网上很多教程都在讲Y叔的clusterprofile富集分析的教程,但是查阅了官方文档后才知道,这个包真的不仅仅只有这个功能,其他功能也很强大。
做ID转换
ID转换应该是基因下游分析的敲门砖了,因为一般注释用的是ENSMEBL ID,但是这个ID是人类无法识别的一串数字,下游分析功能都需要转换成基因名称或者基因ID,有这个bitr功能就方便了很多。
x <- c("GPX3", "GLRX", "LBP", "CRYAB", "DEFB1", "HCLS1", "SOD2", "HSPA2","ORM1", "IGFBP1", "PTHLH", "GPC3", "IGFBP3","TOB1", "MITF", "NDRG1","NR1H4", "FGFR3", "PVR", "IL6", "PTPRM", "ERBB2", "NID2", "LAMB1","COMP", "PLS3", "MCAM", "SPP1", "LAMC1", "COL4A2", "COL4A1", "MYOC","ANXA4", "TFPI2", "CST6", "SLPI", "TIMP2", "CPM", "GGT1", "NNMT","MAL", "EEF1A2", "HGD", "TCN2", "CDA", "PCCA", "CRYM", "PDXK","STC1", "WARS", "HMOX1", "FXYD2", "RBP4", "SLC6A12", "KDELR3", "ITM2B")eg = bitr(x, fromType="SYMBOL", toType="ENTREZID", OrgDb="org.Hs.eg.db")head(eg)
## SYMBOL ENTREZID## 1 GPX3 2878## 2 GLRX 2745## 3 LBP 3929## 4 CRYAB 1410## 5 DEFB1 1672## 6 HCLS1 3059
想知道你可以进行哪些ID 转换?
library(org.Hs.eg.db)keytypes(org.Hs.eg.db)
## [1] "ACCNUM" "ALIAS" "ENSEMBL"## [4] "ENSEMBLPROT" "ENSEMBLTRANS" "ENTREZID"## [7] "ENZYME" "EVIDENCE" "EVIDENCEALL"## [10] "GENENAME" "GO" "GOALL"## [13] "IPI" "MAP" "OMIM"## [16] "ONTOLOGY" "ONTOLOGYALL" "PATH"## [19] "PFAM" "PMID" "PROSITE"## [22] "REFSEQ" "SYMBOL" "UCSCKG"## [25] "UNIGENE" "UNIPROT"
Note:虽然GO分析支持很多ID,例如symbol完全可以直接运行,但还是建议都转换为ENTREZID,毕竟,我们很少直接得到symbol啊。
GSEA分析
还在使用官方的GSEA java包进行富集分析吗,你需要准备gct文件(表达矩阵),要转换为symbol或者entrezid,还要准备cls文件(样本特征),还要下载好gmt文件,最后出来的分析结果,各种图片都是不好看的,准确说不够灵活,用R包呢?
GSEA_GO
ego3 <- gseGO(geneList = geneList,OrgDb = org.Hs.eg.db,ont = "CC",nPerm = 1000,minGSSize = 100,maxGSSize = 500,pvalueCutoff = 0.05,verbose = FALSE)
geneList 是什么?
