- 48 | 多个事务并发更新以及查询数据,为什么会有脏写和脏读的问题
- 49 | 一个事务多次查询一条数据读到的都是不同的值,这就是不可重复读?
- 50 | 听起来很恐怖的数据库幻读,到底是个什么奇葩问题
- 51 | SQL标准中对事务的4个隔离级别,都是如何规定的呢
- 52 | MySQL是如何支持4种事务隔离级别的?Spring事务注解是如何设置的
- 53 | 理解MVCC机制的前奏:undo log版本链是个什么东西
- 54 | 基于undo log多版本链条实现的ReadView机制,到底是什么
- 55 | Read Committed隔离级别是如何基于ReadView机制实现的
- 56 | MySQL最牛的RR隔离级别,是如何基于ReadView机制实现的?
- 57 | 停一停脚步:梳理一下数据库的多事务并发运行的隔离机制
- 58 | 多个事务更新同一行数据时,是如何加锁避免脏写的
- 59 | 对MySQL锁机制再深入一步,共享锁和独占锁到底是什么
- 60 | 在数据库里,哪些操作会导致在表级别加锁呢
- 61 | 表锁和行锁互相之间的关系以及互斥规则是什么呢
- 62 | 案例实战:线上数据库不确定性的性能抖动优化实践(上)
- 63 | 案例实战:线上数据库莫名其妙的随机性能抖动优化(下)
- 64 | 深入研究索引之前,先来看看磁盘数据页的存储结构
- 65 | 假设没有任何索引,数据库是如何根据查询语句搜索数据的
48 | 多个事务并发更新以及查询数据,为什么会有脏写和脏读的问题
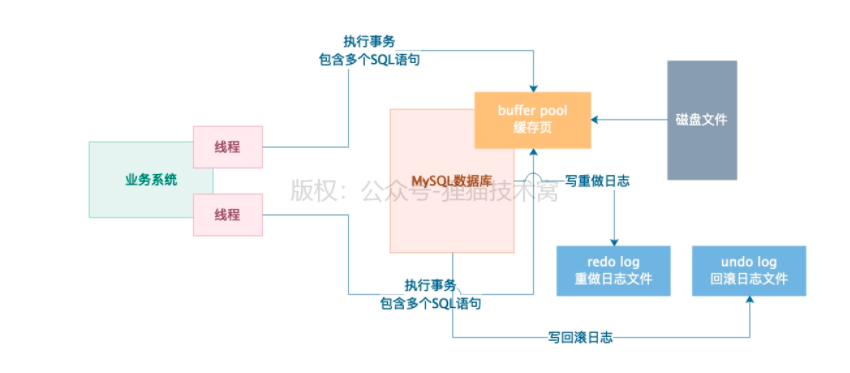
1、脏写
1)有两个事务,事务A和事务B同时更新一条数据,事务A先更新成A值,事务B紧接着更新为B值
2)事务A更新后,会记录一条undo log日志,内容为:更新之前这行数据值为null ,主键xxx
3)此时事务B已经更新成B值了,A突然回滚了,就会根据A的undo log 回滚成null值
4)对于B事务来说,明明自己更新了,结果值却没了,这就是脏写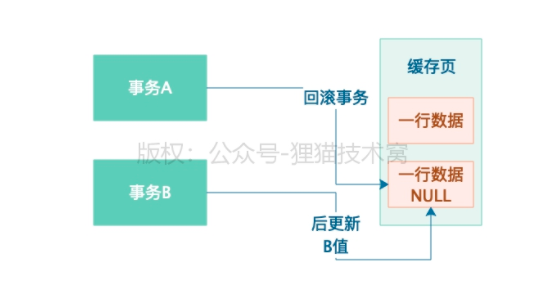
2、脏读
1)A更新了一行数据的值为A值,事务B去查询了一下这行数据的值,看到的是A值
2)A没有commit ,B拿着A值去做了一些业务处理
3)此时A突然回滚了事务,导致他刚才更新的A值没有了
4)事务B紧接着再次查询到的数据就是NULL,这就是脏读
总结:脏写脏读都是因为,一个事务更新或查询另一个还没提交的事务更新过的数据
49 | 一个事务多次查询一条数据读到的都是不同的值,这就是不可重复读?
