Blind Video Temporal Consistency via Deep Video Prior
原文链接:https://www.yuque.com/jinluzhang/researchblog/DVP
Summary🔖
通过学习视频时序信息的一致性提高图像处理算法在视频上的稳定性,或许可以借鉴一下时序信息的利用策略
Motivation👓
静态图像的算法在单个图像处理中表现出色,但如果直接用于视频时往往会遇到时域不一致问题,具体表现比如图像上色中的闪烁问题等。文章提出一种通用的框架,可将图像处理算法转换为对应的具有高度时域一致性的视频处理算法,通过利用时域一致性提高图像算法应用在视频上的稳定性。
Method💡
- 文章中提出的方法的核心是DVP(Deep Video Prior)——深度视频先验知识;
即:CNN对于视频不同帧之间的对应图像块的网络预测输出倾向于一致
文章方法利用DVP进行视频中图像算法的校验
**
文章中的方法基于之前的DIP方法
不需要训练数据集,只需要在单个视频上进行训练即可
**
- 提出了一种迭代加权训练(IRT)策略来处理多模态时域不一致的问题
Overview
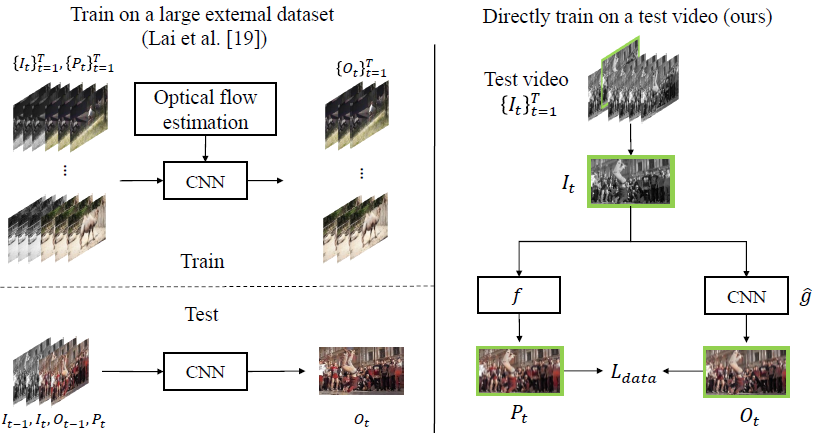
图中左侧是之前的方法[1],需要在external dataset上进行训练,训练数据集需要配对的输入帧与处理帧,需要提取光流;
右侧是本文所提出的方法,不需要额外的训练数据集,使用输入的test video即可进行训练,且不需要光流之类的运动信息;
图片中,
Deep Video Prior(DVP)
本文提出的方法是使用全卷积网络进行模拟图像算法f,学习时域的一致性,对CNN使用随机初始化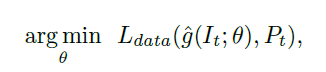
文章中CNN部分使用的是U-Net和perceptual loss
Loss的代码:
def Lp_loss(x, y):ChenyangLEI, 23 days ago: • upload all codesvgg_real = utils.build_vgg19(x*255.0)vgg_fake = utils.build_vgg19(y*255.0,reuse=True)p0=compute_error(vgg_real['input']/255.0,vgg_fake['input']/255.0)p1=compute_error(vgg_real['conv1_2']/255.0,vgg_fake['conv1_2']/255.0)/2.6p2=compute_error(vgg_real['conv2_2']/255.0,vgg_fake['conv2_2']/255.0)/4.8p3=compute_error(vgg_real['conv3_2']/255.0,vgg_fake['conv3_2']/255.0)/3.7p4=compute_error(vgg_real['conv4_2']/255.,vgg_fake['conv4_2']/255.)/5.6p5=compute_error(vgg_real['conv5_2']/255.,vgg_fake['conv5_2']/255.)*10/1.5return p0+p1+p2+p3+p4+p5
Iteratively Reweighted Training (IRT)
这个部分不是我要看的重点,所以只简要概括一下:
这部分的作用是解决算法对于单一输入输出多个预测结果的情况,比如上色算法中同一个像素或区域可能会被着色为两种颜色,作者称这类问题是多模态不一致问题。
DVP解决的时序不一致问题属于单模态问题(所有预处理帧接近于同一模式但是相互之间略有不一致),无法解决上述的多模态问题。
在IRT中,置信度旨在为每个像素从多种模式中选择一种主模式,而忽略离群值(一种次要模式或多种模式)。作者通过增加网络输出中的通道数量(例如,两个RGB图像为六个通道)以获得两个输出:一个主帧; 和一个离群帧。最终我们通过置信图来选择不同的像素用以训练两个不同的帧。

Conclusion⭐️
Contribution
Track📚
- 本文的启发工作:Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. In CVPR, 2018.
- 文章中对比的工作:Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. Learning blind video temporal consistency. In ECCV, 2018.
ref:
[1] Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. Learning blind video temporal consistency. In ECCV, 2018.

若有收获,就点个赞吧
0 人点赞