类似于做富集(过表达)分析,geneList是一列基因id,而GSEA分析一般需要基因表达量来衡量富集分数,但是从原理上来讲,还是根据表达量计算Fordchange,然后给他排序,看这个排序在基因集中的富集程度。这样就不会因为传统分析中先筛选差异基因而过滤掉的低差异基因信息(详情参考GSEA的原理),所以,这个基因列表是指一列排序后的以基因名称为名字的log2FC值向量。
假设你有一个两列的文件,第一列为名字,第二列为logFC,你可以这样:
d <- read.csv(your_csv_file)##第一列为基因ID##第二列为差异值## 获取log2FCgeneList <- d[,2]## 命名names(geneList) <- as.character(d[,1])## 降序geneList <- sort(geneList, decreasing = TRUE)head(geneList)
剩余都是一些限制参数,请执行?clusterProfiler::gseGO
## 4312 8318 10874 55143 55388 991## 4.572613 4.514594 4.418218 4.144075 3.876258 3.677857
GSEA-KEGG
kk2 <- gseKEGG(geneList = geneList,organism = 'hsa',nPerm = 1000,minGSSize = 120,pvalueCutoff = 0.05,verbose = FALSE)head(kk2)
## ID Description setSize## hsa04510 hsa04510 Focal adhesion 188## hsa04151 hsa04151 PI3K-Akt signaling pathway 322## hsa03013 hsa03013 RNA transport 131## hsa05152 hsa05152 Tuberculosis 162## hsa04062 hsa04062 Chemokine signaling pathway 165## hsa04218 hsa04218 Cellular senescence 143## enrichmentScore NES pvalue p.adjust## hsa04510 -0.4188582 -1.706291 0.001430615 0.02322097## hsa04151 -0.3482755 -1.497042 0.002614379 0.02322097## hsa03013 0.4116488 1.735751 0.003095975 0.02322097## hsa05152 0.3745153 1.630500 0.003154574 0.02322097## hsa04062 0.3754101 1.633635 0.003184713 0.02322097## hsa04218 0.4153718 1.772207 0.003194888 0.02322097## qvalues rank leading_edge## hsa04510 0.01576976 2183 tags=27%, list=17%, signal=23%## hsa04151 0.01576976 1997 tags=23%, list=16%, signal=20%## hsa03013 0.01576976 3383 tags=40%, list=27%, signal=29%## hsa05152 0.01576976 2823 tags=34%, list=23%, signal=27%## hsa04062 0.01576976 1298 tags=21%, list=10%, signal=19%## hsa04218 0.01576976 1155 