softmax用于常用于分类,m个输入n个输出
softmax运算原理
yhat可以视为属于类j的概率
softmax函数将未规范化的预测变换为非负并且总和为1,同时要求模型保持可导。 我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的总和为1,我们再对每个求幂后的结果除以它们的总和。如下式:
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)
2,损失函数用交叉熵函数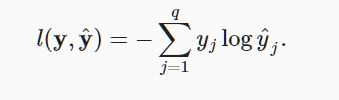
是什么为什么?https://zhuanlan.zhihu.com/p/70804197
对交叉熵求导:https://blog.csdn.net/qian99/article/details/78046329
结果是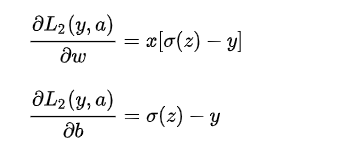
3,softmax及其导数

首先是获取数据集,train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
正式开始softmax从零实现(简易实现很简单看看就行了)
1,初始化模型参数
w,b 输入输出的维度
2,定义softmax操作
3,定义模型
def net(X): return softmax(np.dot(X.reshape((-1, W.shape[0])), W) + b)
4,定义损失函数
用的是交叉熵:
def cross_entropy(y_hat, y): return - np.log(y_hat[range(len(y_hat)), y]) cross_entropy(y_hat, y)
5,考虑分类精度
6,训练 和以前差不多
def train_epoch_ch3(net, train_iter, loss, updater): #@save
“””训练模型一个迭代周期(定义见第3章)”””
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
if isinstance(updater, gluon.Trainer):
updater = updater.step
for X, y in train_iter:
# 计算梯度并更新参数
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y)
l.backward()#
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.size)
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]

若有收获,就点个赞吧
0 人点赞
