3D Human Pose Machines with Self-supervised Learning
Summary
本文提出了一种带有自监督校正机制的3D Pose估计方法,这篇论文是T-PAMI上的一篇文章,不过发表时间是在2019年初,很多概念和方法现在看来并没有很强的冲击,但是在校正部分使用2D Pose对3D Pose的投影进行自监督学习,使得3D Pose的过程具有2D 上的几何一致性,这部分的理念值得借鉴。
Motivation
- insufficient 3D pose data for training
- domain gap between 2D space and 3D space
Method
this paper proposes a simple yet effective self-supervised correction mechanism to learn all intrinsic structures of human poses from abundant images
原文👆
本文提出了一种简单有效的自监督校正机制,可以从丰富的图像中学习人体姿态的内在结构。注意这里并不是指全部流程的自监督学习,而是提出了一种自监督校正机制。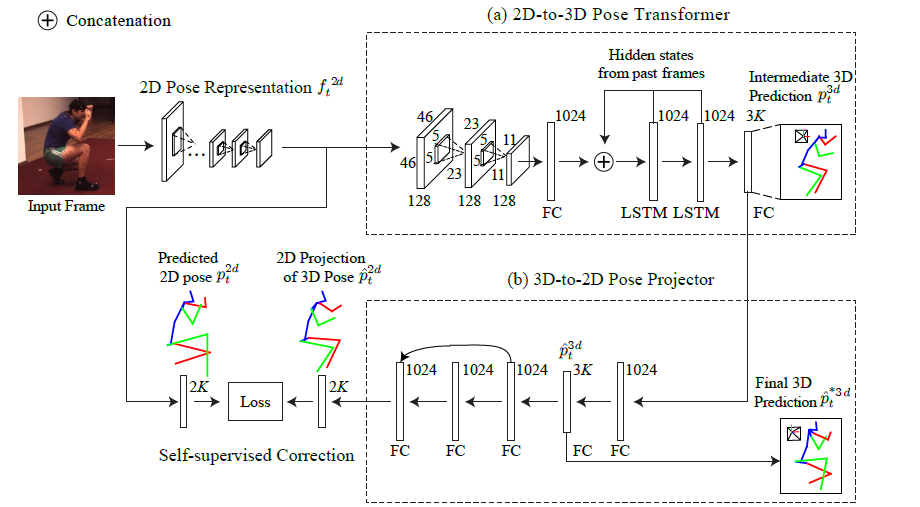
方法的概览如上,2D Pose部分采用了CPM,主要部分分为2D-to-3D Transformer和3D-to-2D Projection。
2D-to-3D Transformer
这部分就是利用LSTM进行时序上的利用以生成初级的3D pose,是最初利用时序信息的一个想法,不过后来出现了更多的时序信息方法比如空洞卷积等。
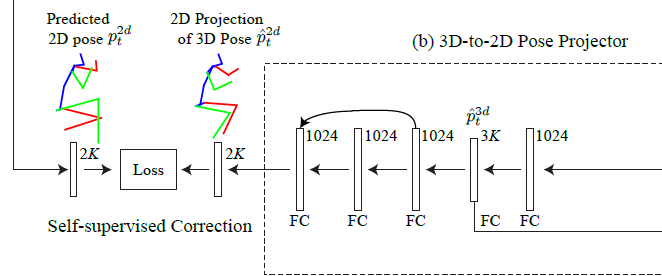
3D-to-2D Projection
上面生成的初级的3D pose输入到这一部分,右面两层FC用于回归输出3D Pose,用于和GT计算损失(从这里可以看出来这个方法不是完全自监督的方法),之后三层FC是对3D Pose进行投影生成2D Pose,和CPM生成的2D Pose进行计算Loss。
这里应该是认为CPM具有相当高的2D Pose Estimation的准确度,和它计算出的Pose进行Loss计算可以获取2D的结构一致性,从而校正“domain gap between 2D space and 3D space”。

Detail of train and test
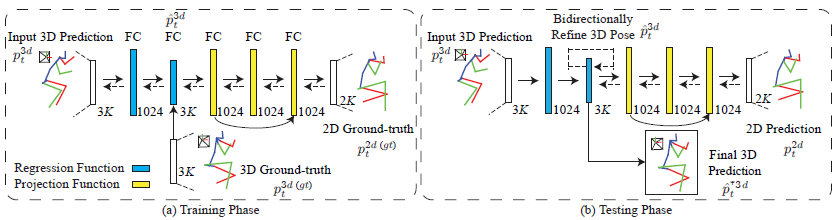
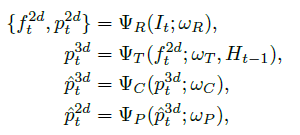
Loss of CPM
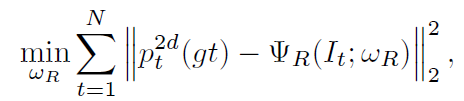
这里对于CPM使用的是监督学习方式,使用2D GT对CPM进行Loss计算
Loss of 3D Transformer(2D-to-3D)
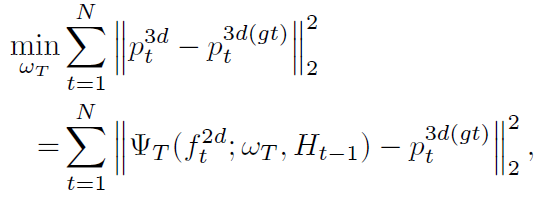
对于3D Transformer Module,使用监督学习计算regression的Loss