tags=17%, list=9%, signal=16%## core_enrichment## hsa04510 5595/5228/7424/1499/4636/83660/7059/5295/1288/23396/3910/3371/3082/1291/394/3791/7450/596/3685/1280/3675/595/2318/3912/1793/1278/1277/1293/10398/55742/2317/7058/25759/56034/3693/3480/5159/857/1292/3908/3909/63923/3913/1287/3679/7060/3479/10451/80310/1311/1101## hsa04151 627/2252/7059/92579/5563/5295/6794/1288/7010/3910/3371/3082/1291/4602/3791/1027/90993/3441/3643/1129/2322/1975/7450/596/3685/1942/2149/1280/4804/3675/595/2261/7248/2246/4803/3912/1902/1278/1277/2846/2057/1293/2247/55970/5618/7058/10161/56034/3693/4254/3480/4908/5159/1292/3908/2690/3909/8817/9223/4915/3551/2791/63923/3913/9863/3667/1287/3679/7060/3479/80310/1311/5105/2066/1101## hsa03013 10460/1978/55110/54913/9688/8894/11260/10799/9631/4116/5042/8761/6396/23165/8662/10248/55706/79833/9775/29107/23636/5905/9513/5901/10775/10557/4927/79902/1981/26986/11171/10762/8480/8891/11097/26019/10940/4686/9972/81929/10556/3646/9470/387082/1977/57122/8563/7514/79023/3837/9818/56000## hsa05152 820/51806/6772/64581/3126/3112/8767/3654/1054/1051/3458/1520/11151/1594/50617/54205/91860/8877/3329/637/3689/7096/2207/3929/4360/5603/929/533/3452/6850/7124/1509/3569/7097/1378/8772/64170/3119/843/2213/8625/3920/2215/3587/5594/3593/9103/3592/6300/9114/10333/3109/3108/1432/3552## hsa04062 3627/10563/6373/4283/6362/6355/2921/6364/3576/6352/10663/1230/6772/6347/6351/3055/1237/1236/4067/6354/114/3702/6361/1794/1234/6367/6375/6374/2919/409/4793/2792/6360/5880## hsa04218
结果里面包含了所有GSEA计算的结果数值
setSize:基因集的大小
enrichmentScore:富集打分
NES:标准化后的富集打分
pvalue,p.ajust.qvalues:各种显著性检验
rank:log2FC的排序位置
根据官方提供的gmt文件或者自己做gmt文件进行分析
假设你从官网下载了Hallmark基因集
wp2gene <- read.gmt("h.all.v7.0.entrez.gmt")em2 <- GSEA(geneList, TERM2GENE = wp2gene)
