Pose Recognition with Cascade Transformers
paper:http://arxiv.org/abs/2104.06976 code:https://github.com/mlpc-ucsd/PRTR
原文链接:https://www.yuque.com/jinluzhang/researchblog/prtr
Summary🔖
论文来自CVPR2021,是第一篇发表的基于transformer结构的human pose estimation文章。正好最近我也在做这方面的任务,记录一下。
Motivation👓
针对2D Pose Estimation中存在的难点(姿态/形状变化大、人体自遮挡、外观变化大、背景噪声等方面),
这篇文章作者针对2D Pose Estimation提出了基于cascade transformer结构的人体姿态估计网络。该网络属于top-down regression-based method。
作者在introduction部分先介绍了top-down和bottom-up的方法;随后重点介绍了regression-based和heatmap-based的方法,并解释为什么使用前者——基于回归的方法精度不如基于热图的方法,但是可以端到端,且可与其他下游任务更好的结合,作者也希望去除一些不必要的冗余的设计和后处理**,网络直接得到坐标输出(For general-purpose regression methods, we aim at removing unnecessary designs by making the training objective and target output direct and transparent)。
作者所说的贡献:
- Propose a regression-based human pose recognition method by building cascade Transformers
- Two types of cascade Transformers have been developed,一种是端到端的,把人体检测的transformer和关键点检测的transformer联合训练,使用了spatial Transformer network (STN) ;另一种是two-stage的。
- 对关键点检测的过程进行可视化
Related Work📚
相关工作有哪些?分为哪些类别?最相似的需要对比的工作?
文章把相关工作分为了Heatmap-based,Regression-based和Transformers and self-attention三大块