1、不可重复读
1)A事务会对一条数据进行查询
2)B事务、C事务对一条火速将进行更新
3)A事务开启,读到的数据是A。然后B更新后,B提交事务,A还没提交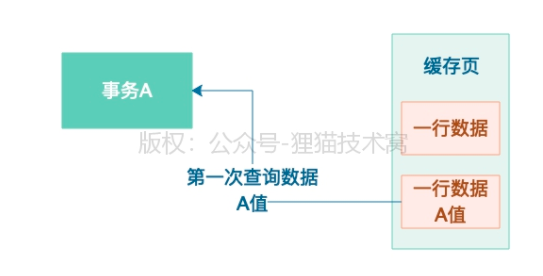
4)A第二次查询到的值是B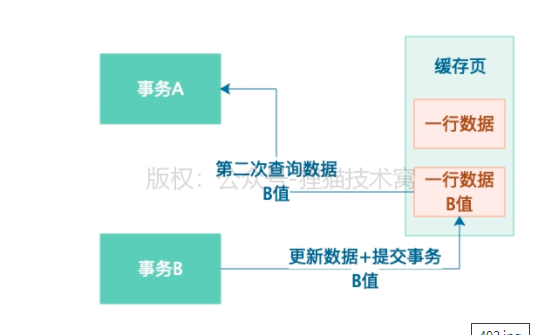
5)C值更新数据为C值,并且提交事务,A还没提交,第三次查询到的值是C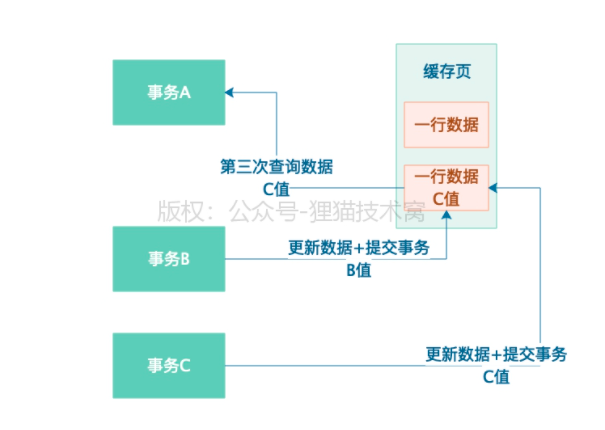
50 | 听起来很恐怖的数据库幻读,到底是个什么奇葩问题
1、幻读 : 当一个事务用一样的sql多次查询,结果每次查询都查到了一些之前没见过的数据。
1)事务A,发送一条SQL select * from table where id > 10
2)第一次查出来了10条数据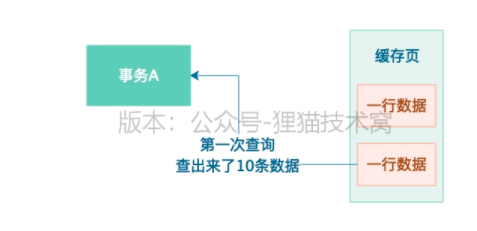
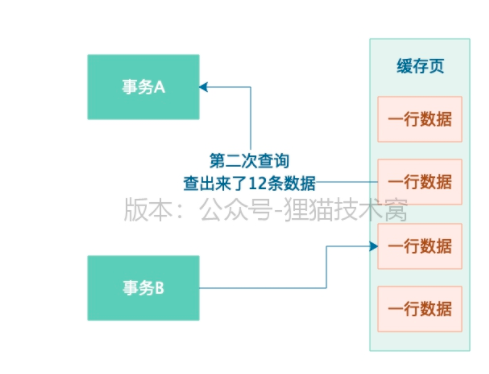
3)事务B又插入了几条数据,且事务B提交了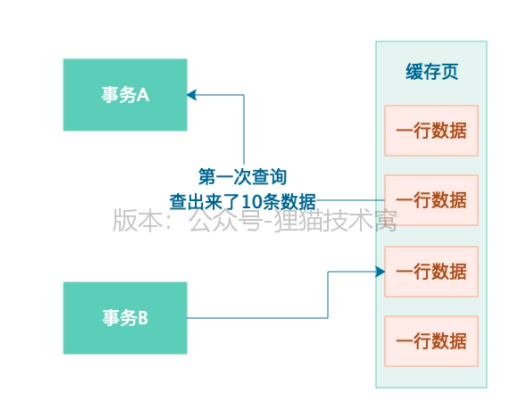
4)事务A第二次查出来了12条数据
51 | SQL标准中对事务的4个隔离级别,都是如何规定的呢
1、隔离机制
1)为了解决脏写、脏读、幻读等问题,用SQL标准中的规定的事务的几种隔离级别
2)4种隔离机制:
- read uncommitted(读未提交)
- read committed(读已提交)
- repeatable read(可重复读)
- serializable (串行化)
2、详细
1)read uncommitted(读未提交) ,不允许发生脏写,但是可能会发现脏读、不可重复读、幻读
2)read committed(读已提交),不允许发生脏写和脏读,但可能不可重复度、幻读;简称RC
