1.Hive概述
1.1. 什么是Hive
基于Hadoop的数据仓库工具,可以将结构化(见ps:1)的数据文件映射为一张表,并提供类SQL查询功能。
本质是将HQL转化为MapReduce程序。
- Hive处理的数据存储在HDFS
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
1.2. Hive的优缺点
| 优点: | (1)操作接口采用类SQL语法,简单易上手 (2)免写MapReduce (3)Hive执行延迟高,用于数据分析等对实时性要求不高的场合 (4)Hive优势在于处理大数据,对于处理小数据没有优势(因为执行延迟高) (5)Hive支持用户自定义函数,用户可以根据需求实现函数 |
|---|---|
| 缺点: | (1)HQL表达能力有限 1)迭代式算法无法表达 2)数据挖掘方面不擅长 (2)Hive效率低 1)自动生成MapReduce,通常不够智能化 2)调优困难,粒度粗 |
1.3. Hive架构原理
| 英文名 | 中文名 | 解释 |
|---|---|---|
| Client | 用户接口 | hvie shell、JDBC、WEBUI |
| Metastore | 元数据 | 表名、表所属数据库(默认default)、表的拥有者、列/分区字段/表的类型(管理/外部表)、表数据所在目录。 默认存储在derby数据库中,只支持单客户端 更改为MySQL存储,可以支持多个客户端 |
| Hadoop | 哈度破 | 使用HDFS进行存储,使用MapReduce进行计算 |
| Driver | 驱动器 | 解析器、编译器、优化器、执行器 |
| SQL Parser | 解析器 | 将SQL字符串转换成抽象语法树AST |
| Physical Plan | 编译器 | 将AST编译生成逻辑执行计划 |
| Query Optimizer | 优化器 | 对逻辑执行计划进行优化 |
| Execution | 执行器 | 把逻辑执行计划转换成可执行的物理计划,对Hive来说是MR/Spark |
1.4. Hive的执行过程
将HQL通过解析器编译器优化器和执行器转换为MR程序。
1.5. Hive 和数据库的比较
| 不同点 | 解释 |
|---|---|
| 查询语言 | Hive使用的是类SQL语言 |
| 数据存储位置 | Hive数据存储在HDFS中; 数据库数据保存在块设备或本地文件系统中。 |
| 数据更新 | 数据仓库读多写少,因此Hive中不建议对数据的改写,所有的数据都是加载的时候确定好的; 数据库中的数据要经常修改的。 |
| 索引 | Hive访问数据中满足条件的特定值时需要暴力扫描全表,因此访问延迟高。引入MR后可以并行访问数据,因此对于大数据量的访问,Hive可以体现出优势; 数据库中会针对某些列建立索引,对于部分查询会有很高的效率。 |
| 执行 | Hive中的大多数查询的执行是通过MapReduce来实现的; 数据库通常有自己的执行引擎。 |
| 执行延迟 | Hive在查询时没有索引,所以需要扫描全表,延迟高,另外使用了MR,MR本身具有较高的延迟; 数据库在数据规模较小时执行延迟较低,当数据规模非常大的时候Hive的并行计算才能体现出优势。 |
| 可扩展性 | Hive是建立在Hadoop之上的,因此Hive的可扩展性和Hadoop是一致的; 数据库的扩展能力在100台左右。 |
| 数据规模 | Hive建立在集群上,可以利用MR进行并行计算,所以支持很大规模的数据; 数据库支持的数据规模较小。 |
2. Hive 语句及关键字
2.1. 筛选关键字 having和where
(针对第二点不同在Hive语句示例中有)
| where | having |
|---|---|
| 针对表中的列发挥作用,过滤数据 | 针对查询结果中的列发挥作用,过滤数据 |
| 后面不能写聚合函数 | 后面可以写聚合函数 |
| / | 只用于group by 分组统计语句 |
2.2. 排序语句 order/sort/distribute/cluster
语句案例见:Hive语句示例
| order by | 1. 全局排序,结果全局有序 1. 无论设置几个reducer,最终只生成一个 |
|---|---|
| sort by | 1. 每个reducer内部排序 1. 当有多个reducer时,全局不是有序 1. 当只有一个reducer时,效果等同于order by |
| distribute by | 1. 设置分区规则,相当于定义了一个MR中的Partitioner 1. 当单独使用sort by 时,数据会随机分配到reducer中(理论上应该是默认Hash分区) 1. 设置的ruducer数量最好等于设置的分区数量,不要大于分区数量。 1. 先分区后排序:distribute by xxx order by xxx |
| cluster by | 1. cluster by xxx 的效果相当于 distribute by xxx order by xxx 1. 该排序只能升序,不能指定排序规则 |
3. 分桶及抽样查询
