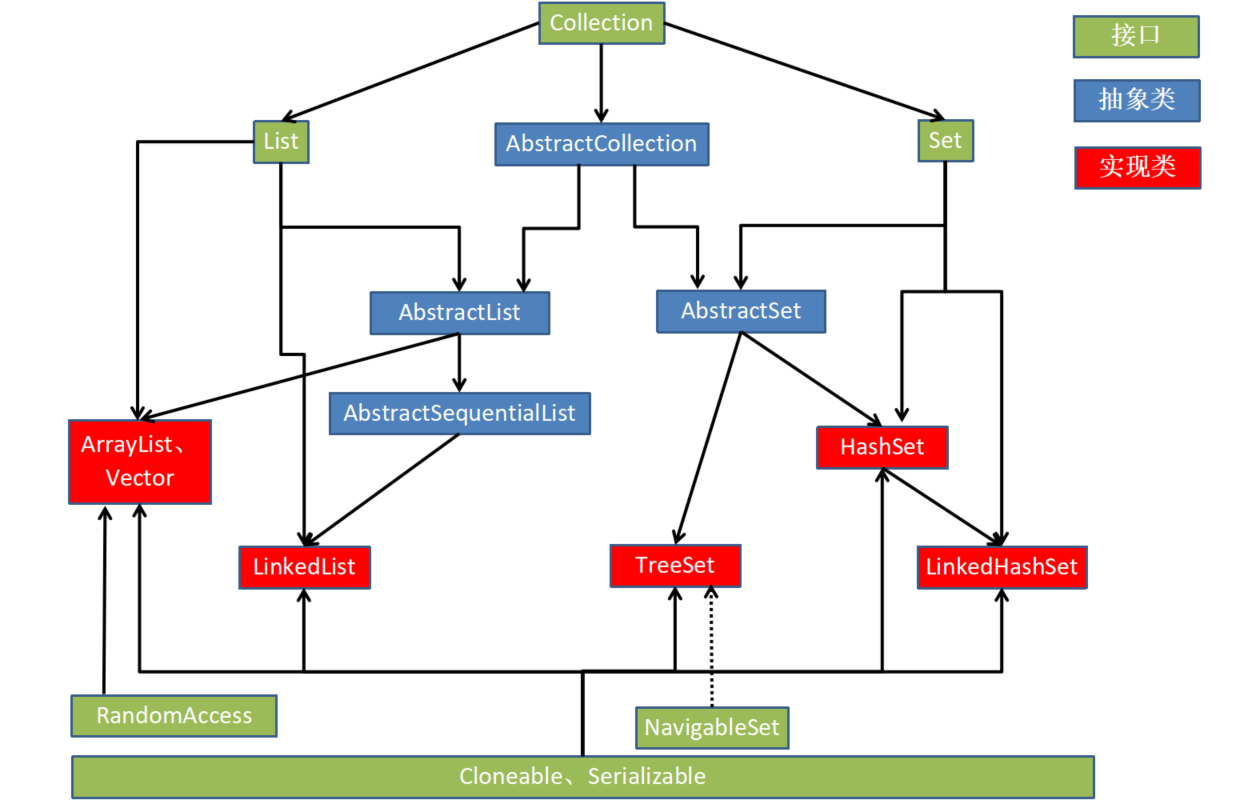
HashSet底层实现是HashMap
LinkedHashSet底层实现是LinkedHashMap
TreeSet底层实现是TreeMap,用来对元素进行排序。
本篇不对HashMap和LinkedHashMap做分析,想要深入理解HashSet和LinkedHashSet需要先理解HashMap和LinkedHashMap的底层。
1. 源码分析
1.1. HashSet成员变量:
//用于填充HashMap的value部分private static final Object PRESENT = new Object();//HashSet的底层实现是HashMap—— map 指向一个HashMap对象//LinkedHashSet的底层实现是LinkedHashMap—— map 指向一个LinkedHashMap对象private transient HashMap<E,Object> map;
1.2. 构造方法:
1.2.1 HashSet:
public HashSet() {map = new HashMap<>();}public HashSet(int initialCapacity, float loadFactor) {map = new HashMap<>(initialCapacity, loadFactor);}public HashSet(int initialCapacity) {map = new HashMap<>(initialCapacity);}
1.2.2. LinkedHashSet:
public HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}如果accessOrder为True 则通过get/getOrDefault/replace等方法获取到的元素会转移到链表尾部,如果accessOrder为false 则不会变化位置。public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;}
1.2.3. TreeSet
2. 面试题
2.1. HashSet的原理
HashSet的底层使用了HashMap实现,key对应的value全部设置为Object对象。
- 首先计算元素的hash值,然后取高16位与hash值进行异或操作,结果和数组长度-1进行&操作,获得对应的bucket。
- HashMap的底层结构是数组加链表,当某个链表的长度达到8(或者9)并且当数组的长度达到64时会对该链表进行红黑树化;
- put元素时会根据key的hashCode计算出元素在数组的index,然后尝试将该元素封装成Node或TreeNode对象插入到数组或数组中的链表或数组中的红黑树中;
- 当数组存储元素的个数达到数组扩容阈值时会对数组进行扩容,当某个链表的长度达到9,并且数组长度没有达到64时也会对数组进行扩容;
- 数组的扩容是将数组原来的容量乘2,将原来的扩容阈值乘2,同时将旧链表中的链表和红黑树拆分;
- get(key)时会根据key 的hashCode计算出其在数组的下标,然后通过==或equals()方法在数组或链表或红黑树中找到相同的key,如果找不到就返回null,找到了就返回对应的value。(为了尽量减少调用equals方法提高效率,开发时最好重写hashCode()和equals())
2.2. LinkedHashSet的原理
LinkedHashSet底层使用了LinkedHashMap实现,key对应的value全部设置为Object对象。
在HashSet的基础上通过节点间的双向链表实现了顺序遍历,是Set集合中唯一一个存取顺序一致的集合对象。