简述:如果事务没提交的话,修改的值是不可能读到的。一旦人家事务修改值,然后事务提交了,你可能多次读到的值是不同的
3)repeatable read(可重复读),不允许发生脏写、脏读、不可重复读,但可能幻读;简称RR
简述:如果你一个事务多次去查询一个数据的值,哪怕别的事务修改这个值提交了,你不会读到人家提交事务修改过的值,你会一直查询的同一个值
4)serializable (串行化),不允许多个事务并发执行,只能串行执行,性能太差,不提倡。
52 | MySQL是如何支持4种事务隔离级别的?Spring事务注解是如何设置的
1、修改mysql默认事务隔离级别命令: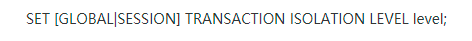
可以设定级别不同的level,level的值是可以是四种隔离机制,一般用默认的RR就可以
2、spring @Transactional注解 怎么设定
1)如果你想设定RC级别,就想读到人家事务刚提交后修改的值
2)@Transactional注解里有一个参数 isolation,可以设定隔离级别
3)@Transactional(isolation = Isolation.DEFAULT),mysql默认支持什么隔离就是什么隔离级别
4)按照1)的场景,你可以改成 @Transactional(isolation = Isolation.READ_UNCOMMITTED)
53 | 理解MVCC机制的前奏:undo log版本链是个什么东西
1、undo log 版本链
1)每条数据有两个隐藏字段:trx_id , roll_pointer。
2)trx_id : 最近一次更新这条数据的事务id
3)roll_pointer:指向你更新这个事务之前生成的undo log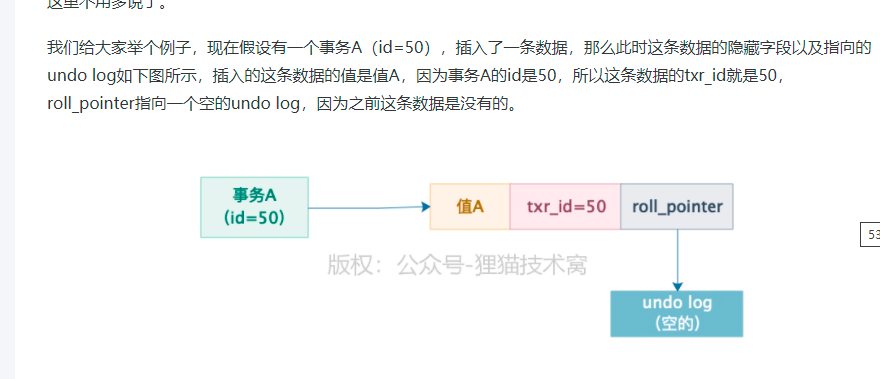
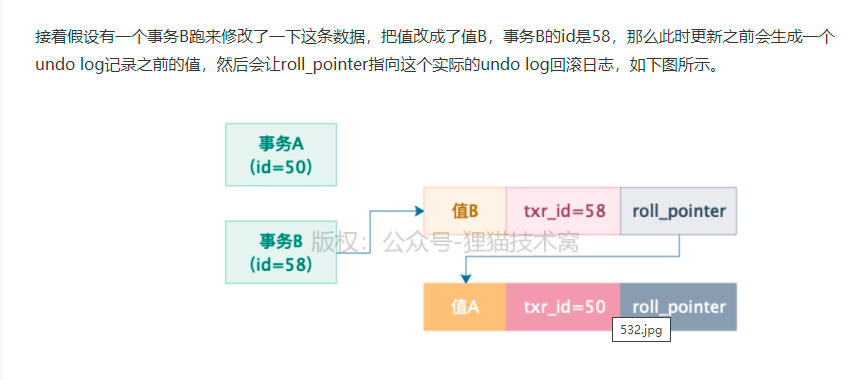
54 | 基于undo log多版本链条实现的ReadView机制,到底是什么