这样就可以直接得到富集分析的结果,非常方便
另外,也可以通过msigdbr包直接获取基因集信息,但是感觉灵活性不高。
对GSEA的结果可视化
anno <- edo2[1, c("NES", "pvalue", "p.adjust")]lab <- paste0(names(anno), "=", round(anno, 3), collapse="\n")gseaplot2(edo2, geneSetID = 1, title = edo2$Description[1])+annotate("text", 0.7, edo2[i, "enrichmentScore"] * .9, label = lab, hjust=0, vjust=0)
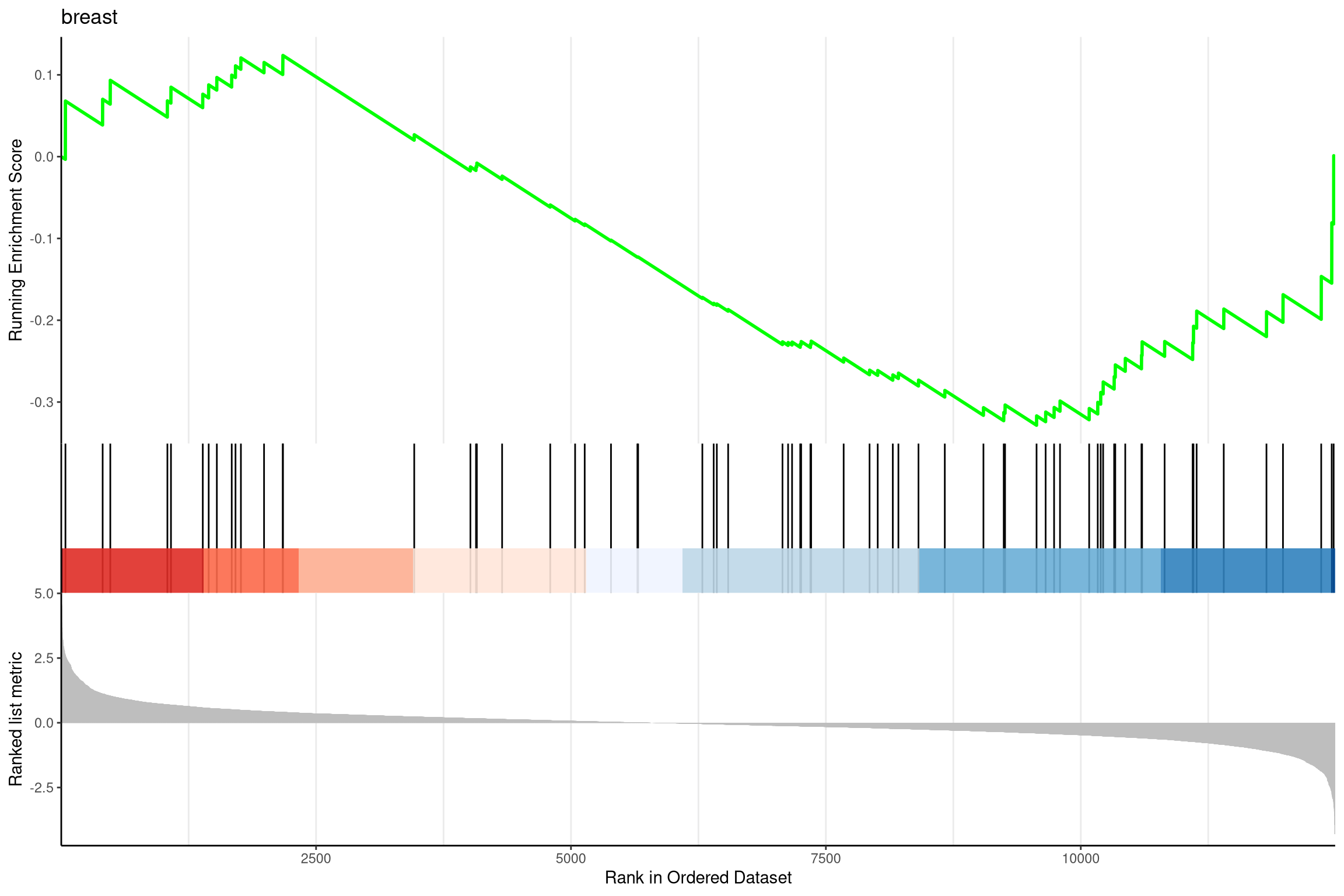
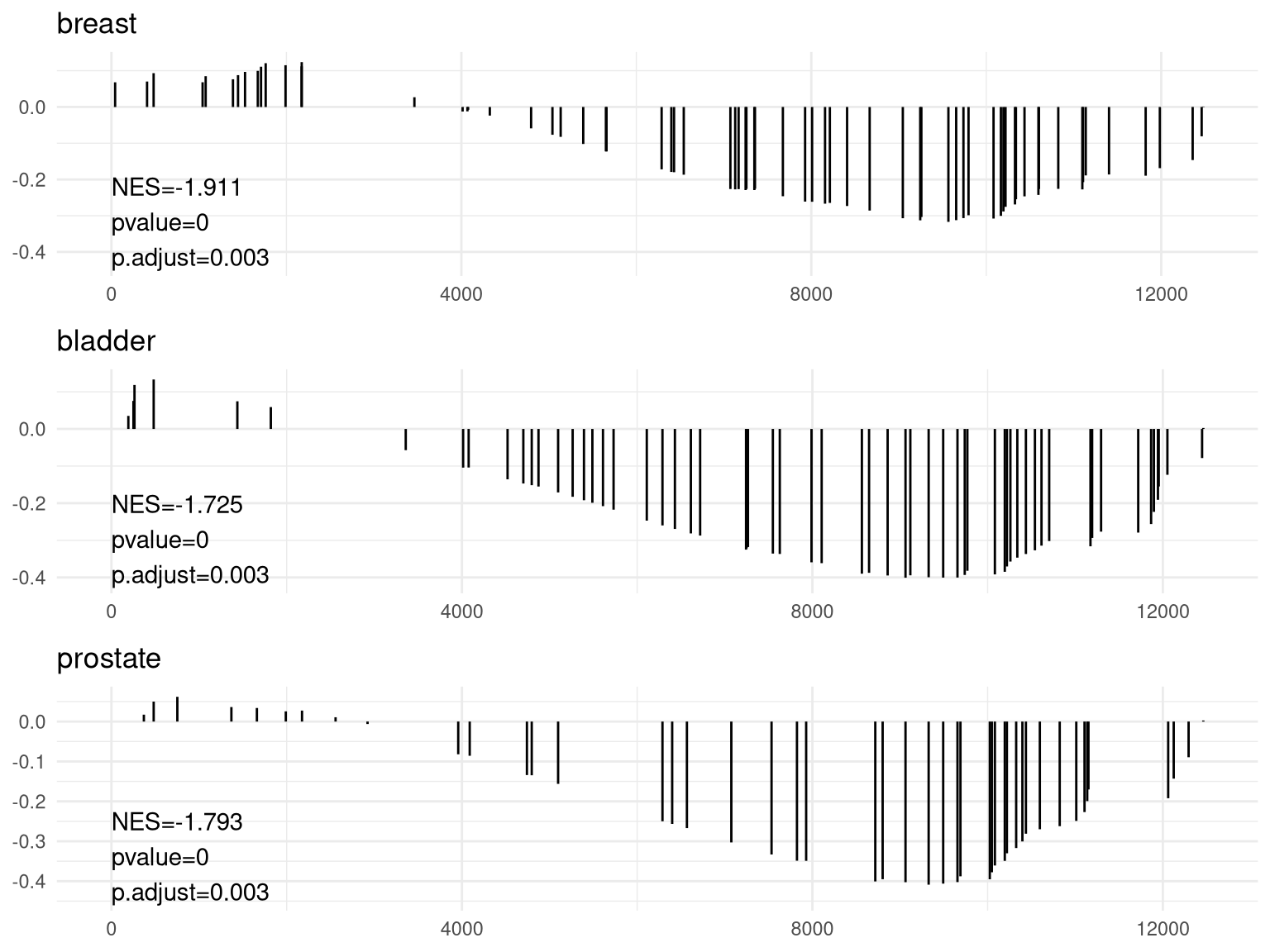
pp <- lapply(1:3, function(i) {anno <- edo2[i, c("NES", "pvalue", "p.adjust")]lab <- paste0(names(anno), "=", round(anno, 3), collapse="\n")gsearank(edo2, i, edo2[i, 2]) + xlab(NULL) +ylab(NULL) +annotate("text", 0, edo2[i, "enrichmentScore"] * .9, label = lab, hjust=0, vjust=0)})plot_grid(plotlist=pp, ncol=1)
使结果可读性提升
针对分析结果,GO富集可以设置参数readable = TRUE,但是对KEGG无法使用,因此,可以使用setReadable
library(org.Hs.eg.db)library(clusterProfiler)data(geneList, package="DOSE")de <- names(geneList)[1:100]x <- enrichKEGG(de)## The geneID column is ENTREZIDhead(x, 3)
## ID Description GeneRatio BgRatio## hsa04110 hsa04110 Cell cycle 8/48 124/7932## hsa04218 hsa04218 Cellular senescence 7/48 160/7932## hsa04114 hsa04114 Oocyte meiosis 6/48 128/7932## pvalue p.adjust qvalue## hsa04110 6.356283e-07 7.182599e-05 6.490099e-05## hsa04218 4.377944e-05 2.473538e-03 2.235055e-03## hsa04114 1.105828e-04 4.165285e-03 3.763695e-03## geneID Count## hsa04110 8318/991/9133/890/983/4085/7272/1111 8## hsa04218 2305/4605/9133/890/983/51806/1111 7## hsa04114 991/9133/983/4085/51806/6790 6
y <- setReadable(x, OrgDb = org.Hs.eg.db, keyType="ENTREZID")## The geneID column is translated to symbolhead(y, 3)