通过设置有参构造里的accessOrder可以选择当查找一个元素后将其移动到链表的末尾(true为移动,false为不移动)。
2.3. TreeSet有几种排序方式
两种:
- 传入类实现Comparable接口并重写compareTo()方法。
- TreeSet在生成对象时利用有参构造,传入一个Comparator接口的实现类对象,根据该实现类对象中重写的compara方法进行排序
2.4. TreeSet、TreeMap、Collections.sort分别如何比较元素
TreeSet和TreeMap 的比较元素方式相同,有两种比较方式:
- 传入类实现Comparable接口并重写compareTo()方法。
- 在生成对象时利用有参构造,传入一个Comparator接口的实现类对象,根据该实现类对象中重写的compara方法进行排序
Collections.sort()有两种重载方法:
第一种是直接传入实现了Comparable接口的类,并重写了compareTo方法;
第二种是传入一个类和一个Comparator接口的实现类,实现类中定义了排序的规则。
3. 奇奇怪怪的面试题
1.TreeSet里面放对象,如果同时放入了父类和子类的实例对象,那比较时使用的是父类的compareTo方法还是使用子类的comparaTo方法,还是抛异常?
答:会各自调用各自的方法,父类与子类之间不构成比较。
如果子类没有重写父类的compareTo方法,则都调用父类的比较方法,但父类子类之间不构成比较
案例:
import java.util.*;
public class TestTreeSet {
public static void main(String[] args) {
TreeSet<Node> ts2 = new TreeSet<>();
ts2.add(new Node("father1",123));
ts2.add(new NodeSon("son2",12));
ts2.add(new NodeSon("son1",1231));
ts2.add(new Node("father2",2314));
ts2.add(new Node("father3",89));
for (Node node : ts2) {
System.out.println(node);
}
}
}
class Node implements Comparable<Node>{
public String name;
public int id;
public Node(String name, int id) {
this.name = name;
this.id = id;
}
@Override
public int compareTo(Node o) {
return Integer.compare(this.id, o.id);
}
@Override
public String toString() {
return "Node{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
class NodeSon extends Node {
public NodeSon(String name, int id) {
super(name, id);
}
@Override
public int compareTo(Node o) {
return Integer.compare(o.id, this.id);
}
}
结果:
Node{name=’father3’, id=89} Node{name=’son1’, id=1231}
Node{name=’father1’, id=123}
Node{name=’son2’, id=12}
Node{name=’father2’, id=2314}

若有收获,就点个赞吧
0 人点赞
