老是忘了关冰箱 - 利用splunk构建SOC-Splunk安装及数据导入
免喷符
SOC部门小菜鸟一枚,此乃自闭学安全的笔记记录,行文潦草,随性笔记。
学习路线及安装
架构图
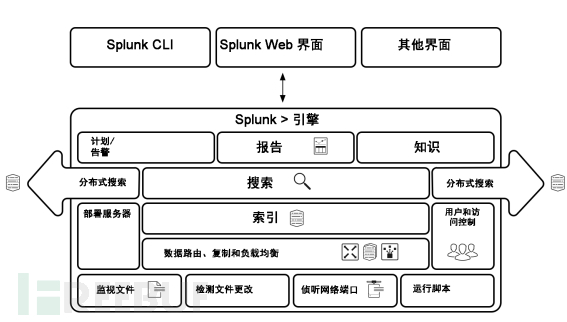
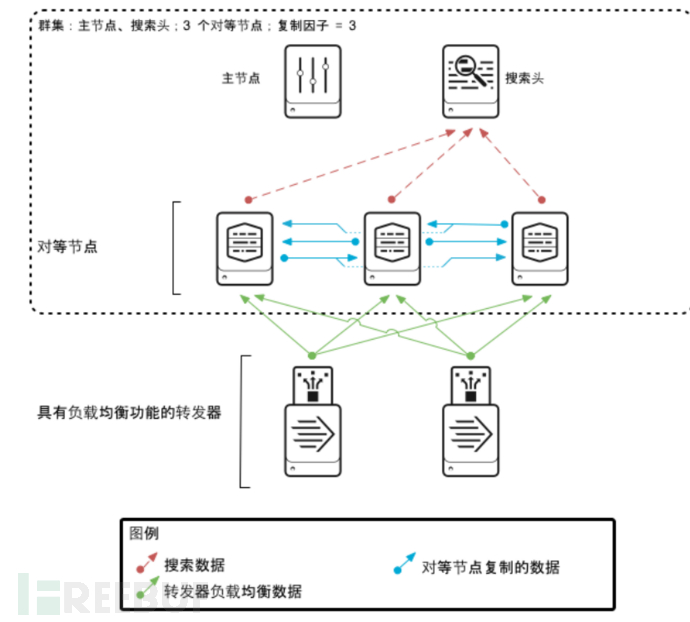
splunk核心架构图
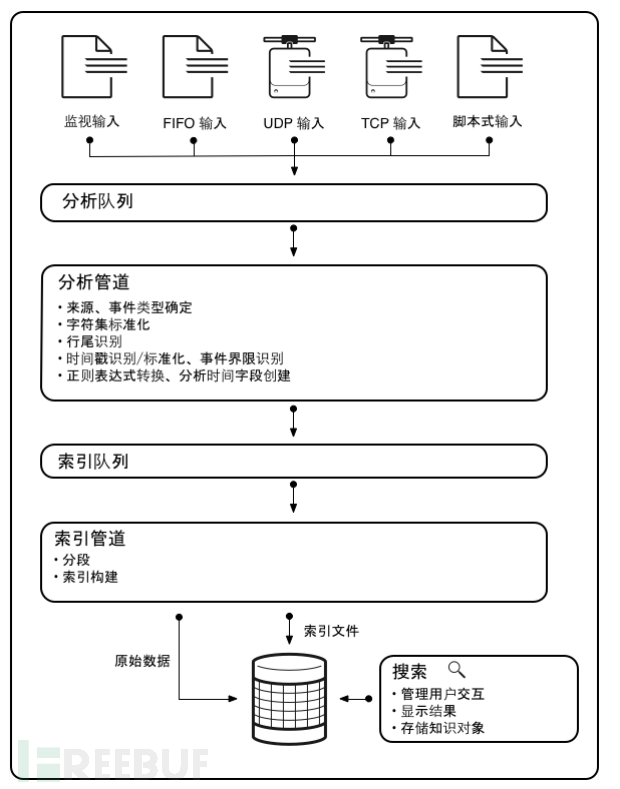
splunk数据流处理图
官方文档阅读路线
从图里可以看到,splunk转发器从监视文件、端口监听、脚本运行等方式可获取数据并为其建立索引,把数据转换为事件形式的可搜索知识。数据管道显示建立索引期间操作数据的进程。这些进程组成了事件处理。将数据处理成事件后,您可以把事件与知识对象关联起来,以增加其实用性。
数据管道包括以下几段:
- 输入
- 分析
- 索引
- 搜索
在数据导入层,Splunk Enterprise 使用来自各种输入的数据。接着,在索引层,Splunk Enterprise 会对数据进行检查、分析及转换。事件处理将出现在两个阶段:分析和新建索引。所有数据以大数据块的形式通过分析管道进入。分析期间,Splunk 平台会将这些数据块分为若干事件。然后它将这些事件传递到执行最终处理的索引管道。
然后,Splunk Enterprise 会获取分析后的事件并将其写入磁盘上的索引中。在索引管道将所有事件分段,然后基于段执行搜索。构建索引数据结构。将原始数据和索引文件写入磁盘,其中将执行后索引压缩。最后,搜索管理层可管理用户如何访问、查看及使用索引数据的所有方面。
数据路由、部署服务器、用户权限控制、分布式搜索都是splunk系统管理方面的运维及扩容的知识,先按下不表
从主要功能开始:
数据导入
https://docs.splunk.com/images/8/87/Splunk-8.2.0-Data_zh-CN.pdf
通用转发器
https://docs.splunk.com/images/9/9c/Forwarder-8.1.0-Forwarder_zh-CN.pdf
