补充知识:多头注意力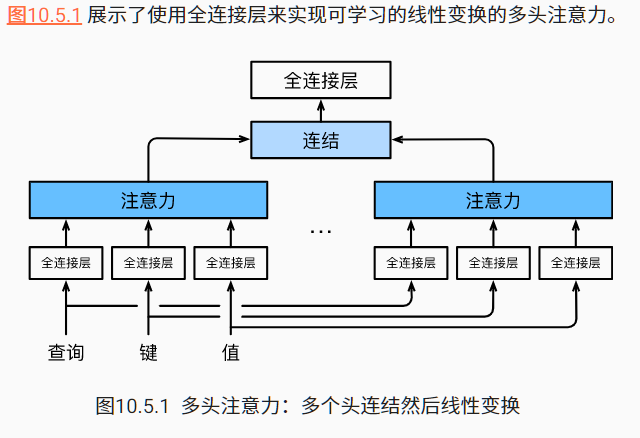

Transformer:
1,有掩码的多头注意力
解码器不该考虑该元素本身和其之后的元素,所以通过掩码实现:也就是计算xi输出的时候,假装当前序列的长度是i,就是不考虑后面的了,就是算softmax不算后面的权重了。
2,基于位置的前馈网络(逐位前馈网络)
相当于一个全连接,为什么呢,因为n会变,如果是(b,nd)就变成特征为nd了,那样特征长度也在一直变了。
相当于是把每个序列里的每个元素当一个样本来找特征,而不是考虑整个序列了。
3,层归一化(对应 加&规范化)
这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
加就是一个resnet
Resnet的目标是在网络深度加深的情况下解决梯度消失的问题
不用批量规范化而是用层规范化的原因
因为批量规范化时输入的序列长度会变所以会不稳定
bn是对每一个特征做归一化,特征就是每个序列里面d中的一维。
那么输入到bn中的则是一个len*batchsize的东西,len会变,每次输入形状不一样,所以会不稳定。
就像预测里面,len会越来越长
