Self-Supervised Learning of 3D Human Pose using Multi-view Geometry paper code
Summary
本文提出一种多视角的、不需要任何相机参数和额外监督的自监督方法,进行single image的3D姿态估计——EpipolarPose,该方法在weekly/self supervised中达到SOTA。
在训练时,对于多视角图片使用2Dpose estimator和epipolar geometry(对极几何)获得3D pose,随后将其用于训练3D pose estimator,作者还在文中测试了epipolar geometry(对极几何)获得3D pose与Ground Truth的对比以说明其作为监督信息的合理性。
此外,作者提出了3D pose estimation新的衡量标准:Pose Structure Score (PSS)。
Contributions Our contributions are as follows:
- We present EpipolarPose, a method that can predict 3D human pose from a single-image. For training, EpipolarPose does not require any 3D supervision nor camera extrinsics. It creates its own 3D supervision by utilizing epipolar geometry and 2D ground-truth poses.
- We set the new state-of-the-art among weakly/selfsupervised methods for 3D human pose estimation.
- We present Pose Structure Score (PSS), a new performance measure for 3D human pose estimation to better capture structural errors.
Motivation
自监督的自然环境中的3D人体姿势估计。在pose estimation中由于没有足够的标签进行监督学习,所以自监督或弱监督学习方法在该问题中很有研究价值。
Method
Overview
需要注意的是:论文中提出的方法在推理时使用的是single image to 3D Pose;而在训练时使用的是multi-view。