1、readView机制
1)简述:执行一个事务时,就会生成一个readView
2)readView 有4个关键的东西:
- m_ids:表示此时有哪些事务在mysql里执行还没提交的
- min_trx_id :就是m_ids里面的最小值
- max_trx_id :mysql下一个要生成的事务ID,最大的事务ID
- creator_trx_id :你这个事务的ID
3)举例:
原先有数据库有一行数据,很早之前插入过了,事务ID是32 :
两个事务并发过来执行了:
事务A(id=45):读取这行数据
事务B(id=59):更改这行数据
事务A直接开启一个readView:
- m_ids : 45、59
- min_trx_id : 45
- max_trx_id : 60
- creator_trx_id : 45
事务A第一次查询这行数据,会走一个判断:判断当前这行数据(trx_id = 32)trx_id是否小于readView中的min_trx_id(45)。如果小于:说明事务A开启前,修改这行数据的事务早就提交了,所有此时可以查到这行数据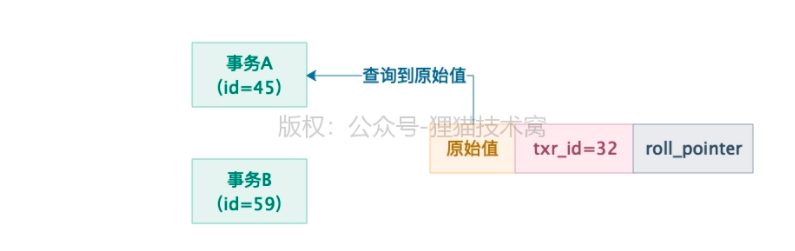
事务B:
对这行数据修改成了B
然后将这行数据的txr_id设置为自己的id,也就是59
将roll_pointer指向了修改之前生成的一个undo log,然后事务B提交了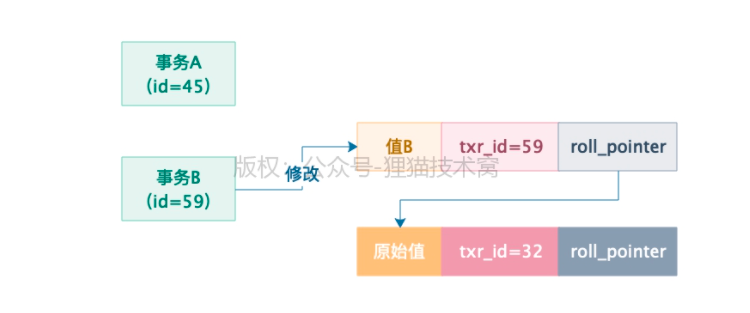
事务A再次查询:
这行数据txr_id =59 > 事务A的readView里的min_txr_id = 45
这行数据txr_id =59 < 事务A的readView里的max_txr_id = 60
说明事务B跟事务A 很可能是同一时段并发执行然后提交的,所以这行数据是不能查询的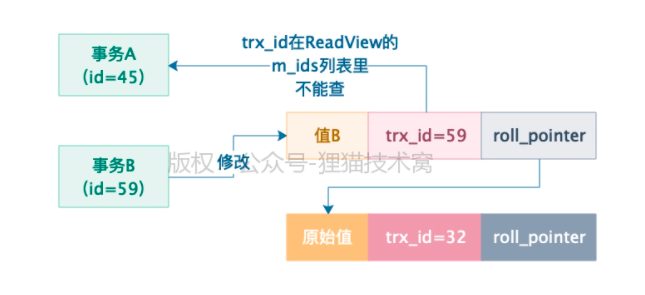
如果不能查询这行数据,应该查询什么?