语句案例见:Hive语句示例
1.概念及用途
概念:分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。 对于hive中每一个表、分区都可以进一步进行分桶。(可以对列,也可以对表进行分桶) 由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
用途:对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。使用分桶表进行抽样查询
2.创建分桶表并导入数据
想要分桶,需要通过MapReduce把文件put到文件系统中。
创建分桶表步骤:
- 创建一个普通表stu
- 向普通表stu中导入数据
设置属性 set hive.enforce.bucketing=true; (默认:false)
set mapreudce.job.reduces=-1; (默认:-1)<br /> d.通过子查询的方式将数据从普通表stu中导入到分桶表 stu_buck<br />ps:hive.enforce.bucketing设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用) ,一次作业产生的桶(文件数量)和reduce task个数一致。
3.抽样查询
select * from bucket_table tablesample(bucket 2 out of 4 on id);
TABLESAMPLE语法: TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子,将table总共分成y份
例如:
table总bucket数为16,tablesample(bucket 2 out of 4),表示总共抽取 16/4=4个bucket的数据,抽取第2(x)个,第6(x+y)个,第…,第12(x+3y)个bucket的数据。
x的值必须小于y的值。
4. 分区
语句案例见:Hive语句示例
分区:针对数据的存储路径。
分区表对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
5. 术语定义及参数设置
5.1. 严格模式与非严格模式
严格模式:Hive的查询默认为严格模式,某些查询在严格模式下无法执行,如:
1.查询一个分区表时没有进行分区限制
× hive>select from dwd_start_log;
√ hive>select from wdw_start_log where dt = ‘2020-01-01’;
2.带有order by的查询
× hive>select from student order by id; √hive>select from student order by id limit 20;
3.限制笛卡尔积的查询
×select from student join lesson; √select from student join lesson on student.stuid = lesson.stuid;
开启非严格模式:set hive.exec.dynamic.partition.mode=nonstrict
**
5.2. 静态分区与动态分区
语句案例见:Hive语句示例
静态分区与动态分区的主要区别在于静态分区是手动指定的,而动态分区是通过数据来进行判断,故:
静态分区的列是在编译时期,通过用户传递来决定的;
动态分区只有在SQL执行时才能确定。
启动动态分区需要同时开启非严格模式以及开启动态分区。
开启动态分区:set hive.exec.dynamic.partition=true
一个动态分区创建语句最多可以创建多少个动态分区:set hive.exec.max.dynamic.partitions=1000
6. 函数
6.1. 系统内置简单函数
语句案例见:Hive语句示例
NVL(column,xxx),效果:
- 空值赋值函数
- 如果column列的某个值为null则替换为xxx
- 注意,可能会存在和ifnull()函数一样的问题,即用这个函数查询的结果插入到其他表中,可能会改变列的属性。
case column when value1 then xxx 【else yyy】,效果:
- 当column列的某个值为value1时改为xxx【否则改成yyy】。
concat(xxx,yyy,zzz,…),效果:
- 拼接成字符串。
concat_ws(separator,str1,str2,…),效果:
- 用separator(某个字符串)将str1,str2…连接起来。
collect_set(column),效果:
- 行转列,利用UDAF函数来实现,直观变化就是行变少了(多进一出)
- 函数只接受基本类型数据,它的主要作用是配合group使用,将某列的值进行去重汇总,产生array类型字段。
- explode(column),效果:
Hive语句示例、上图
- 列转行,利用UDTF函数来实现,explode就是UDTF函数的一种(一进多出)
- 将一列array或map结构拆分成多行,以笛卡尔积的形式展现。
