VIBE: Video Inference for Human Body Pose and Shape Estimation
原文链接:https://www.yuque.com/jinluzhang/researchblog/VIBE
Summary🔖
文章提出用于人体姿势和形状估计的视频推理方法,该方法不需要使用3Dground truth数据,从未标注的2D video中提取人体运动的时序信息,输出SMPL的pose和shape的参数。
该方法使用基于对抗训练的学习框架,利用AMASS数据集中的真实人体动作进行对抗训练,使用动作判别器来区分真实的人类动作与本文设计的时序姿态和动作回归网络产生的3D人体动作。
文章做了大量的训练证明和分析运动性的重要性,实验方法值得借鉴。
Motivation👓
尽管目前已经在单图像3D姿势和动作估计单图像3D姿势和动作估计方面取得了进展,但由于缺少用于训练的真实的3D运动数据,之前的人类运动的时间模型不能够捕获到人类实际运动的复杂性和可变性因此现有的基于视频的SOTA方法无法产生准确且自然的运动序列
Method💡
Overview
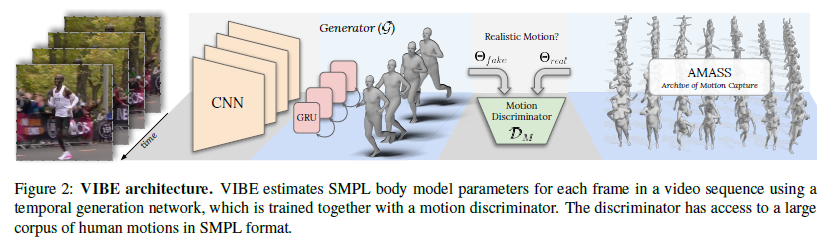
VIBE的预训练模型使用的是一篇3D Pose and Shape的论文HMR(CVPR 2018)的方法,这项工作从单张RGB图片重建人体的mesh,而且是end-to-end的,不需要经过2D pose进行过渡。由于使用了Discriminator,也不需要2D-3D数据对。VIBE基于这篇论文的方法,将数据对象从图片扩展到了视频。
该方法首先通过Resnet50提取图片的空间特征,然后经过GRU处理序列,学习它的时间特征。再通过回归层得到82个SMPL参数构造,将这些序列参数计算对抗损失的loss,输入到判别器与大型数据集AMASS进行对抗训练,训练的目的是使得估计的运动与AMASS数据集真实的运动信息之间的差异无法分别。其中motion discriminator包含GRU并引入了自注意力机制(self-attention)。并通过SMPL的mesh vertices得到3D关节坐标,投影得到2D坐标,并分别计算Loss。
简单来说,网络结构如下:
- CNN编码器: ResNet-50
- Temporal编码器: 2层GRU
- SMPL回归层: 2层FC
- Motion鉴别器: 2层GRU + 2层FC的self-attention
3D Body Representation
We represent the human body as a 3D mesh encoded using the SMPL [42] model.
对于3D pose和shape的表示方法,文章采用SMPL的表示,SMPL方法简介:
SMPL的总体模型输出人体shape和pose的参数,该模型参数中β和θ是其中的输入参数,
其中β代表人体高矮胖瘦、头身比等比例的10个参数;
θ是代表人体整体运动位姿和24个关节相对角度的75(24*3+3 + 每个关节点3个自由度,再加上3个根节点)个参数;
β参数是ShapeBlendPose参数,可以通过10个增量模板控制人体形状变化: 具体而言,每个参数控制人体形态的变化可以通过动图来刻画
⭐Temporal Encoder
输入:视频连续帧序列
输出:对于连续帧序列的每个帧,输出SMPL的75+10+85个参数
时序编码器结构:一层GRU和一个回归层(残差回归或者全连接层)
**
GRU用于提取时序信息,在GRU层后面加入self-attention机制,对生gru输出的参数加权重。
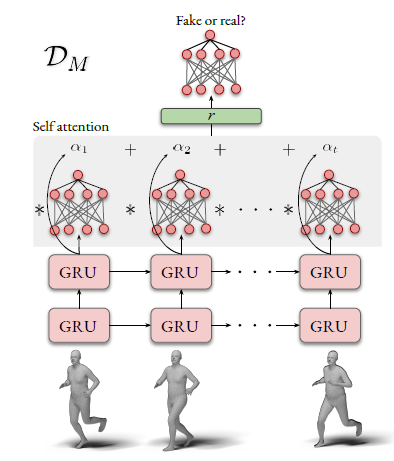
Motion Discriminator
输入:SMPL的75+10+85个参数
输出:[0, 1]之间的预测值,表示属于人类运动的概率
当忽略运动的时间连续性时,多个不正确的pose都可能会被视为正确的pose。为了减轻这种情况,论文中使用Motion Discriminator来判断生成的pose序列是否对应于现实序列,即AMASS数据集中的运动序列。