图一中,左侧的分支是需要训练的网络,这部分对应图二中的上分支,右侧分支对应图二的下分支,作用是通过Epipolar Geometry得到自监督的3D Pose
Our method, EpipolarPose, is a single-view method during inference; and a multi-view, self-supervised method during training.
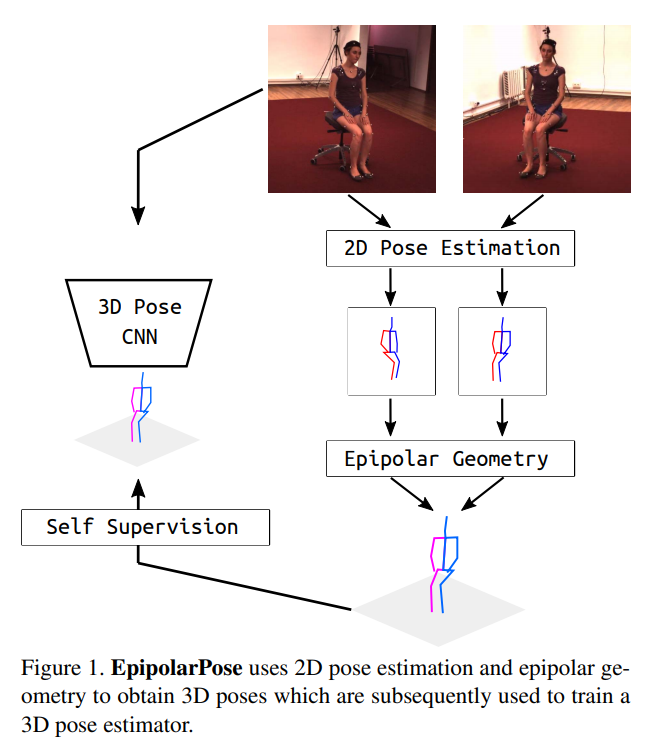
图一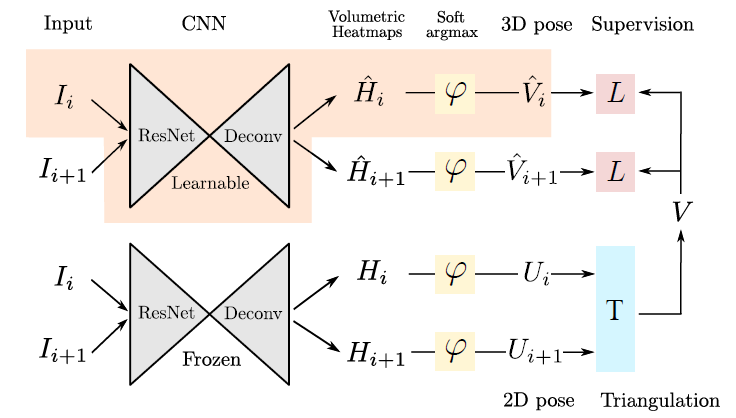
图二
它的训练过程如下:
有n个相机(n>=2)同时对场景中的某个人拍照,相机能同时产生 张图片,下标代表相机的编号。
张图片,下标代表相机的编号。
论文中以n=2为例,上面是可学习参数分支网络,下面分支的参数是冻结的,都是先用ResNet 做backbone,再接上一个反卷积网络。使用下面产生的2D Pose( )进行triangulation产生的3D Pose(
)进行triangulation产生的3D Pose( )对上面的分支进行自监督学习。
)对上面的分支进行自监督学习。
该方法有几个关键点:分别是triangulation过程、Inference过程、Refinement Unit和PSS。
Triangulation
关于这部分涉及到相机成像空间和刚体变换等知识,特意去查了一下,详见相机成像过程基础
文中在进行多视角获取深度时,还使用了对极几何的知识对极几何(Epipolar Geometry),主要解释对极几何原理和基本(fundamental )矩阵、必要(essential)矩阵。
相机的内外参数分别为: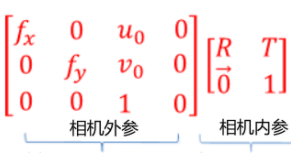
三维世界坐标系到二维像素坐标系的映射过程为: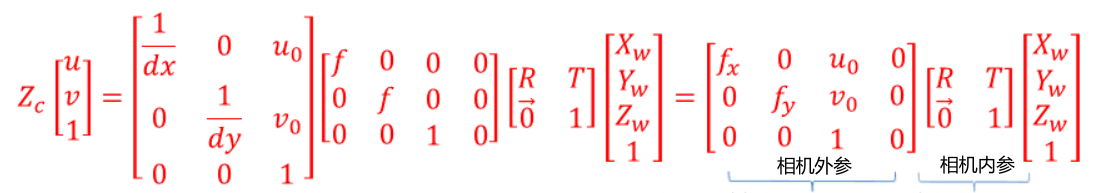
公式1
相机外参可获取时
文中给出2D Pose到3D Pose的映射关系为: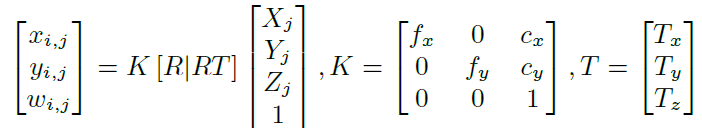
公式2
可以看出上面两个公式是由不同的,这个给我当时造成了比较大的疑惑。这是因为论文中使用的是多视角相机模型中三维到二维的变换方法,因此公式1是公式2中单视角的映射公式。
相机外参不可取时
在动态捕捉的环境中,相机的外参矩阵(R, T)通常是不可知的。因此本质矩阵E和基础矩阵F我们均无法直接得到。
我们可以用人体关节作为校准目标。假设第一个相机位于坐标系的中心,即第一个相机的外参R恒定,使用 RANSAC algorithm算法(Link),可以得出基本矩阵fundamental matrix:
然后根据 ,将得到的E矩阵进行奇异值分解SVD(奇异值分解),得到4个可能的R的解,最后进行cheirality check(Link)筛选出一个最佳值。
,将得到的E矩阵进行奇异值分解SVD(奇异值分解),得到4个可能的R的解,最后进行cheirality check(Link)筛选出一个最佳值。
最后,使用对极几何获得与2D图片同步的3D pose。即对于在  不存在遮挡的所有关节点,使用 polynomial triangulation triangulate a 3D point。
不存在遮挡的所有关节点,使用 polynomial triangulation triangulate a 3D point。
Loss of 3D Branch
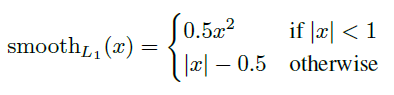
Inference&Refinement
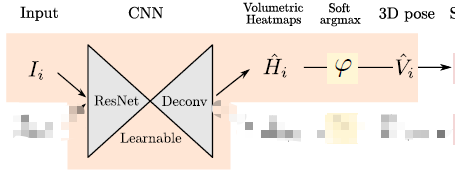
橙色部分即为推理部分,也就是训练结束后使用论文方法的流程。
对于Refinement部分来说,Refinement Unit(RU)是为了进一步细化,提高pose的精确度而设立的,这部分有2个计算块,每个计算块都有一定的线性层,然后是Batch Normalization[15]、Leaky ReLU[21]激活层和Dropout层,将不理想的三维输入(文中成为噪声输入)映射到更可靠的三维位形预测。为了方便各层之间的信息流动,还添加了残差连接和中间监督。
PSS
Pose Structure Score的提出,是因为作者认为传统的距离评价指标(MPJPE和PCK)将每个关节点独立地看待,无法整体评估姿态的结构准确性,从下图中看出,位于中间的人为调整姿态的和右边的姿态看起来完全不一样,但是他们用MPJPE上具有类似的分数。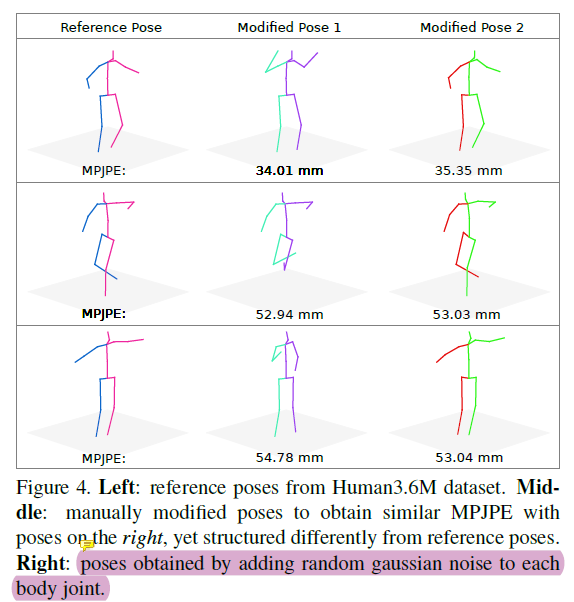
因此,作者设计了一个PSS指标用来衡量结构相似性: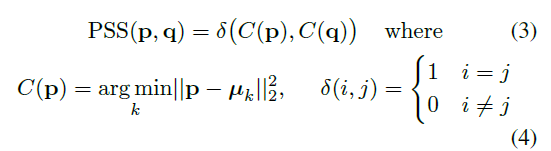
计算PSS需要Ground Truth的Pose分布作为参考,对于该分布假设一个ground truth 集合有n个poses  ,将每个向量进行标准化
,将每个向量进行标准化  。然后,用k-means聚类。最后计算预测的姿态p和真值q之间的PSS。
。然后,用k-means聚类。最后计算预测的姿态p和真值q之间的PSS。
Evaluation
Setup