顺着这条数据的roll_pointer的undo log日志链往下查,找到最近的undo log(trx_id=32), 然后比较这行数据trx_id 和 事务A的min_txr_id比较,直到找到事务A开启前执行并提交的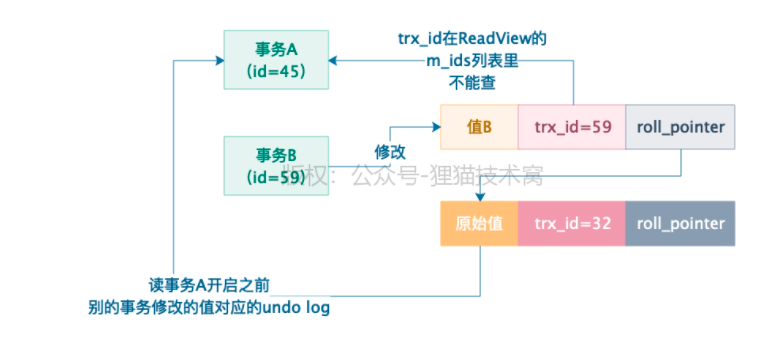
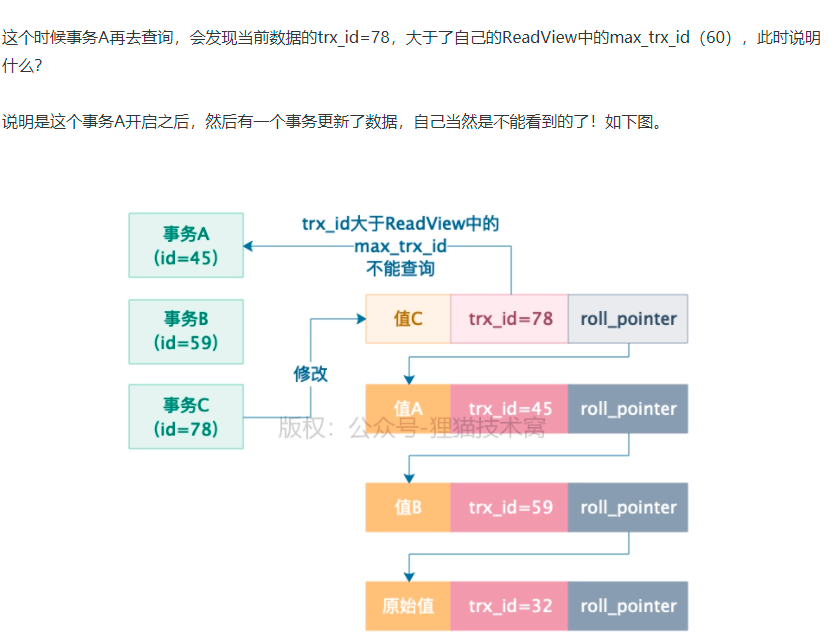
事务A把这行数据又更新成值A,然后事务A再去查询,能查询值,因为自己修改的能看到
55 | Read Committed隔离级别是如何基于ReadView机制实现的
56 | MySQL最牛的RR隔离级别,是如何基于ReadView机制实现的?