https://docs.splunk.com/images/d/db/Splunk-8.2.0-Indexer_zh-CN.pdf
搜索
简易教程
https://docs.splunk.com/images/3/3a/Splunk-8.2.0-SearchTutorial_zh-CN.pdf
高级教程
https://docs.splunk.com/images/a/ac/Splunk-8.2.0-Search_zh-CN.pdf
各种命令参考
https://docs.splunk.com/images/0/04/Splunk-8.2.0-SearchReference_zh-CN.pdf
告警
https://docs.splunk.com/images/b/b3/Splunk-8.2.0-Alert_zh-CN.pdf
报表
https://docs.splunk.com/images/4/4d/Splunk-8.2.0-Report_zh-CN.pdf
知识管理(难点,字段范式化等)
https://docs.splunk.com/images/8/88/Splunk-8.2.0-Knowledge_zh-CN.pdf
splunk安装
splunk支持安装在windows、linux、macOS、docker。
下面,以linux为例。linux安装步骤
下载了tgz包解压到/opt下:
tar -xzvf name /opt
添加环境变量到/etc/profile:
SPLUNK_HOME=/opt/splunk PATH=$PATH:$SPLUNK_HOME/bin export PATH SPLUNK_HOME
刷新环境变量:
source /etc/profile
将splunk属主属组划为splunk用户:
chown -R splunk:splunk $SPLUNK_HOME
使用root用户为splunk用户设置开机启动脚本: ```shell
!/bin/sh
#
/etc/init.d/splunk
init script for Splunk.
generated by ‘splunk enable boot-start’.
