1. 项目架构
2. ETL数据清洗
2.1. Flume拦截器
2.2. ods层->dwd层
原始数据层->明细数据层
通过定义UDF和UDTF函数对数据进行简单清洗,保持数据粒度一致。
1.UDF函数做清洗:如图所示,用服务器时间后的“|”对字符串做切割,如果切割出来的不是两个部分,则直接返回空字符串。
2.UDTF函数做清洗:过滤空数据——如果传入的et为空,直接返回不要。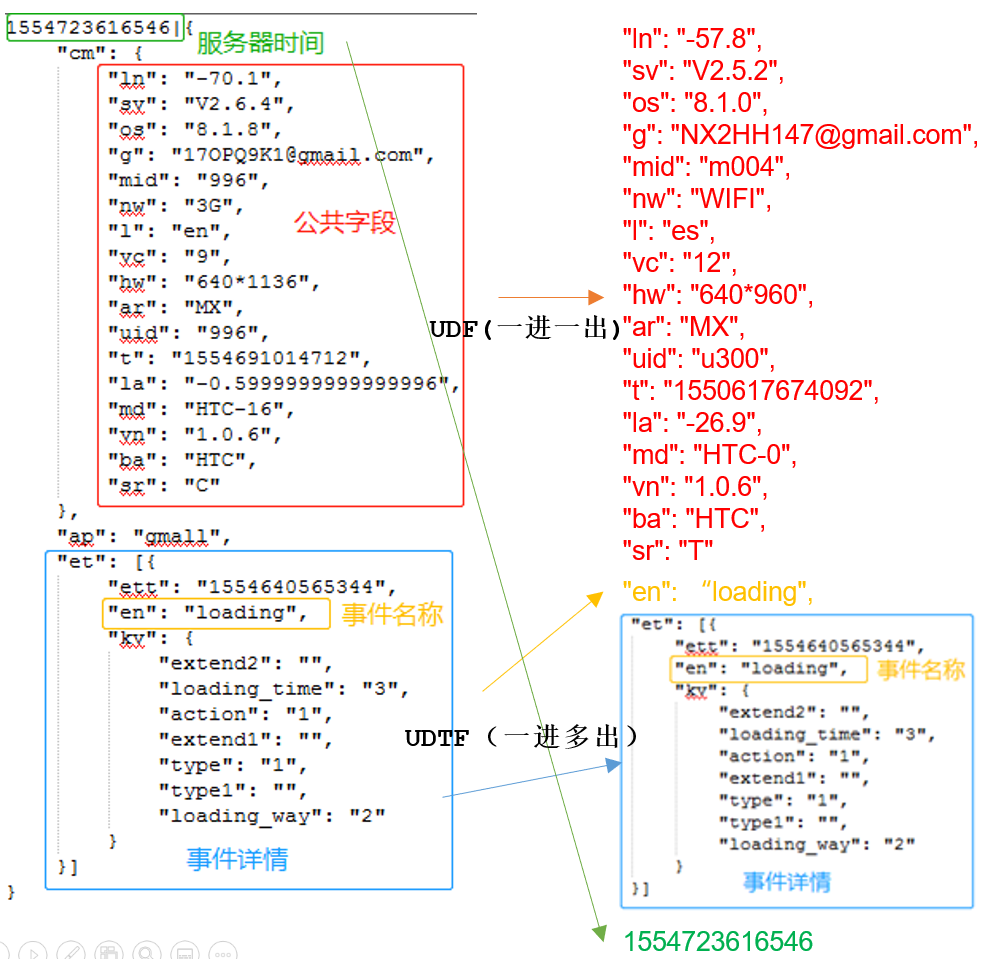
3. org.json.JSONObject
处理如下所示的JSON格式数据:
{"cm":{"ln":"-70.1","sv":"V2.5.2"},"ap":"gmall"}[{"ett":"12345123","en":"loading","kv":{"type":"1","type1":""},{...}}]
import org.json.JSONException;import org.json.JSONObject;public class TestJson {public static void main(String[] args) {String json = "{\"cm\":{\"ln\":\"-70.1\",\"sv\":\"V2.5.2\"},\"ap\":\"gmall\"}";try {JSONObject jsonObject = new JSONObject(json);JSONObject cm = jsonObject.getJSONObject("cm");String ln = cm.getString("ln");System.out.println(ln);} catch (JSONException e) {e.printStackTrace();}String json2 = "[{\"ett\":\"12345123\", \"en\":\"loading\", \"kv\":{\"type\":\"1\",\"type1\":\"\" }}]";try {JSONArray jsonArray = new JSONArray(json2);System.out.println(jsonArray.length());String string = jsonArray.getJSONObject(0).getJSONObject("kv").getString("type");System.out.println(string);} catch (JSONException e) {e.printStackTrace();}}}
4. 数据仓库
4.1. 数据仓库与关系型数据库的区别
| 特性 | 数据库 | 数据仓库 |
|---|---|---|
| 数据 | 在线交易数据,面向事务设计 | 历史数据,面向主题设计 |
| 冗余 | 避免冗余 | 引入冗余 |
| 面向 | 业务操作 | 数据分析 |
| 存取 | 读写操作 | 主要为读取 |
| 使用频率 | 高 | 低 |
| 要求响应时间 | 较短 | 可以很长 |
4.2. 数据分仓的优点缺点
优点:
- 把复杂问题简单化
将一个复杂的问题分解为多个步骤来完成,每层只处理单一的步骤,比较简单,并且方便定位问题。
- 减少重复开发
规范数据分层,通过中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据
不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦。
缺点:
- 产生大量的冗余数据
4.3. 具体分层
ods:原始数据层——存放原始数据,保持数据原貌不作处理
dwd:明细数据层——结构、粒度与原始表保持一致,对ODS层进行清洗(去除空值、脏数据、超范围的数据)
dws:服务数据层——以DWD层为基础,进行轻度汇总
ads:数据应用层——ADS层,为各种统计报表提供数据
4.4. OLAP和OLTP
OLAP:On-Line transaction processing,联机事务处理
OLTP:On-Line Analytical Processing,联机分析处理
OLAP:是数据仓库的主要应用,支持复杂的分析操作,侧重决策,并提供直观易懂的查询结果。强调数据分析,强调SQL执行时长,强调磁盘I/O,强调分区。
OLTP:是传统的关系型数据库的主要应用,是基本的日常的事务处理,如银行交易。强调数据库内存效率,强调内存各种指标的命令率,强调并发操作。

若有收获,就点个赞吧
0 人点赞