层归一化则是在一个单样本内 所以会更稳定一点输入时,每次选择一个样本,虽然len会变,但至少是在一个样本内了,而不是统计一整个batch里面的特征。
4, 信息传递 (就是从encoder到decoder的那条线)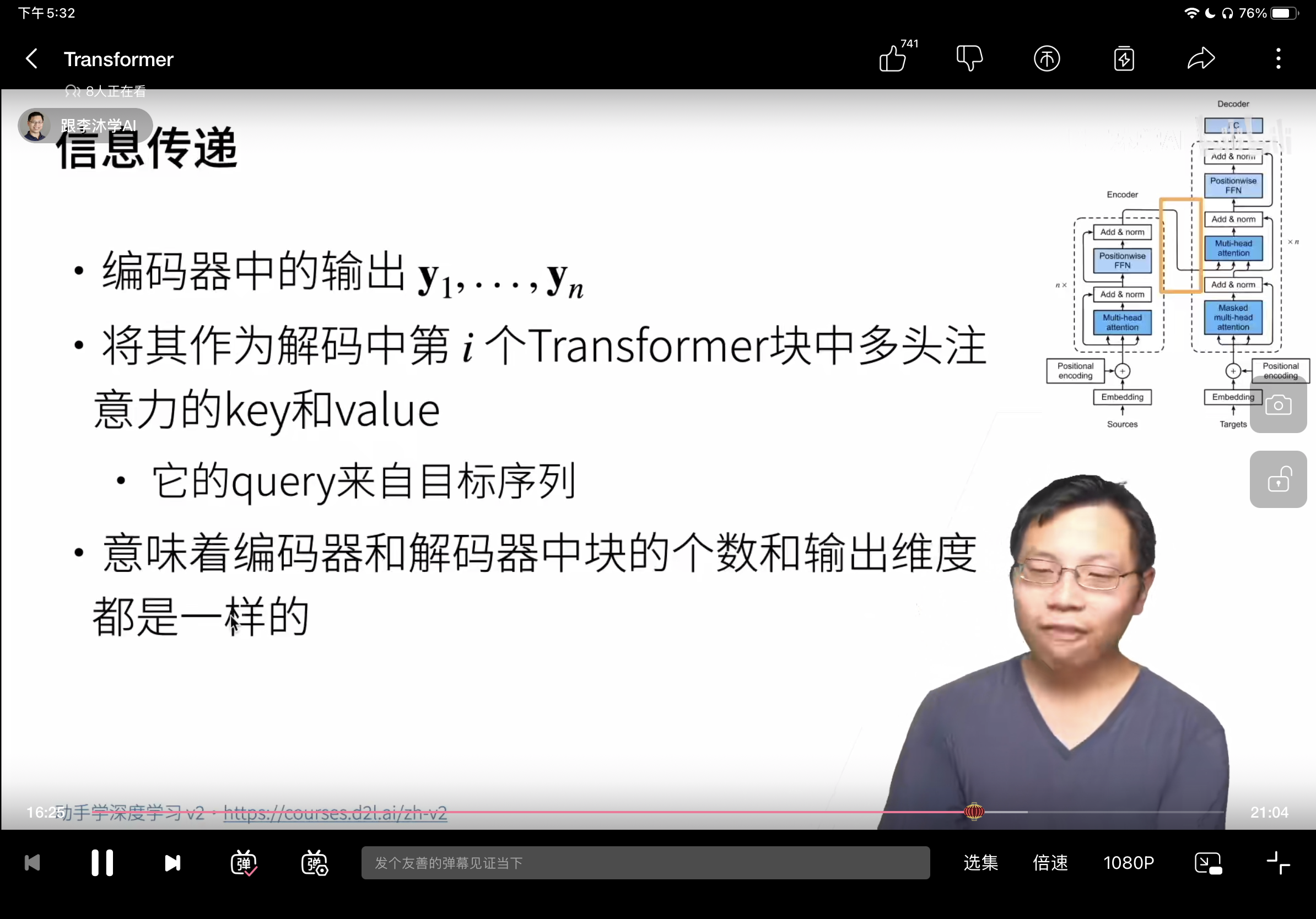
编码器里的是自注意力搞出来的key value
解码器里是个multi。key value来自编码器,query来自的是targets。(这里说的是训练)
5,预测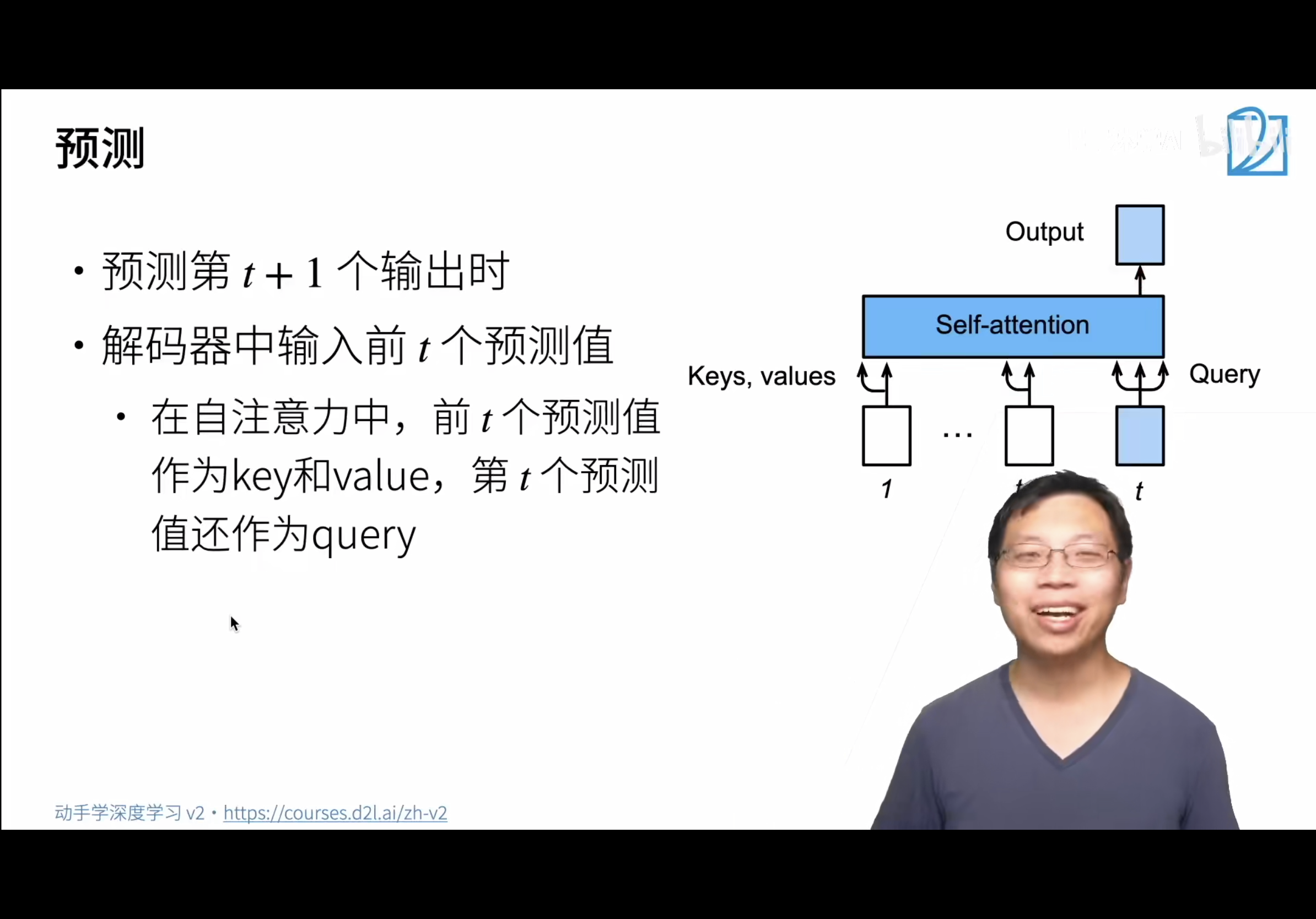
这个时候的输出就是对t+1时刻的预测
预测是一个一个往前走的
具体流程(训练阶段和预测阶段):
1,编码器
编码器训练阶段和预测阶段是一样的
例:每个编码器的输入为(64,10,32),那么输出也是(64,10,32)。输入代表一个长度为10 的句子,输出的每一行代表这个词对应的v,一共十个词,再输入到下一个编码器。
2,解码器
训练阶段:词的预测是一个一个输出的(这也是为什么要用mask掩蔽,因为每次输出只想看到前面词的状态和当前的输入),也就是一步一步(一步代表一个时间步,这一个时间步会经过n个解码器(也就是一整个解码器块)),每步输出一个词,也就是这么一个词在n个解码器之间传递。
这里有个时间步的概念,每个时间步输出一个词(其实也是一个矩阵不过有掩蔽了),这个词作为输出在下个时间步再次进入整个解码器。tips:在训练时,如果每次将预测结果输入还没有训练好的模型会让输出结果越走越偏。因此在训练时采用了”Teacher Forcing“技巧,不管模型输出的结果是什么,每次将正确的输出结果作为Decoder的输入继续预测。
预测阶段:不一样的是不再是确定的输入,而是上一步的输出作为下一步的输入。每一步一个词,最后组成句子。
3,每一个时间步,整个系统输出一个词到下一个时间步,
https://blog.csdn.net/weixin_42127358/article/details/121652158
好好悟,就是这个意思!!!!
总结
- transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
- 在transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
- transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
- transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。

若有收获,就点个赞吧
0 人点赞