Loss of 2D Projector(3D-to-2D)
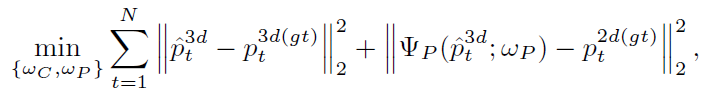
包含regression function 和projection function两部分,使用的也是监督学习
Loss of Inference
在这部分是作者提出的自监督校正机制:
Through minimizing the difference between p2dt and ^p2dt , our model is capable of bidirectionally refining the regressed 3D poses ^p3dt via the proposed self-supervised correction mechanism
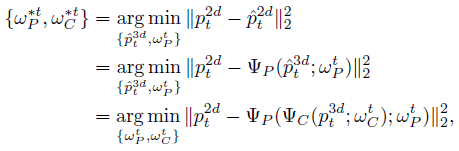
Conclusion
Contribution
- 提出自监督校正机制使3D Pose获得2D Pose的几何信息
在丰富的2D Pose data中提高3D pose 的准确性
Weak
只有自监督校正模块自监督,其他都是监督学习,整个流程不是一个自监督的框架
- 几何信息的获取并不包括深度信息,2D 与3D之间的domain gap是否可以克服还不可知,对于效果有帮助,但应该还不是一个完善的solution。
-
Track
C.-H. Chen and D. Ramanan, “3d human pose estimation = 2d pose estimation + matching,” in CVPR, 2017.
- G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis, “Coarseto-fine volumetric prediction for single-image 3D human pose,” inCVPR, 2017.
- D. Tome, C. Russell, and L. Agapito, “Lifting from the deep: Convolutional 3d pose estimation from a single image,” in CVPR,2017.
- M. Lin, L. Lin, X. Liang, K. Wang, and H. Cheng, “Recurrent 3dpose sequence machines,” in CVPR, 2017.
- H. Yasin, U. Iqbal, B. Kr¨ uger, A.Weber, and J. Gall, “A dual-source approach for 3d pose estimation from a single image,” in CVPR,2016.
- X. Zhou, Q. Huang, X. Sun, X. Xue, and Y. Wei, “Towards 3d human pose estimation in the wild: a weakly-supervised approach,” in ICCV, 2017.
ref:

若有收获,就点个赞吧
0 人点赞
