1 api介绍
- sklearn.cluster.KMeans(n_clusters=8)
- 参数:
- n_clusters:开始的聚类中心数量
- 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
2 案例
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果: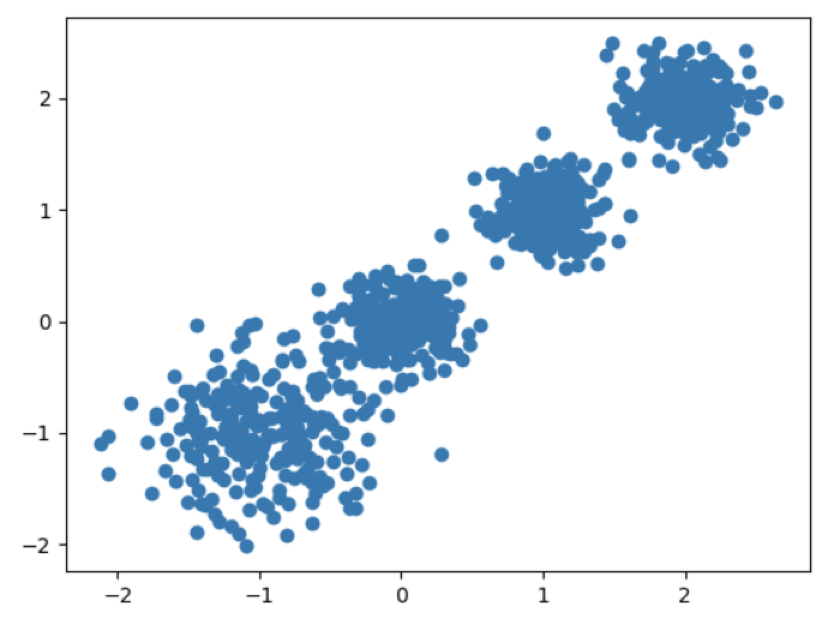
聚类参数n_cluster传值不同,得到的聚类结果不同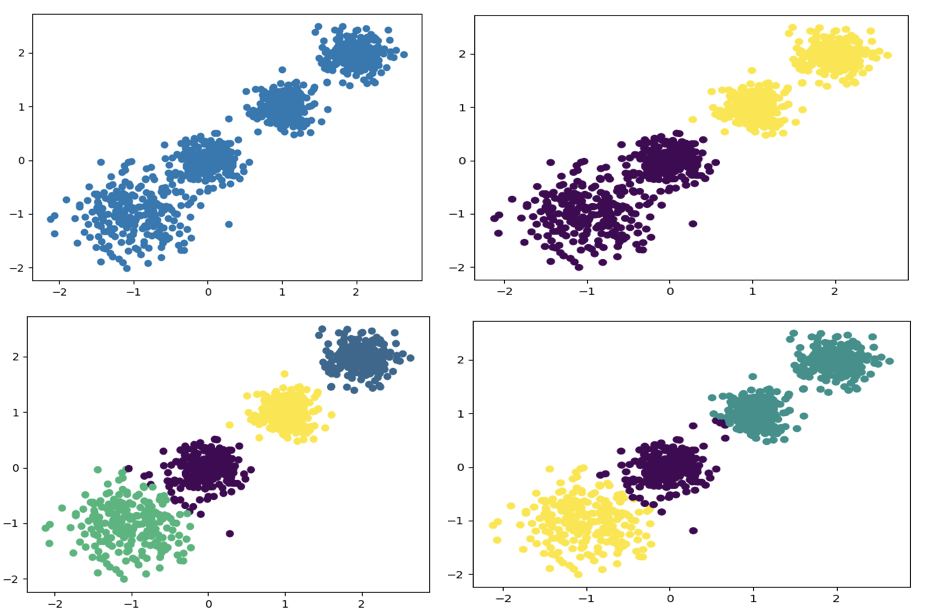
2.1流程分析
2.2 代码实现
1.创建数据集 ```python import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import calinski_harabaz_score
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
- 参数:
创建数据集
X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,
簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]], cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=9)
数据集可视化
plt.scatter(X[:, 0], X[:, 1], marker=’o’) plt.show()
2.使用k-means进行聚类,并使用CH方法评估```pythony_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X)# 分别尝试n_cluses=2\3\4,然后查看聚类效果plt.scatter(X[:, 0], X[:, 1], c=y_pred)plt.show()# 用Calinski-Harabasz Index评估的聚类分数print(calinski_harabaz_score(X, y_pred))

若有收获,就点个赞吧
0 人点赞
