// 初始化数组// 一个线程在put时如果发现tab是空的,则需要进行初始化private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;/*其中一个线程进入else if 后 会创建 table其他线程都在if中相互转让cpu然后再次循环,再次进入if当进入else if 的线程成功初始化后其他线程会陆续进入else if 或 进入while的条件判断判断后发现tab已经不为null,此时会退出循环。*/while ((tab = table) == null || tab.length == 0) {// sizeCtl默认等于0,如果为-1表示有其他线程正在进行初始化,本线程不竞争CPU// yield表示放弃CPU,线程重新进入就绪状态,重新竞争CPU,如果竞争不到就等,如果竞争到了又继续循环if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin// 通过cas将sizeCtl改为-1,如果改成功了则进行后续操作// 如果没有成功,则表示有其他线程在进行初始化或已经把数组初始化好了else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 当前线程将sizeCtl改为-1后,再一次判断数组是否为空// 会不会存在一个线程进入到此处之后,数组不为空了?if ((tab = table) == null || tab.length == 0) {// 如果在构造ConcurrentHashMap时指定了数组初始容量,那么sizeCtl就为初始化容量int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;// 如果n为16,那么就是16-4=12// sc = 3*n/4 = 0.75n, 初始化完成后sizeCtl的数字表示扩容的阈值sc = n - (n >>> 2);}} finally {// 此时sc为阈值sizeCtl = sc;}break;}}return tab;}
1. ConcurrentHashMap底层结构
1.1. JDK1.7
底层一个Segments数组,存储一个Segments对象,一个Segments中储存一个Entry数组,存储的每个Entry对象又是一个链表头结点。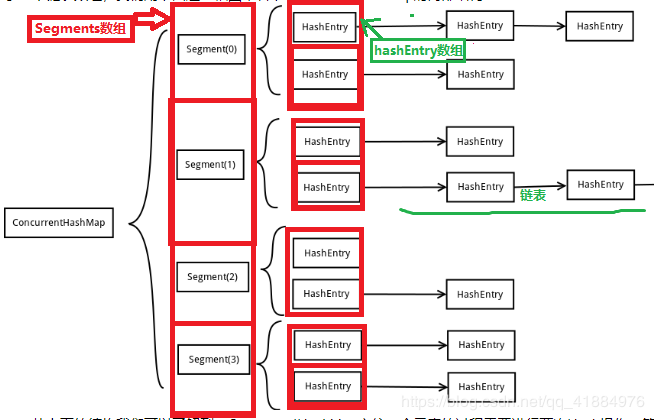
get():
1、第一次哈希 找到 对应的Segment段,
调用Segment中的get方法
2、再次哈希找到对应的链表,
3、最后在链表中查找。
// 外部类方法public V get(Object key) {int hash = hash(key.hashCode());return segmentFor(hash).get(key, hash); // 第一次hash 确定段的位置}//以下方法是在Segment对象中的方法;//确定段之后在段中再次hash,找出所属链表的头结点。final Segment<K,V> segmentFor(int hash) {return segments[(hash >>> segmentShift) & segmentMask];}V get(Object key, int hash) {if (count != 0) { // read-volatileHashEntry<K,V> e = getFirst(hash);while (e != null) {if (e.hash == hash && key.equals(e.key)) {V v = e.value;if (v != null)return v;return readValueUnderLock(e); // recheck}e = e.next;}}return null;}
put():
1、首先确定段的位置,
调用Segment中的put方法:
2、加锁
3、检查当前Segment数组中包含的HashEntry节点的个数,如果超过阈值就重新hash
4、然后再次hash确定放的链表。
5、在对应的链表中查找是否相同节点,如果有直接覆盖,如果没有将其放置链表尾部
当size超过阈值会进行rehash扩容。
1.2. JDK1.8
put方法:
1、检查Key或者Value是否为null,
2、得到Kye的hash值
3、如果Node数组是空的,此时才初始化 initTable(),
4、如果找的对应的下标的位置为空,直接new一个Node节点并放入, break;
5、
6、如果对应头结点不为空, 进入同步代码块
判断此头结点的hash值,是否大于零,大于零则说明是链表的头结点在链表中寻找,
如果有相同hash值并且key相同,就直接覆盖,返回旧值 结束
如果没有则就直接放置在链表的尾部
此头节点的Hash值小于零,则说明此节点是红黑二叉树的根节点
调用树的添加元素方法
判断当前数组是否要转变为红黑树
public V put(K key, V value) {return putVal(key, value, false);}final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());// 得到 hash 值int binCount = 0; // 用于记录相应链表的长度for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 如果数组"空",进行数组初始化if (tab == null || (n = tab.length) == 0)// 初始化数组tab = initTable();// 找该 hash 值对应的数组下标,得到第一个节点 felse if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 如果数组该位置为空,// 用一次 CAS 操作将新new出来的 Node节点放入数组i下标位置// 如果 CAS 失败,那就是有并发操作,进到下一个循环if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容else if ((fh = f.hash) == MOVED)// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了tab = helpTransfer(tab, f);else { // 到这里就是说,f 是该位置的头结点,而且不为空V oldVal = null;// 获取链表头结点监视器对象synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表// 用于累加,记录链表的长度binCount = 1;// 遍历链表for (Node<K,V> e = f;; ++binCount) {K ek;// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}// 到了链表的最末端,将这个新值放到链表的最后面Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) { // 红黑树Node<K,V> p;binCount = 2;// 调用红黑树的插值方法插入新节点if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// binCount != 0 说明上面在做链表操作if (binCount != 0) {// 判断是否要将链表转换为红黑树,临界值: 8if (binCount >= TREEIFY_THRESHOLD)// 如果当前数组的长度小于 64,那么会进行数组扩容,而不是转换为红黑树treeifyBin(tab, i); // 如果超过64,会转成红黑树if (oldVal != null)return oldVal;break;}}}//addCount(1L, binCount);return null;}
get方法
https://blog.csdn.net/qq_41884976/article/details/89532816
。。。待补充
2. 面试题
2.1. ConcurrentHashMap是如何实现线程安全的
分段锁 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
使用的是优化的synchronized 关键字同步代码块 和 cas操作了维护并发。
2.2. 和Hashtable的线程安全机制有什么联系
Hashtable是用 synchronized方法 和 synchronized代码块实现线程安全的。
JDK1.7 和 JDK1.8版本都用到了 synchronized代码块。
2.3. ConcurrentHashMap 和 Hashtable 的效率
ConcurrentHashMap JDK 1.7:使用分段锁,一个线程占用一个segment,其他线程可以操作其他segment。
ConcurrentHashMap JDK 1.8:put和get不用二次哈希,一把锁只能锁住一个链表或一棵红黑树,提高了并发效率。
Hashtable:使用synchronized方法锁,如果一个线程抢到锁,其他线程都要等待该锁释放,效率很低。

若有收获,就点个赞吧
0 人点赞