57 | 停一停脚步:梳理一下数据库的多事务并发运行的隔离机制
58 | 多个事务更新同一行数据时,是如何加锁避免脏写的
1、锁
事务开启前先创建一个锁,里面包含了trx_id 和 等待状态,然后把锁和这行数据关联在一起。
更新一行数据,必须把他从所在的数据页从磁盘文件里读到缓存页上,所以这行数据和关联的锁都在内存里
事务A加了锁,就不允许别的事务访问了。比如事务B也要来更新这条数据,发现A已经加锁了,所以也创建了一个锁,等待状态为true。
如果事务A提交后,释放了锁,唤醒B,更改事务B的状态为false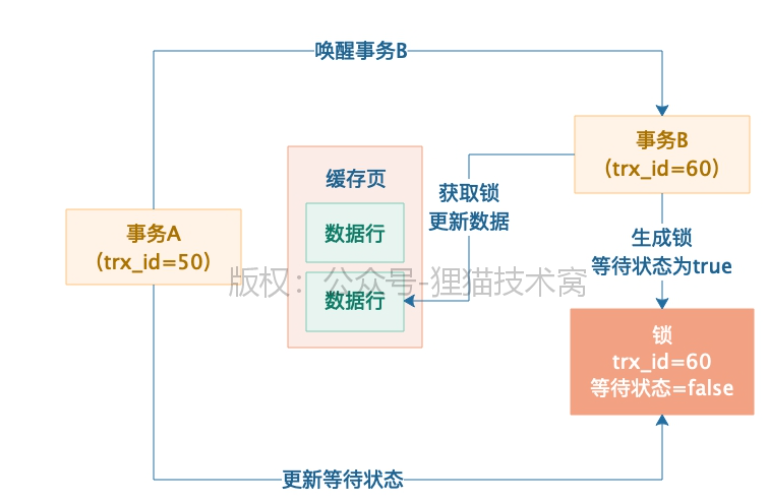
59 | 对MySQL锁机制再深入一步,共享锁和独占锁到底是什么
1、58中加的锁,为独占锁(E锁、Exclude锁)
2、当有行数据加了锁,别的事务还能访问吗,还需要加锁吗?
能访问,不加锁
3、如果查询数据时,如果要加锁,应该如何?
mysql共享锁,S锁,语法:
select * from table lock in share model
4、如果一个事务加了独占锁进行更新数据,还能加共享锁吗?
不能,两者互斥
5、共享锁和共享锁不互斥
60 | 在数据库里,哪些操作会导致在表级别加锁呢
1、行锁
多个事务并发更新数据时,都是要在行级别加独占锁,独占锁都是互斥的
2、DDL和增删改查是互斥的,通过mysql的元数据锁实现的,Metadata Locks,不是表级锁
61 | 表锁和行锁互相之间的关系以及互斥规则是什么呢
1、表锁(比较鸡肋)
LOCK TABLES xxx READ : 加表级共享锁
LOCK TABLES xxx WRITE : 表级独占锁
2、两种情况可能加表级锁