判别器结构:两层GRU用于提取SMPL之间的时序信息,self-attention跟在其后聚合GRU输出的编码向量,最后由线性层得出判别概率。
Loss
- 生成器(时序编码器)的loss函数为
 ,2D, 3D, SMPL的loss为时序编码器的loss,
,2D, 3D, SMPL的loss为时序编码器的loss, 是运动判别器中对抗训练中生成器生成shape的判定概率的loss
是运动判别器中对抗训练中生成器生成shape的判定概率的loss
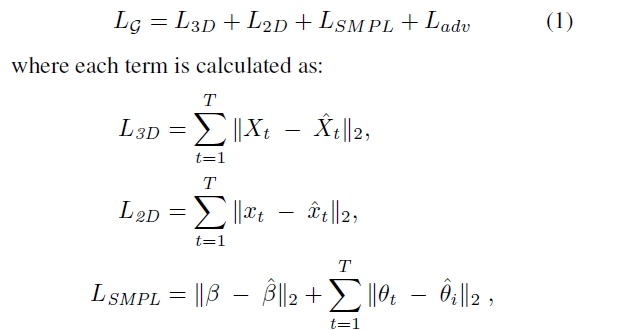
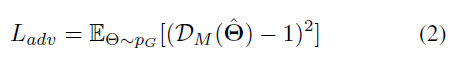
- 训练运动鉴别器,即鉴别器的Loss:
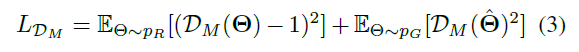
Evaluation🧪
Dataset
Training
- 2D video (input)
- GT
- PennAction
- PoseTrack
- pseudo GT (annotated using a 2D keypoint detector)
- InstaVariety
- Kinetics-400
- GT
3D annotation
3DPW
- MPI-INF-3DHP
-
Metrics
Mean Per Joint Position Error (MPJPE): Protocol 1,关节点坐标误差的平均值
- 网络输出的关节点坐标与ground truth的平均欧式距离(通常转换到相机坐标)
Procrustes analysis MPJPE (P-MPJPE): Protocol 2,基于Procrustes分析的关节点坐标误差的平均值
- 先对网络输出进行刚性变换(平移,旋转和缩放)向ground truth对齐后,再计算MPJPE
Percentage of Correct Key-points (PCK),正确关键点的百分比
- 如果预测关节与ground truth之间的距离在特定阈值内,则检测到的关节被认为是正确的
Per Vertex Error (PVE),顶点误差
- SMPL的Vertex为6890×3,计算其与ground truth之间的距离
Acceleration error(Accel),加速度误差
- 预测的3D坐标与ground truth的加速度平均差 (mm/s2),用来衡量平滑性,在论文[6]中提出
- 加速度误差计算代码如下,来源于human_dynamics
def compute_accel(joints):"""Computes acceleration of 3D joints.Args:joints (Nx25x3).Returns:Accelerations (N-2)."""velocities = joints[1:] - joints[:-1]acceleration = velocities[1:] - velocities[:-1]acceleration_normed = np.linalg.norm(acceleration, axis=2)return np.mean(acceleration_normed, axis=1)
Setup
网络训练的具体参数
a single Nvidia RTX2080ti GPU
- T = 16 as the sequence length
- 2-layer GRU with a hidden sizeof 1024
- SMPL regressor has 2 fully-connected layers with 1024 neurons each, followed by a final layer
- For self attention, we use 2 MLP layerswith 1024 neurons each and activation to learn the tanh attention weights.