#
chkconfig: 2345 90 60
description: Splunk indexer service
# RETVAL=0 USER=splunk
splunk_start() { echo Starting Splunk… su - ${USER} -c ‘“$SPLUNK_HOME/bin/splunk” start —no-prompt —answer-yes’
“/opt/splunk/bin/splunk” start —no-prompt —answer-yes
RETVAL=$? [ $RETVAL -eq 0 ] && touch /var/lock/subsys/splunk } splunk_stop() { echo Stopping Splunk… su - ${USER} -c ‘“$SPLUNK_HOME/bin/splunk” stop’ RETVAL=$? [ $RETVAL -eq 0 ] && rm -f /var/lock/subsys/splunk } splunk_restart() { echo Restarting Splunk… su - ${USER} -c ‘“$SPLUNK_HOME/bin/splunk” restart’ RETVAL=$? [ $RETVAL -eq 0 ] && touch /var/lock/subsys/splunk } splunk_status() { echo Splunk status: su - ${USER} -c ‘“$SPLUNK_HOME/bin/splunk” status’ RETVAL=$? } case “$1” in start) splunk_start ;; stop) splunk_stop ;; restart) splunk_restart ;; status) splunk_status ;; *) echo “Usage: $0 {start|stop|restart|status}” exit 1 ;; esac
exit $RETVAL
启动服务并同意授权政策:```shellsplunk start
关闭防火墙:
systemctl stop firewalldsystemctl disable firewalld