基于热图的方法,优点在于像素级细粒度的检测,但是每个关键点的热图生成使这个过程和人体的整体估计脱离,聚类和分组过程使该方法不能端到端。
基于回归的方法,虽然更易集成端到端,但是递归的过程会损失大量候选位置,这会造成和基于热图方法的性能差距。
作者follow基于回归的方法,基于transformer构造了step-by-step的回归网络,在作者看来,逐步回归或许可以避免精度损失?Method💡
Overview
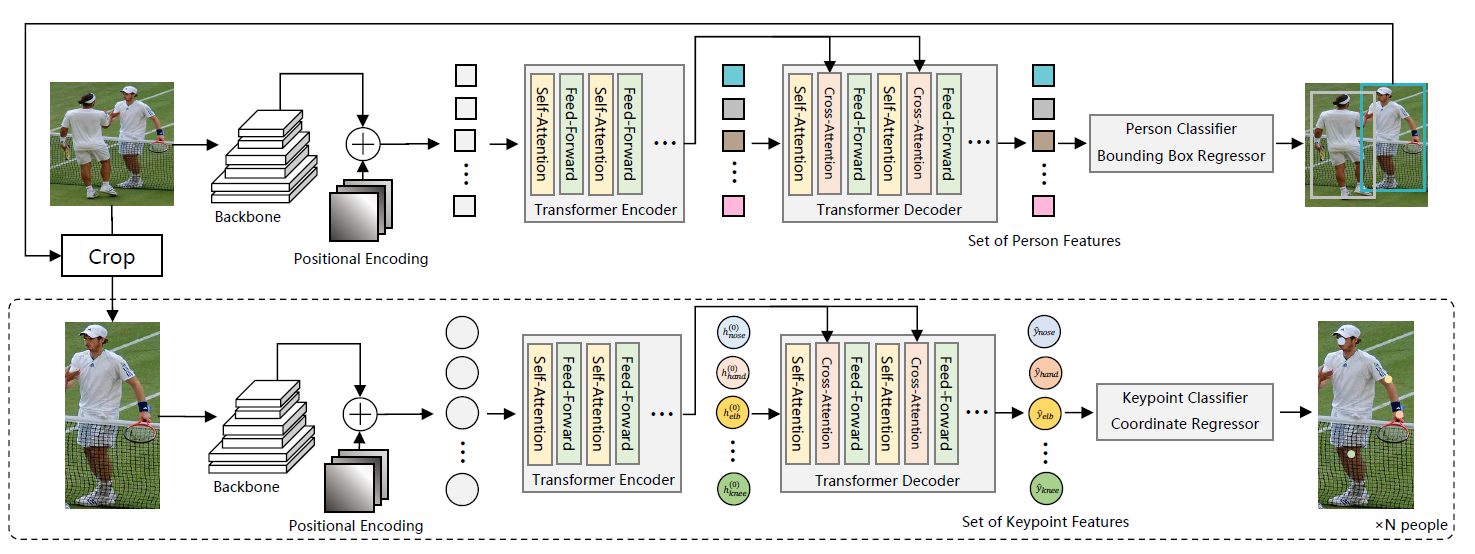
two-stage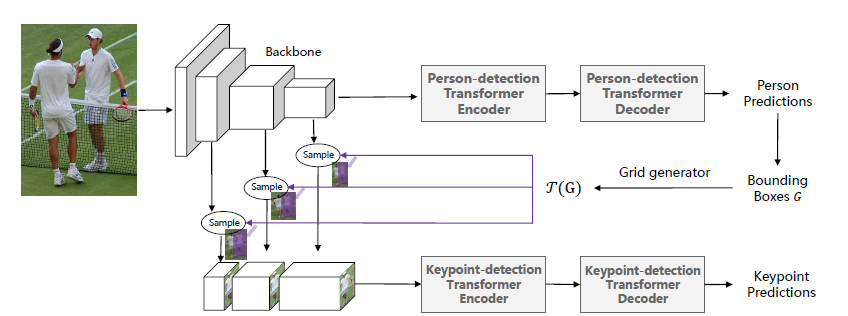
end-to-end
作者提出了两种结构,这两种结构都是由人体检测和关键点检测这两部分transformer构成的。
Person Detection Transformer
基于DETR的检测方法,用一个CNN Backbone提取RGB feature,然后通过encoder编码上下文关系,decoder预测bbox,得到bbox后,对original image进行crop。
Keypoint Detection Transformer
得到crop后的image和对应的positional encoding之后,送进encoder中,得到一堆queries,注意这些encoder得到的queries的数量是多于关键点数量的,因此通过匈牙利算法匹配后,再送到decoder中,得到最终的坐标预测。
关于匈牙利算法:https://zhuanlan.zhihu.com/p/96229700
关于为什么检测出来的queries数量会大于prediction的数量:
个人感觉因为Keypoint Detection Transformer是基于DETR的结构,而DETR会推断出一个固定的N个预测的集合(N远大于一张图片中的目标数量)。然后计算预测结果和ground truth objects的最佳二分匹配的loss对这个二分匹配进行优化,然后针对有物体的预测计算其边框位置损失。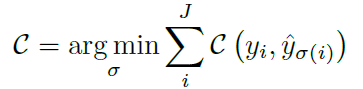
文中的二分匹配的Loss公式
在训练阶段,C函数(cost function)的计算方式: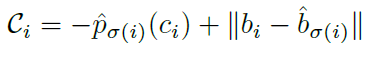
左侧P(ci)是i关键点匹配到类别ci的置信度,右半边是ground truth和prediction的坐标差值
在推理阶段,C函数(cost function)的计算方式: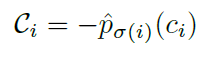