作者采用ECCV2018的IntegralPose为代码框架,并且采用ResNet-50为backbone。输入图像和输出heatmap的尺寸大小分别为: 。J是关键点数量J是关键点数量J是关键点数量。
。J是关键点数量J是关键点数量J是关键点数量。
对于两个相机,batch-size为32,每个图像对。网络训练140,优化器采用Adam,初始学习率为0.001,在第90步和120步的时候调整学习率。采用随机旋转和尺度变化来做数据增强。
- 数据库: Human 3.6M, MPI-INF-3DHP
-
Result
在H36M上和其他SOTA比较的结果:
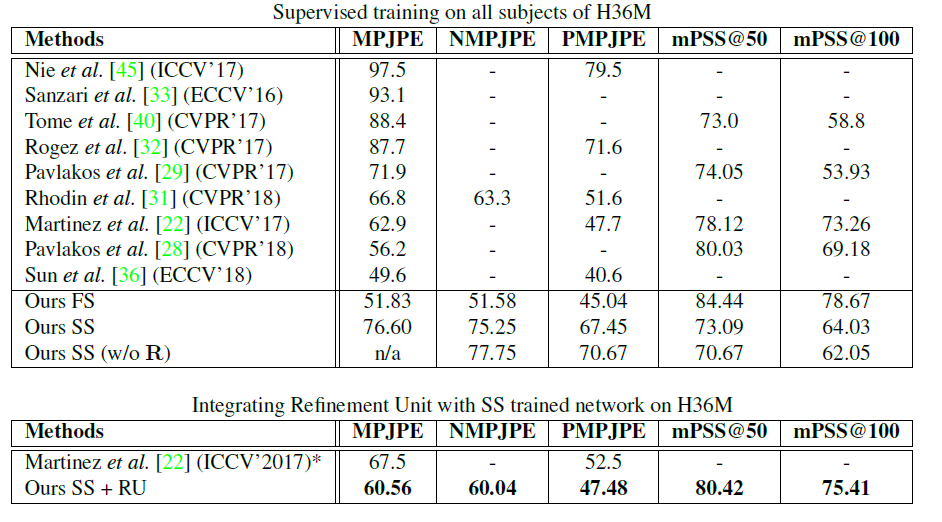
文献中一些关于weakly or self supervised方法在Human 3.6M上的结果: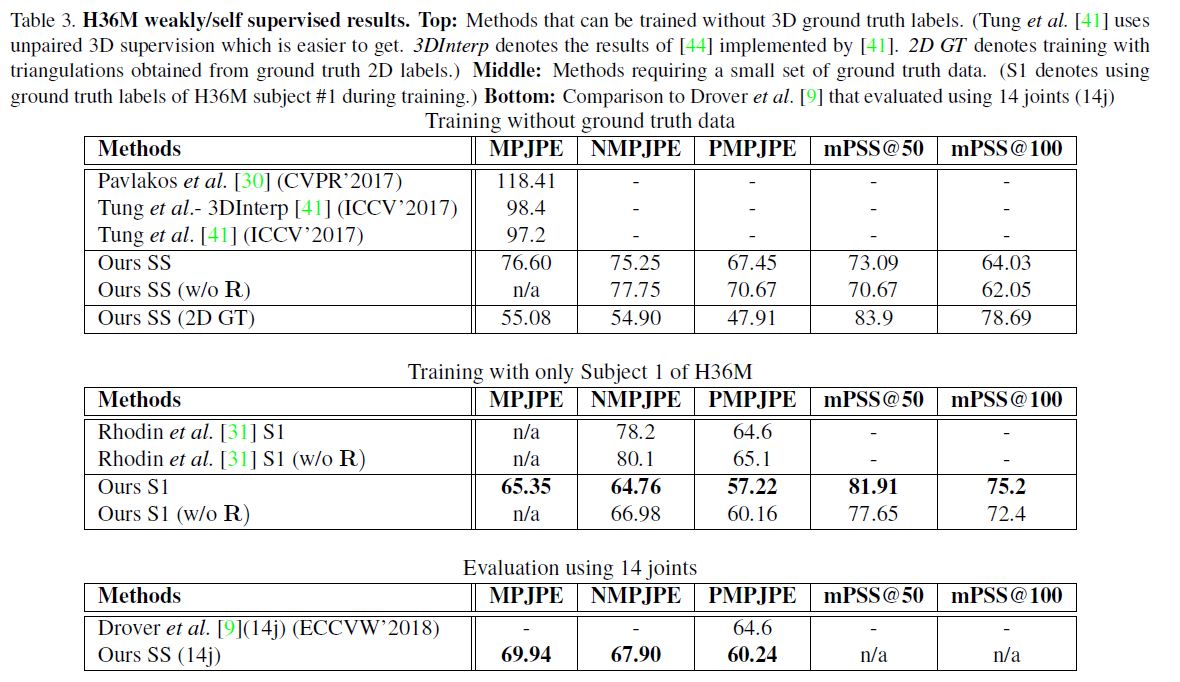
在3DHP上的结果: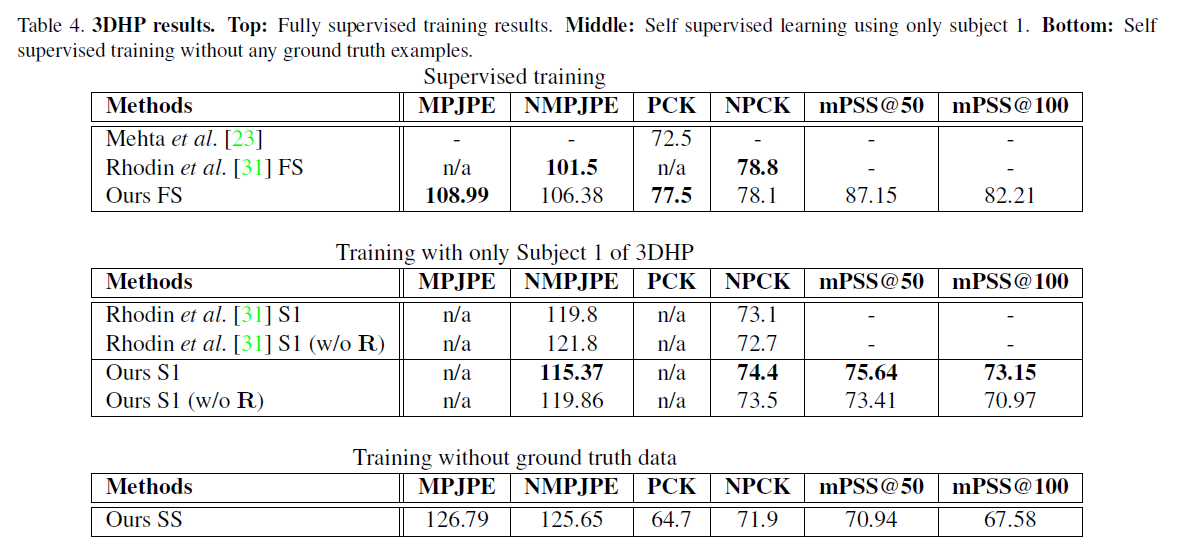
Conclusion
Contribution
作者提出了一种多视角对极几何的2D image to 3D Pose的自监督估计方法,该方法训练后可以进行single image to 3D pose的推理;
证明即使没有任何三维真值数据和相机的外部参数,多视图图像也可以获得自我监督
Weak
论文方法的精度与SOTA的监督方法还是有较大差距,原因可能在于相机外参未知时使用的估计方法造成了深度信息估计准确度的损失;
- 虽然使用了自监督,但是训练的branch仍然是直接回归的3D Pose CNN,这会不会造成训练难度的提升以及CNN对于3D Pose的理解问题?
- 在文中获取深度信息使用对极几何,并将获取的深度信息作为自监督信息训练网络从单张图片中得到3D Pose的能力,或许不需要多视图数据集也可以单目2D Image获取3D Pose作为监督信息(单应矩阵)?不过也许这种监督信息应该并不如对极几何的准确准确
Track
- 对极几何、基本矩阵、必要矩阵
- Integral human pose regression
- 2D推测3D的其他方法,若推测方法可以进一步提高准确度,或者使用部分弱监督信息,比监督方法更有研究价值
部分论文:
- Georgios Pavlakos, Xiaowei Zhou, and Kostas Daniilidis.Ordinal depth supervision for 3D human pose estimation. In IEEE Conference on Computer Vision and Pattern Recognition,2018. 2, 7
