seq2seq只用了最后的输出的隐藏状态,搞不到对应的词的位置。而机器翻译中每个生成的词可能相关于原句子中不同的词,所以seq2seq不能直接对此建模,所以引入注意力机制,可以翻译句子中某一词时把注意力放在原句子中对应位置。
具体的做法: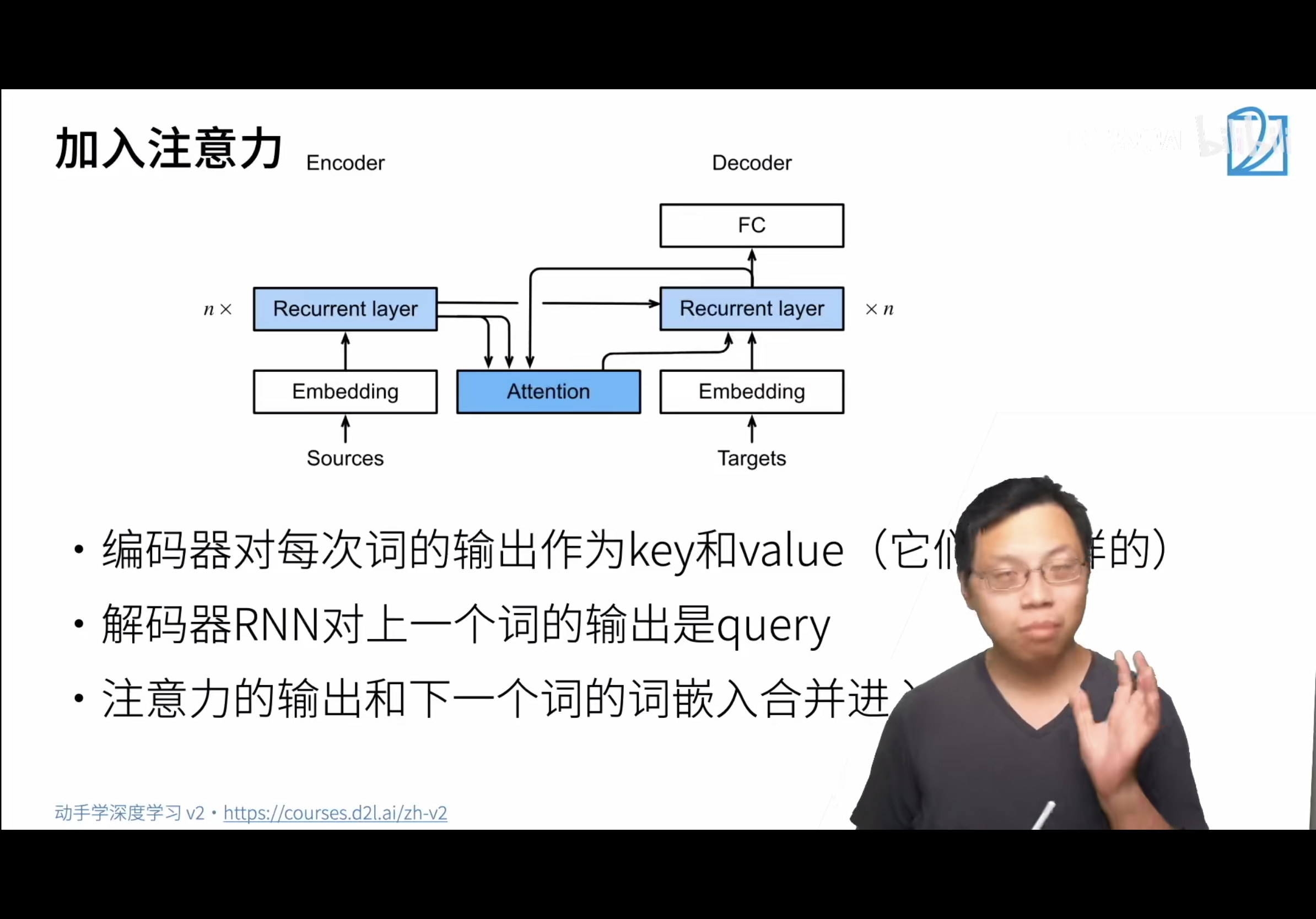
1,key和value在这里是一个东西,他们是一样的。假设句子长度为3,就会有3对,他们都是第i个词的rnn的输出。
2,query是在解码器的rnn中对上一个词预测的输出,例如预测完hello对应的了,把hello这个输出的作为query,来找附近的需要关注的点。其实就是找到相似的encoder的hidden state,再进入decoder。
4,例如法语world对应的query是法语hello。
3,用编码器建立索引,用解码器来定位关注点。
4,根据上一个词预测的结果在attention中寻找键值对,一同来预测下一个词。
5,
注意!!!!!!!!!!所说的输出都不是rnn的直接输出,而是输出的隐状态!!!!!!
总结
- 在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
- 在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值。

若有收获,就点个赞吧
0 人点赞