文件说明
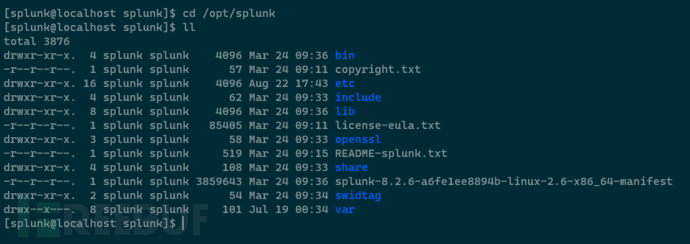
- bin目录:splunk提供的命令集合
- etc目录:非常重要,splunk支持web、cli以及conf文件对服务器进行配置,其中conf文件变更的设置最齐全
- include目录:包含了python程序,执行脚本
- lib目录:splunk的核心库
- var目录:splunk自身一些重要的日志等文档
- openssl:支持ssl
-
关于etc里的配置文件
Splunk Enterprise 所有的配置都存储在etc下的配置文件中。这些文件通过 .conf 扩展名识别,在$SPLUNK_HOME/etc/system/default/ (默认配置实现,不要修改)目录中。配置设置类型包括:
系统设置
- 验证和授权信息
- 索引相关设置
- 部署和群集配置
- 知识对象和已保存的搜索
在 Splunk Web 中更改配置之后,此更改会写入到该设置的配置文件副本中。Splunk 软件会新建此配置文件的副本(如果不存在)、将更改写入到此副本,并将其添加到 $SPLUNK_HOME/etc/… 下的某个目录中,常見目录是$SPLUNK_HOME/etc/system/local/:
Splunk Enterprise 安装可能有多个版本的配置文件,一般每个app下都有同名的配置文件,这些配置文件位于多个目录中。例如,您可能在每个 default、local和 app 目录中拥有相同的配置文件,但设置不同。Splunk Enterprise 使用分层方案和规则来评估重叠配置并确定其优先级:
-
服务配置
Splunk Enterprise 在安装时配置几个端口:
HTTP/HTTPS web管理端口:该端口为 Splunk Web 提供套接字。默认端口为 8000。
- Appserver 端口:默认为 8065。
- 集群管理端口:该端口用于与 splunkd 守护程序通信。Splunk Web 在此端口上与 splunkd 通信。此外,命令行界面和任何来自其他服务器的分布式连接也均采用此端口。默认端口为 8089。
- KV 存储端口:默认为 8191。
-
许可证
默认情况安装使用,会有一个60天的试用授权,每天限500M的数据上传,其实可以无限申请开发者授权,半年,每天10G使用量上限。