- uses L-BFGS optimizer with a strong Wolfe line search
- use Adam optimizer[32] with a learning rate of
 for the G and DM,
for the G and DM,
Result
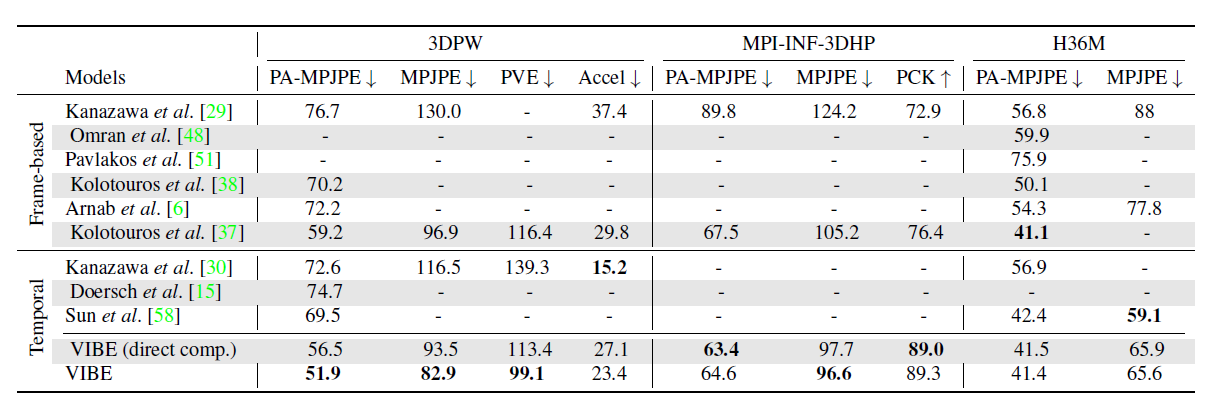
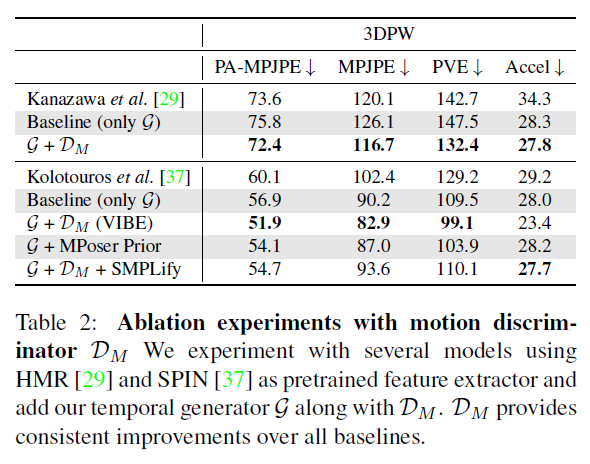
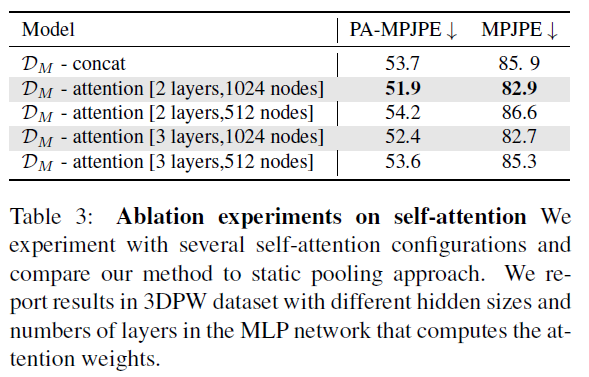
Conclusion⭐️
Contribution
- 提出了基于对抗训练的方法,生成更贴近运动学和形态学的shape与pose
- 扩展了fitting-in-the loop的训练方法到video上
- 使用self-attention使网络更关注temporal info
-
Rethink❓
探索使用视频训练的网络,监督单帧图像的方法
- 多人问题
- 遮挡问题
- 使用其他注意力架构(如transformers)
探索dense motion cues(如光流)是否可以提供更多信息
Track📚
VIBE的预训练模型使用的是一篇3D Pose and Shape的论文HMR(CVPR 2018)的方法,这项工作从单张RGB图片重建人体的mesh,而且是end-to-end的,不需要经过2D pose进行过渡。由于使用了Discriminator,也不需要2D-3D数据对。VIBE基于这篇论文的方法,将数据对象从图片扩展到了视频。
Kanazawa A, et al. End-to-end recovery of human shape and pose, CVPR 2018.
- SMPL模型,估计shape与pose
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi person linear model. In ACM Trans. Graphics (Proc. SIGGRAPH Asia), 2015. 2, 4 - SPIN model-fitting in the loop的训练方法(图像上)
Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, andKostas Daniilidis. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In International Conferenceon Computer Vision, 2019. - GAN网络对抗训练(略读,结合博客了解,写一篇博客出来)
- 实验中比较的SOTA方法

ref:

若有收获,就点个赞吧
0 人点赞
