过拟合和欠拟合 模型容量代表模型的复杂程度
模型容量代表模型的复杂程度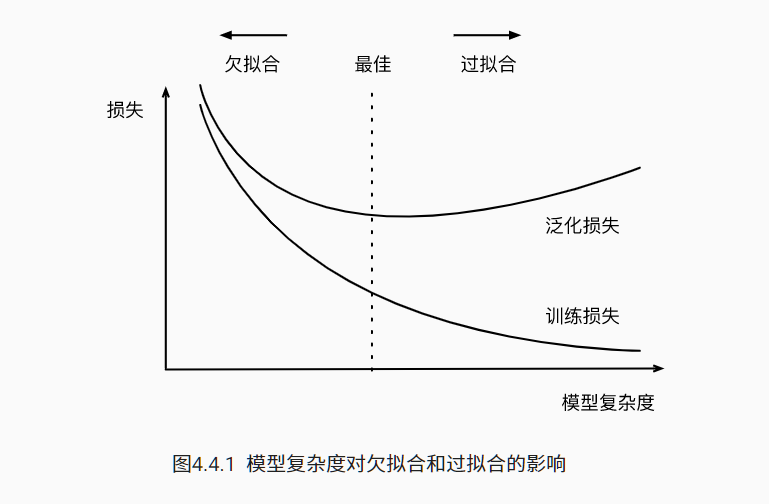
过拟合的解决方法:1,增大数据量,比如用数据量小的时候用k折交叉验证。2,正则化,通过添加惩罚项来限制模型复杂程度。3,丢弃法,把一部分神经元丢掉,即通过随机置零来控制复杂度。
欠拟合的方法:1,优化模型,一般都是模型过于简单了。
当数据集过小时K则交叉验证,这个问题的一个流行的解决方案是采用k折交叉验证。 这里,原始训练数据被分成K个不重叠的子集。 然后执行K次模型训练和验证,每次在K−1个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对K次实验的结果取平均来估计训练和验证误差。
1.正则化
L1和L2的区别
L1:L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值: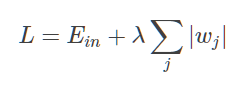
L2:L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和: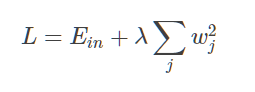

2、权重衰减
是为了调整函数的复杂性,权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为L2正则化。 (正则即不让权重过大导致过拟合)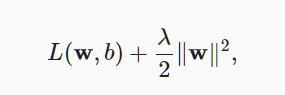
增加了L2范数惩罚项
- 正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度。
- 保持模型简单的一个特别的选择是使用L2L2惩罚的权重衰减。这会导致学习算法更新步骤中的权重衰减。
- 权重衰减功能在深度学习框架的优化器中提供。
- 在同一训练代码实现中,不同的参数集可以有不同的更新行为。
3、Dropout(丢弃法)可能比权重衰退效果好点
是个正则项,只在训练时使用
常用丢弃概率0.1 0.5 0.9

若有收获,就点个赞吧
0 人点赞
