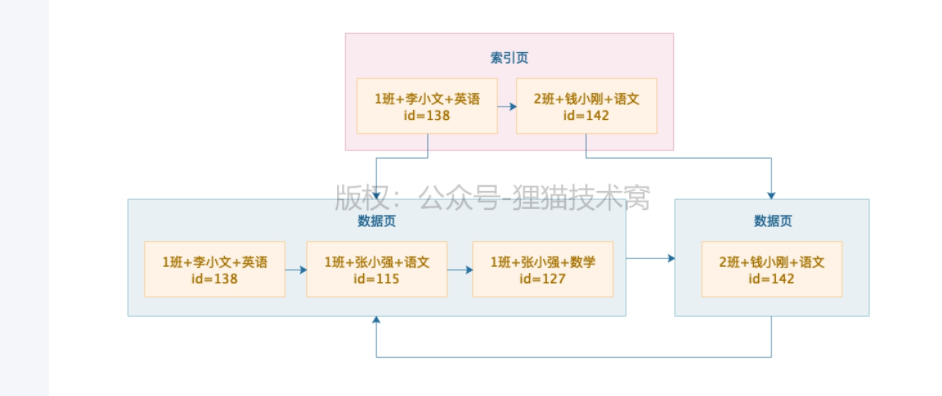
1)首先数据页内,是按 班级、名称、科目排序的,组成了单项链表
2)数据页2的id值一定大于 数据页1的id值
3)两个数据页组成双向链表
4)索引页里存储的是数据页的最小id值
5)如果多个索引页,索引页之间也是有序的,且组成双向链表
select * from table where class_name = ‘1班’ and student_name = ‘张小强’ and subject_name = ‘数学’;
等值匹配规则:where语句的字段名称和联合索引的字段完全一样,基于等号的等值匹配
1)首先先去索引页里找,二分查找
2)直接找到索引指向的那个数据页,页内数据是单链表,二分查找即可
74 | 再来看看几个最常见和最基本的索引使用规则
1、最左侧列匹配
1)select from table where class_name = ‘1班’ and student_name = ‘张小强’ ,可以
2)select from table where subject_name = ‘数学’,不可以,因为B+树是先按 class_name来查,再按studen_name来查,不能跳过
2、最左前缀匹配原则
1)用like语法来查,select from table where class_name like ‘1%’ ,可以
2)select from table where class_name like ‘%班’,不可以,左侧是一个通配符,不能确定最左侧前缀是什么
3、范围查找规则
1)select from table where class_name< ‘’ and class_name > ‘’ ,可以
2)select from table where student_name < ‘’ and student_name > ‘’ ,没法用索引
4、等值匹配+范围匹配
1)select * from table where class_name = ‘’ and student_name > ‘’ ,可以,但是subject_name 不能用索引
75 | 当我们在SQL里进行排序的时候,如何才能使用索引
索引 INDEX(xx1,xx2,xx3)
select from table order by xx1,xx2,xx3
select from table order by xx1 desc ,xx2 desc ,xx3 desc
以上两个查询语句,都可以直接用索引,因为索引里排序就是按照 xx1,xx2,xx3
76 | 当我们在SQL里进行分组的时候,如何才能使用索引
group by 使用索引规则同 order by
77 | 回表查询对性能的损害以及覆盖索引是什么
1、回表查询
如果是select from table order by xx1,xx2,xx3 ,还不如直接回表查询
如果是select from table order by xx1,xx2,xx3 limit 100,先扫描联合索引拿到100条,然后对这100条在聚簇索引里查找100此就可以了
2、覆盖索引
需要的字段在索引就能提取出来,不需要回表到聚簇索引
select xx1,xx2,xx3 from table order by xx1,xx2,xx3
78 | 设计索引的时候,我们一般要考虑哪些因素呢?(上)
根据程序里面的sql 语句的where \order by \ group by 条件去设计索引
79 | 设计索引的时候,我们一般要考虑哪些因素呢?(中)
1、建立索引,尽量使用那些基数比较大的字段(值比较多的字段),才能发挥出来B+树二分查找的优势
2、对于那种比较长的字符串类型,可以设计前缀索引,仅仅包含部分字符到索引树里去,where查询用的到,orderby group by 用不到了
80 | 设计索引的时候,我们一般要考虑哪些因素呢?(下)
索引别设计太多、建立二三个联合索引能覆盖这个表的全部查询
主键不要用uuid,建议自增的,雪花算法出id Twitter 分布式主键
81 | 案例实战:陌生人社交APP的MySQL索引设计实战(一)
82 | 案例实战:陌生人社交APP的MySQL索引设计实战(二)
83 | 案例实战:陌生人社交APP的MySQL索引设计实战(三)
84 | 案例实战:陌生人社交APP的MySQL索引设计实战(四)


若有收获,就点个赞吧
0 人点赞
