
可以看出这四个部分都是与人体姿态有关的,也是姿态估计的具体分支
姿态识别
姿态识别一般流程如下:

可以看出人体分割与人体姿态识别是姿态识别大类的两个关键步骤,人体分割是人体姿态识别(动作识别、身份识别等)的基础。
人体分割-人体骨骼关键点检测(skeleton)
人体分割使用的方法可以大体分为人体骨骼关键点检测、语义分割等方式实现。人体骨骼关键点检测输出是人体的骨架信息,一般主要作为人体姿态识别的基础部分,主要用于分割、对齐等。
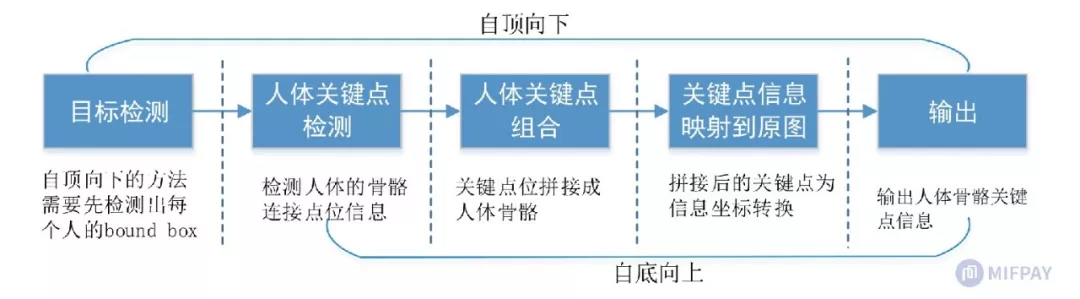
人体骨骼关键点检测是一种多方面任务,包含了目标检测、人体骨骼关键点检测、分割等。
人体骨骼关键点检测可以分为二维(2D)和三维(3D)的人体骨骼关键点检测;
按照检测的方法又能分为自底向上、自顶向下两个方式
人体骨骼关键点检测的挑战:
- 每张图片中包含人的数量是未知的,图像中人越多,计算复杂度越大(计算量与人的数量正相关),这使得处理时间变长,从而使real time变得困难。
- 人与人之间会存在如接触、遮挡等关系,导致将不同人的关键节点区分出来的难度增加,有可能会将骨骼关键点误认为是另一个人的。
- 关键点区域的图像信息比较难区分,也就是说某个关键点检测时容易出现检测位置不准或者置信度不准,甚至将背景的图像当成关键点图像的错误。
- 人体不同关键点检测的难易程度是不一样的,对于腰部、腿部这类没有比较明显特征关键点的检测要难于头部附近关键点的检测,需要对不同的关键点区别对待。
2D人体骨骼关键点检测实现

代表作:
自顶向下:RMPE (AlphaPose) https://arxiv.org/abs/1612.00137v3
自底向上:PAFs(OpenPose) https://arxiv.org/abs/1611.08050
2D+人体骨骼关键点检测实现
实质是:2D图像+3D重建
2D+人体骨骼关键点检测多使用3D重建的方法,一般输入都是RGB的2D图像数据,首先使用2D人体骨骼关键点检测的方法检测出2D的人体骨骼关键点后,再使用3D重建的方式,将2D的关键点信息转到3D的空间中,输出的就是3维人体骨骼关键点信息。这种方法使用的图像数据不是真的3D数据,输出的3维的信息主要是通过2D到3D重建的方式实现的。
2D+人体骨骼关键点检测输出的人体骨骼关键点信息是3D数据,即每个关节都是一个3D坐标(x,y,z)
代表作:DensePose https://arxiv.org/abs/1802.00434
3D人体骨骼关键点检测:
根据输入图像数据是RGB还是RGBD可分为2D+人体骨骼关键点检测、3D人体骨骼关键点检测。
输入的图像数据:RGBD(3D)
Depth Image实际上也是一幅真实的3D图像数据,Depth Image包含了深度信息、图像的高宽信息。CNN+RNN是目前的主流方法。
人体姿态识别
人体姿态识别包括动作识别、身份识别两个方面,关键在人体特征提取,人体特征提取主要完成动作特征提取、身份特征提取。
动作识别

身份识别


若有收获,就点个赞吧
0 人点赞