由于inference没有GT,所以只用类别置信度表示。
Evaluation🧪
实验结果,作者如何评估自己的方法,实验的setup是什么样的,有没有问题或者可以借鉴的地方。
Dataset
- COCO 2017
- MPII
Metrics
Object Keypoint Similarity (OKS) for COCO
and Percentage of Correct Keypoints (PCK) for MPIISetup
首先finetune了人体检测transformer(DETR weight),然后对Two-stage variant和End-to-end variant都进行实验。
Result
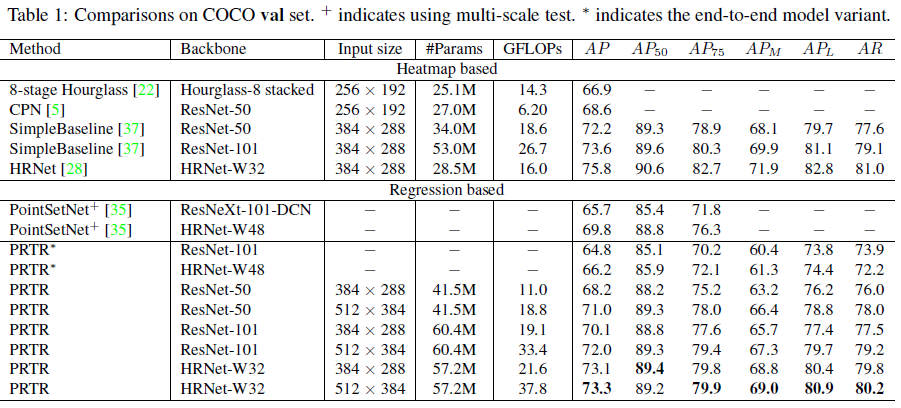
Comparisons on COCO val set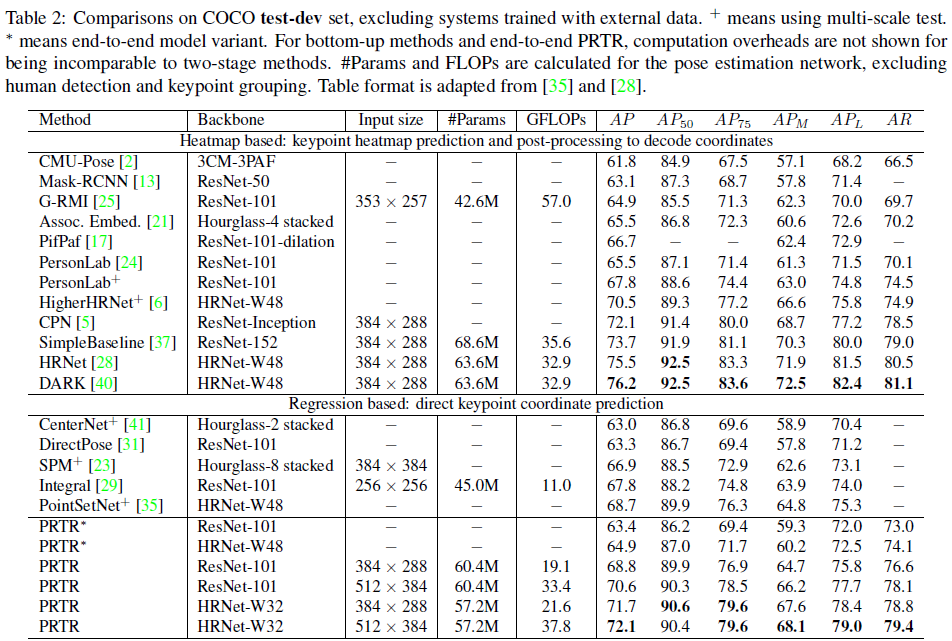
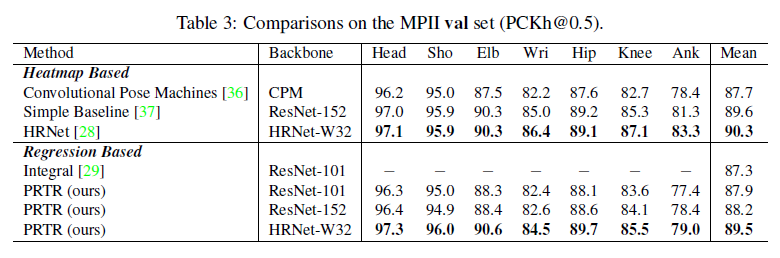
从结果来看,精度虽然在regression-based方法上达到了SOTA,但是仍无法比2019的HRNet为代表的heatmap-based方法更进一步。
Conclusion⭐️
Contribution
- presented Pose Regression TRansformer(PRTR), a new design for regression-based multiperson pose recognition method based on the Transformerstructure.
- 两种选择方案,端到端和two-stage
-
Rethink❓
作者最后也说未来希望有更强的骨干网络,但是是否CNN提取特征这个环节是更好的?或许可以替换成ViT之类?
- 感觉创新性挺足,但并没有给我焕然一新的感觉,keypoint detection transformer的结构和DETR类似是否就是好的结构?是不是还有更好的网络结构,更适合pose的任务?
Track📚
- End-to-end object detection with transformers(DETR)ECCV 2020
- Cascaded pose regression(step-by-step regression)
- Locality-constrained spatial transformer network for video crowd counting.(STN)
ref:

若有收获,就点个赞吧
0 人点赞