- Georgios Pavlakos, Xiaowei Zhou, Konstantinos G Derpanis,and Kostas Daniilidis. Harvesting multiple views form arker-less 3d human pose annotations. In IEEE Conference on Computer Vision and Pattern Recognition, 2017. 1,2, 6, 7, 8
- Helge Rhodin, J¨org Sp¨orri, Isinsu Katircioglu, Victor Constantin,Fr´ed´eric Meyer, Erich M¨uller, Mathieu Salzmann,and Pascal Fua. Learning monocular 3d human pose estimationfrom multi-view images. In IEEE Conference on Computer Vision and Pattern Recognition, 2018. 1, 2, 4, 6, 7,8
- Hsiao-Yu Fish Tung, Adam W Harley, William Seto, andKaterina Fragkiadaki. Adversarial inverse graphics networks: Learning 2d-to-3d lifting and image-to-image translationfrom unpaired supervision. In International Conferenceon Computer Vision, 2017. 1, 2, 7, 8
Dylan Drover, Rohith MV, Ching-Hang Chen, AmitAgrawal, Ambrish Tyagi, and Cong Phuoc Huynh. Can 3dpose be learned from 2d projections alone? European Conferenceon Computer Vision Workshops, 2018. 1, 2, 3, 8
(本文作者提到的另一篇完全自监督的论文)ref:
- https://blog.csdn.net/qq_38682032/article/details/88600860
- https://zhuanlan.zhihu.com/p/98363011

若有收获,就点个赞吧
0 人点赞