当使用UDTF函数的时候,hive只允许对拆分字段进行访问。
正确命令:select explode(location) from test_message; 错误命令:select name,explode(location) from test_message;
d. 当查询只有炸裂结果这一列的时候可以单独使用,如果涉及到列需要配合lateral view一起使用
…lateral view explode(xxx) tempTableName as resultColumnName;**
- lateral view,效果:
Hive语句示例、上图
- 用于和split, explode等UDTF(一进多出的函数)一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
6.2. 窗口函数 over()
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
- over()函数加在聚合函数的后面,以count(*) over()为例,over() 创建了一个数据集仅供前面的聚合函数使用。
- over()函数可以指定前面的聚合函数的作用范围为当前开窗的数据集。
- over()函数不加参数表示对于整个数据集进行开窗。
- over()函数给每一条数据都开一个窗口。
- 比方说,如下图所示
这部分👇👇👇👇👇👇👇👇👇👇👇写在over里面
current row:当前行 n preceding:往前n行数据 n following:往后n行数据 unbounded:起点,unbounded preceding 表示从开窗的起点,unbounded following表示到开窗的终点
这部分👇👇👇👇👇👇👇👇👇👇👇写在over外面
lag(col,n,str):往前第n行数据,没有第n行数据时显示str lead(col,n):往后第n行数据 ntile(n):对有序的数据进行分组,平均分为n组,返回每行数据所在组的编号
6.3. rank
RANK() 排序相同时会重复,总数不会变:1134
DENSE_RANK() 排序相同时会重复,总数会减少:1123
ROW_NUMBER() 会根据顺序计算:1234
使用:rank() over(…)
6.4. 日期函数
date_format(‘2020-01-01’,’yyyy-MM-dd’)
如果是 ‘2020/01/01’就不能直接使用date_format函数,要使用regexp_replace(‘2020/01/01’,’/‘,’-‘)将’/‘替换成’-‘。
datediff(‘2020-10-01’,’2020-01-04’)
date_add(‘2020-01-01’,100)
date_sub(‘2020-10-01’,100)
next_day(‘2020-02-01’,’Monday’) —— 2020年2月1日的下一个周一
last_day(‘2020-02-01’) —— 2020年2月的最后一天
6.6. 自定义函数
自定义函数(UDF:User-Defined Function)分为三种:
- UDF(User-Defined Function)
- 实现一进一出功能
- UDAF (User-Defined Aggregation Function)
- 聚合函数,多进一出
- 例:count/max/min/collect_set
- UDTF (User-Defined Table-Generating Function)
- 一进多出,表生成(lateral view UDTF() TempTable),所以在调用UDTF后需要给命名一张临时表
- 例:lateral view explode()
6.7. count()
count(*):所有行进行统计,包括NULL行
count(1):对所有行进行统计,包括NULL行
count(column):对column中非NULL行进行统计
7. union和union all
union 会将联合的结果去重,效率比union all 低
union all 不将联合的结果去重,所以效率高。
Hive中union和union all 的连接语句中不支持使用 orderby/clusterby/distributeby/sortby/limit
(只有最后一句可以使用,并对联合的结果进行排序或limit;而mysql中是可以在每一条语句中进行排序和limit操作的。)
select from a union all select from b union all select * from c;
8. Hive的优化
8.1. 存储/压缩
默认为TextFile存储
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
TextFile是不带压缩的存储格式,ORC和PARQUET是带压缩的存储格式
文件大小:ORC>PARQUET>TextFile
注:需要正确理解snappy压缩和存储格式之间的关系,ORC格式的文件默认采用ZLIB压缩,可以修改其压缩方式为snappy,ZLIB压缩比snappy压缩效果更好。