有限地访问 Splunk Enterprise 功能。
仅适用于独立的单实例使用安装
不能与其他许可证堆叠。
有效期为 6 个月。在许可证到期前一周提交延长许可证有效期的请求
允许您每天索引 50 GB(开发10G) 的数据。如果超过该限制,您将收到许可证警告
如果有多个许可证警告,则开发/测试许可证会阻止搜索操作
在 Splunk Web 中会有一个“开发/测试”标记
许可证违规:
数据导入
简介
Splunk 平台可以索引任何类型的数据。如任意的 IT 流、计算机和历史数据,例如 Microsoft Windows 事件日志、Web 服务器日志、实时应用程序日志、网络源、指标、变更监视、消息队列、归档文件等。
可以直接将数据导入实例,或者监视splunk本机上的任何文件目录,也可以通过转发器将数据导入
Splunk 应用和加载项可以扩展功能,并简化数据导入 Splunk 平台部署的过程文件和目录
在您想要监视文件和目录的每台计算机上安装通用转发器,文件和目录监视器输入处理器从文件和目录中获取数据,并将该数据发送到重型转发器,然后重型转发器(重型转发器本身就是个完整splunk实例,只是大规模部署时,用来做中转)将数据发送到 Splunk(或者直接发给splunk) 。要监视文件和目录
网络事件
使用重型或通用转发器(一个没有界面的splunk实例,阉割很多功能,只是用来收发数据)来收集网络数据,然后将该数据发送到 Splunk
windows数据来源
在您的通用转发器上安装 Splunk Add-on for Windows。在这种情况下,您可以使用部署服务器将 Splunk Add-on for Windows 传送到您要监视的 Windows 计算机。该加载项将收集数据并将其发送到Splunk。(windows有点特殊,需要安装特定的插件才能收集他的数据)
Windows 事件日志数据
- Windows 注册表数据
- Windows Management Instrumentation (WMI) 数据
- Active Directory 数据
-
HTTP事件收集器
在 Splunk中,您可以使用 HTTP 事件收集器直接从有 HTTP 或 HTTPS 协议的数据来源获取数据,只需要在发送端设置好服务端的接受端口和token即可