1)事务在表里执行增删改操作,行级加独占锁,同时会在表级加一个意向独占锁
2)事务在表里执行查操作,表级加一个意向独占锁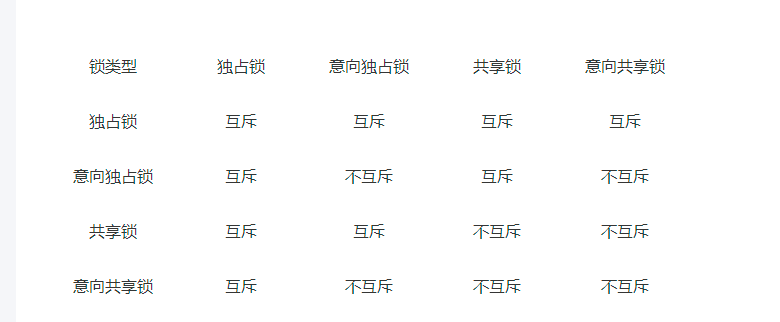
62 | 案例实战:线上数据库不确定性的性能抖动优化实践(上)
63 | 案例实战:线上数据库莫名其妙的随机性能抖动优化(下)
性能抖动原因:
1、buffer pool 缓存页都满了,执行一个sql查询很多数据,一下子把很多缓存页flush刷新到磁盘上去。刷盘慢
2、执行更新数据,redo log在磁盘上所有文件都写满了,此时回到redo log文件覆盖写。缓存页还没flush到磁盘。必须把缓存页flush到磁盘,才能执行后续的更新语句。
优化性能抖动核心:
1、尽量减少缓存页
64 | 深入研究索引之前,先来看看磁盘数据页的存储结构
数据页在磁盘文件中的物理存储结构:
数据页之间是双向链表
数据页内部的数据行是单向链表
数据行是根据主键从小到大排列的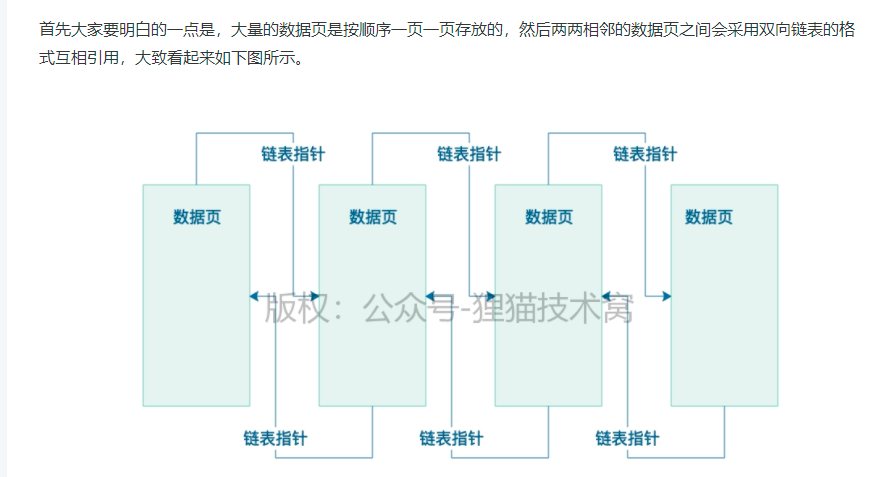

65 | 假设没有任何索引,数据库是如何根据查询语句搜索数据的
数据页里都会有一个页目录:
内容包含主键和槽位,数据行是被分散存储到不同槽位里。
页目录里是 每个主键对应槽位的映射关系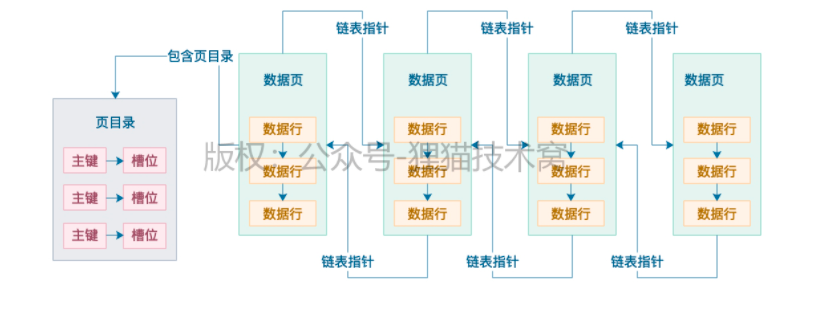
1、假设根据主键查询一条数据,表里没多少数据,就一个数据页,可以简单对数据页目录进行 主键的二分查找,通过二分查找迅速定位到主键对应的数据在哪个槽位,然后到槽位里遍历每一行数据,就能找到数据了。
2、如果是大量的数据页,只能进行全表扫描

若有收获,就点个赞吧
0 人点赞