create table log_orc ( … ) row format… stored as orc;
并且,向orc存储格式的表中加入数据,要通过mr,即要用insert,不能用load,否则数据依然是TextFile格式
8.2. hql语句
- join 前对表进行空KEY过滤
- 空KEY转化成随机值(即不丢掉非异常数据,还可以进行负载均衡)
- group by 代替 distinct
- 避免笛卡尔积
- 行列过滤(where / select+列名)
8.3. 分区/开启动态分区
- 开启动态分区功能(默认true,开启)
hive.exec.dynamic.partition=true
**
- 设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
**
- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
hive.exec.max.dynamic.partitions=1000
**
- 在每个执行MR的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
**
- 整个MR Job中,最大可以创建多少个HDFS文件。
hive.exec.max.created.files=100000
**
- 当有空分区生成时,是否抛出异常。一般不需要设置。
hive.error.on.empty.partition=false
8.4. JVM重用
作用:JVM重用可以使得JVM实例在同一个job中重新使用N次。其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
缺点:开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
8.5. 推测执行
Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
8.6. 执行计划
explain [extended | dependency | authorization ] query语句
查看语句的执行计划,map、reduce数量,依赖关系。
8.7. Tez引擎
是基于Hadoop YARN之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。核心思想是将Map和Reduce两个操作进一步拆分,即:
Map被拆分成Input、Processor、Sort、Merge和Output,
Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等。
这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业,从而可以
- 减少Map的使用
- 只需要写一次HDFS
- 中间节点减少
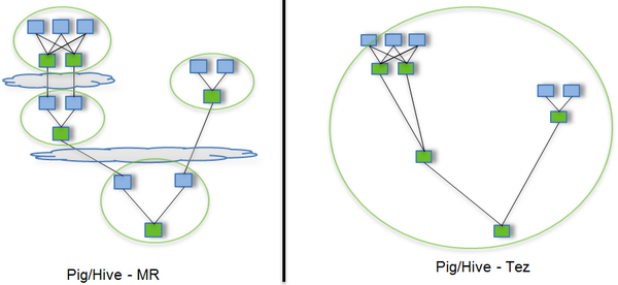
问题:会产生因为使用过多内存而被NodeManager杀进程的问题
解决方法:
- 关掉虚拟内存检查
- 设置Map 和 Reduce 任务的内存分配
8.8. mapJoin
将小表转换为Hash表结构读取到缓存中,启动MapTask扫描大表,根据大表中的每一条记录和小表形成的HashTable进行关联,并直接输出结果,这样就省去了Reduce阶段。
9. 数据倾斜
9.1. 合理设置map数
任务小文件多,减少map数(开启map也消耗时间)
任务逻辑复杂,增加map数量。
增加map的方法为:根据computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M公式,调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
设置最大切片值为100字节
set mapreduce.input.fileinputformat.split.maxsize=100;
9.2. 合理设置Reduce数
在设置reduce个数的时候也需要考虑这两个原则:
- 处理大数据量利用合适的reduce数;
- 使单个reduce任务处理数据量大小要合适;
9.3. 小文件合并
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
ps:
1.结构化、半结构化、非结构化
| 结构化数据 | 可以用关系型数据库表示和存储的数据,一般以行为单位(就是数据库中的行数据) id name age 1 mhj 24 2 lmf 25 |
|---|---|
| 半结构化数据 | 不符合关系型数据库的形式,但包含相关标记,用来分割语义元素(常见的有XML和JSON) |
| 非结构化数据 | 数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表表现的数据。 如 办公文档、文本、图片、各种报表、音频/视频等。 |
参考文献:

若有收获,就点个赞吧
0 人点赞