指标
您还可以从技术基础设施、安全系统和业务应用程序中获取指标数据,比如各种硬件使用率
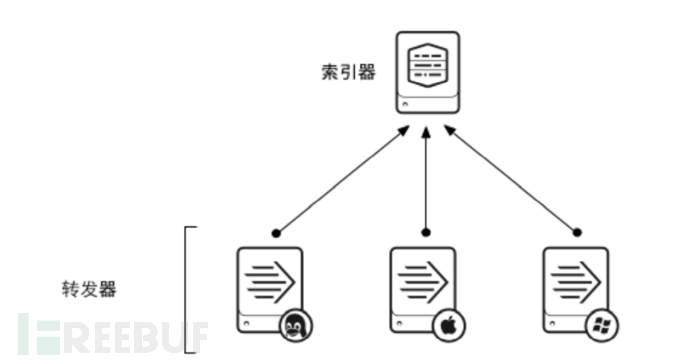
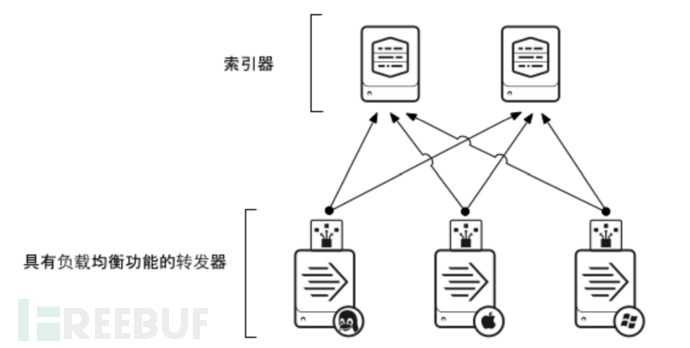
转发器
单索引器
索引器集群
功能
获取数据并将数据发送至一个索引器。通用转发器需要的资源最少,而且对性能影响很小,因此通常驻留在生成数据的计算机上。
如果您有很多 Apache Web 服务器将生成数据,并且您希望集中搜索这些数据,您可以在 Apache 主机上设置转发器。转发器可以获取 Apache 数据并将其发送至您的 Splunk Enterprise 部署,方便您为数据建立索引;数据会在此过程中合并和存储,成为可供搜索的数据。由于转发器占用的资源空间减少,因此对 Apache 服务器性能的影响微乎其微。执行的操作
标记元数据(数据来源、来源类型和主机)
- 缓冲数据
- 压缩数据
- 使用 SSL 安全性
- 使用任何可用的网络端口
- 本地运行脚本式输入
转发器通常不会为数据建立索引,只会把数据发送至 Splunk Enterprise 实例,由该实例为数据建立索引并提供搜索
分类
轻型转发器
基本被抛弃了。就是splunk完整实例屏蔽一些功能专门仅用于数据转发,消耗大
通用转发器
独立的软件,类似一般意义上的agent,只有CLI配置功能,消耗小,常用,不支持索引,在特定案例(如处理结构化数据文件)中提供最低限度的分析。
重型转发器
就是splunk完整实例,作为转发器,重型转发器能够在本地完全分析数据,然后将分析后的数据转发到接收索引器上执行最终的索引建立
工作流程
- 配置一个splunk enterprise服务器以接收数据
- 在一台主机上安装转发器,一般是安装通用转发器
- 在主机上启用转发并指定索引服务器
- 配置数据输入
-
通用转发器下载地址
https://www.splunk.com/en_us/download/universal-forwarder
通用转发器安装目录
下载解压到某个被采集端服务器的opt下,目录名为splunkforwarder:
bin目录:相关splunk指令
- etc目录:配置文件目录,非常重要,设置获取和转发等一系列功能:
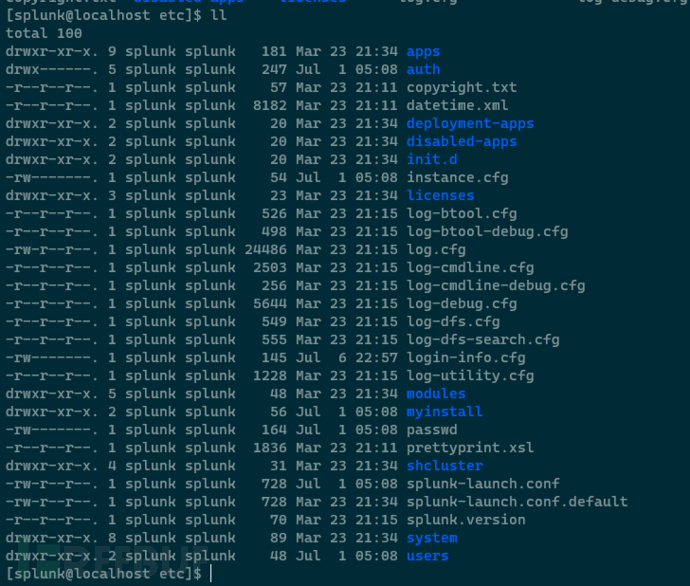
- include目录:没什么东西,对于完整splunk实例而言,这里是有个Python的,通用转发器不需要
- lib目录:核心库
-
etc下的关键配置文件

inputs:用配置文件的形式来指定收集什么数据
- outputs:用配置文件的形式指定转发到哪些索引器
- server:设置连接参数
- deploymentclient:配置连接到部署服务器。
部署服务器主要是统一管理转发器,比如内网有一百台web服务器,都装了通用转发器将自身web日志发到索引器,而web服务器上的通用转发器是不带有ui界面的,可以通过部署服务器进行统一管理通用转发器的运行周期,最常用通过部署服务器下发app给转发器
启动转发器
cd $SPLUNK_HOME/bin./splunk startcd $SPLUNK_HOME/bin./splunk start --accept-license #直接同意协议cd $SPLUNK_HOME/bin./splunk restart #重启#设置splunk用户开机自启动转发器等操作,跟服务器实例一样
使用CLI设置转发器连接到服务器的部署端口接收端口
部署服务器端口默认是8089
splunk set deploy-poll 192.168.114.129:8089

接收端口默认是9997
splunk add forward-server 192.168.114.129:9997
通过CLI配置后,相关配置会写到上面提到的配置文件中,可以看到这里有一个outputs组,如果是集群模式,当然可以把日志扔到多个组,每个组里有多个接收服务器,最下面那行还可以对某个接收服务器进行个性化设置:
对于windows的通用转发器安装是图形引导安装,在安装界面即可填入,不需要CLI设置: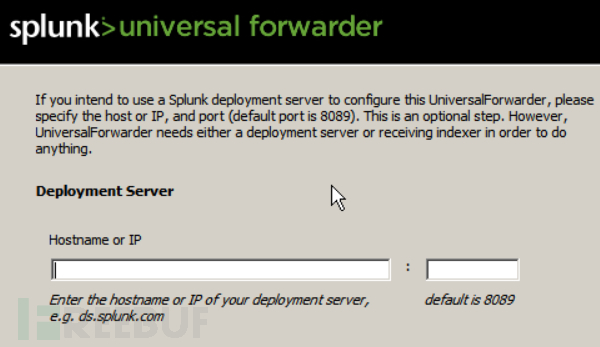
日志导入示例
文件方式上传
从操作客户机上导入数据,上传数据是一次性的: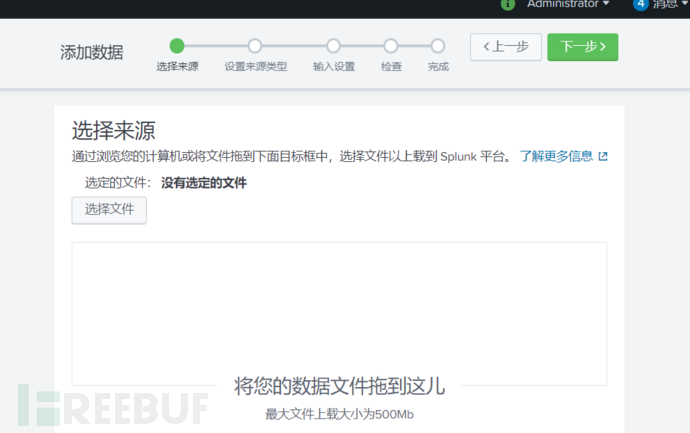
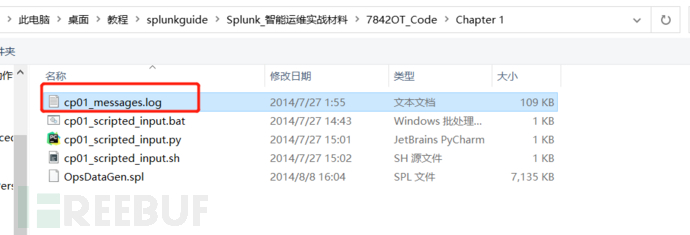
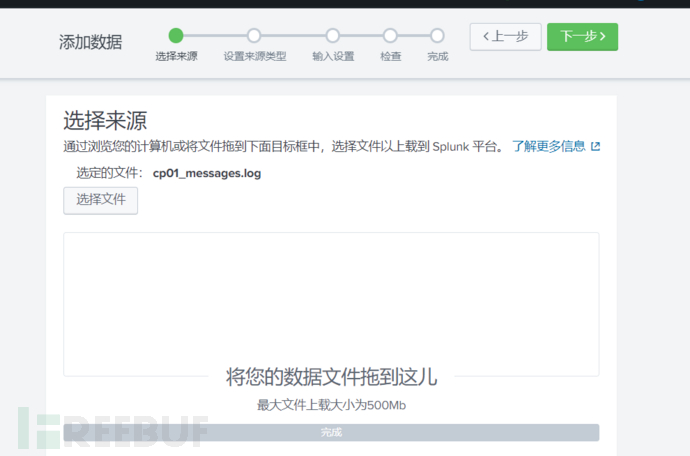