## ID Description GeneRatio BgRatio## hsa04110 hsa04110 Cell cycle 8/48 124/7932## hsa04218 hsa04218 Cellular senescence 7/48 160/7932## hsa04114 hsa04114 Oocyte meiosis 6/48 128/7932## pvalue p.adjust qvalue## hsa04110 6.356283e-07 7.182599e-05 6.490099e-05## hsa04218 4.377944e-05 2.473538e-03 2.235055e-03## hsa04114 1.105828e-04 4.165285e-03 3.763695e-03## geneID## hsa04110 CDC45/CDC20/CCNB2/CCNA2/CDK1/MAD2L1/TTK/CHEK1## hsa04218 FOXM1/MYBL2/CCNB2/CCNA2/CDK1/CALML5/CHEK1## hsa04114 CDC20/CCNB2/CDK1/MAD2L1/CALML5/AURKA## Count## hsa04110 8## hsa04218 7## hsa04114 6
你甚至可以用它来对单细胞聚类结果进行注释
如果我们有一个大的细胞marker库,然后我们有显著差异的基因marker,那寻找细胞类型就和过表达分析是一种情况了,都是采用超几何分布计算概率,所以:
cell_markers <- vroom::vroom('http://bio-bigdata.hrbmu.edu.cn/CellMarker/download/Human_cell_markers.txt') %>%tidyr::unite("cellMarker", tissueType, cancerType, cellName, sep=", ") %>%dplyr::select(cellMarker, geneID) %>%dplyr::mutate(geneID = strsplit(geneID, ', '))cell_markers
你甚至可以从cellmarker官网直接下载所有的细胞marker
## # A tibble: 2,868 x 2## cellMarker geneID## <chr> <list>## 1 Kidney, Normal, Proximal tubular cell <chr [1…## 2 Liver, Normal, Ito cell (hepatic stellate cell) <chr [1…## 3 Endometrium, Normal, Trophoblast cell <chr [1…## 4 Germ, Normal, Primordial germ cell <chr [1…## 5 Corneal epithelium, Normal, Epithelial cell <chr [1…## 6 Placenta, Normal, Cytotrophoblast <chr [1…## 7 Periosteum, Normal, Periosteum-derived progenit… <chr [4…## 8 Amniotic membrane, Normal, Amnion epithelial ce… <chr [2…## 9 Primitive streak, Normal, Primitive streak cell <chr [2…## 10 Adipose tissue, Normal, Stromal vascular fracti… <chr [1…## # … with 2,858 more rows
y <- enricher(gene, TERM2GENE=cell_markers, minGSSize=1)DT::datatable(as.data.frame(y))
这样就找到了细胞类型,你可以过滤占比最高,且p值显著的结果。

若有收获,就点个赞吧
0 人点赞