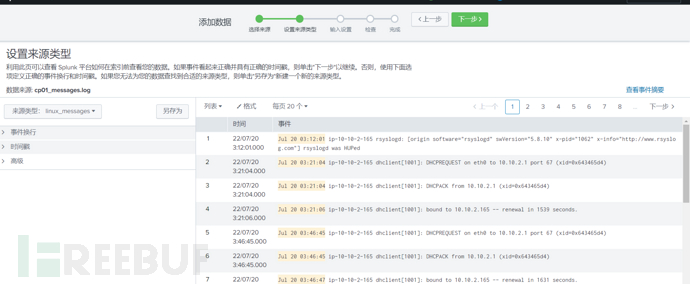
指定正确的来源类型非常重要,这告诉splunk该如何解析和索引这些日志数据,第一篇也提过,这里指定为Linux_messages,对应的是/var/log/messages的日志数据: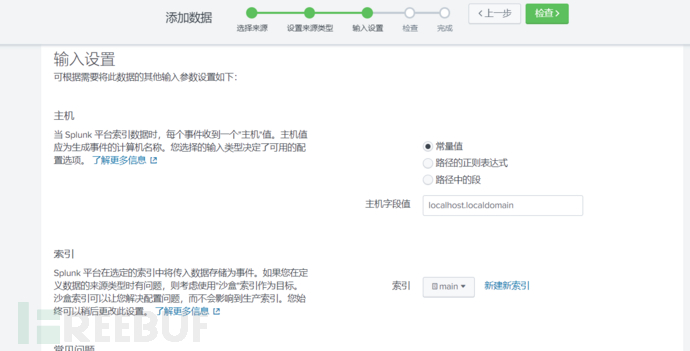
指定正确的日志来源主机,以及存放在哪个索引: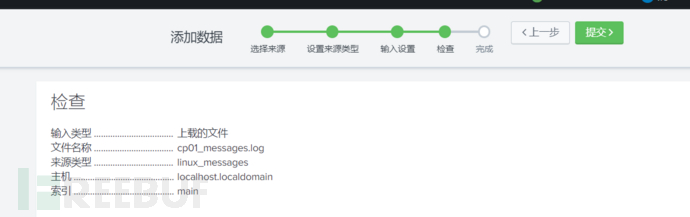
最后检查没问题就提交。
监视某个本地文件,某个端口,还支持http格式
监视数据,是持续性的,持续监控新的日志变化。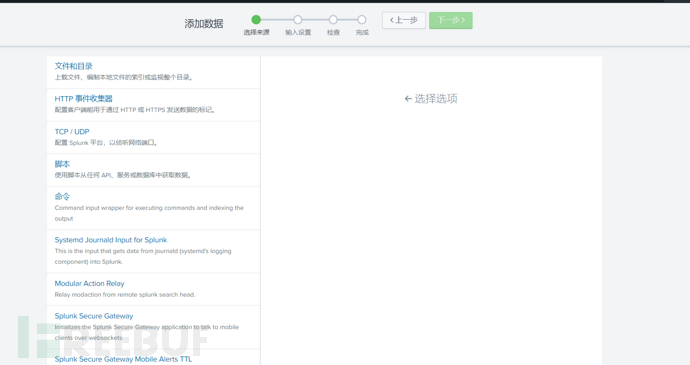
支持监视本地文件或目录,http,tcp/udp,脚本,命令,以及各种应用指令集合: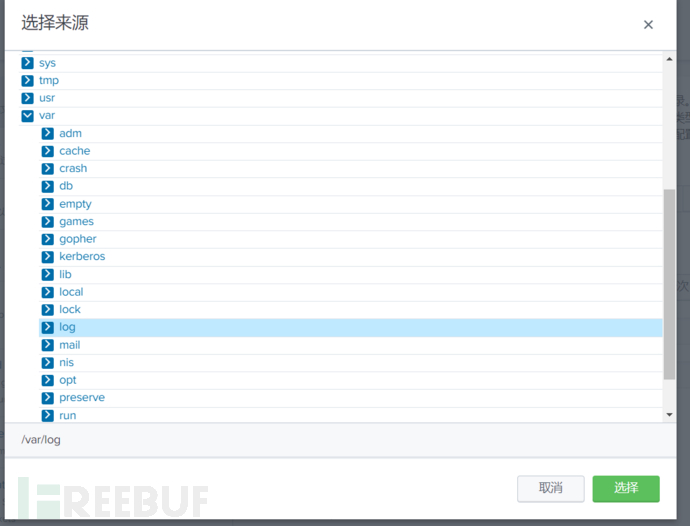
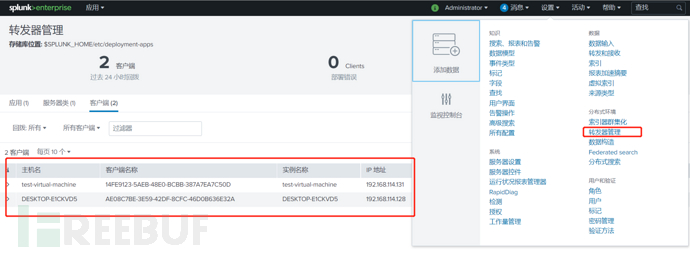
监视通过转发器发来的系统日志数据
查看转发器管理界面,确实看到这两台采集端的转发器已经连接到了服务器:
查看接收端口,9997是开放的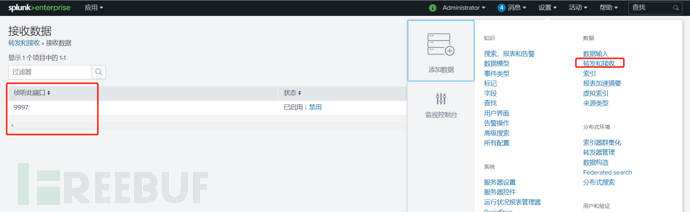
对于Ubuntu主机,我们选择监视模式,监视/var/log/messages文件的日志,通过命令的形式,添加了一个监视器,监视该文件,并指定他的索引为main,日志源类型是linux_messages
splunk add monitor /var/log/messages -index main -sourcetype linux_messages
此命令会将配置写入到/opt/splunkforwarder/etc/apps/search/local/inputs.conf,这是splunk的主app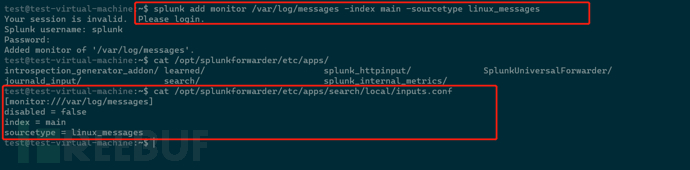
对于windows,在对安装包进行安装时,即可选定要监视的自身系统日志以及性能指标日志。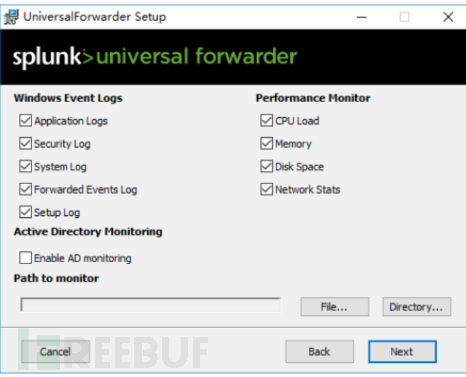
因为通过部署服务器对windows的转发器安装了应用,配置就在app下进行了配置,index指定为windows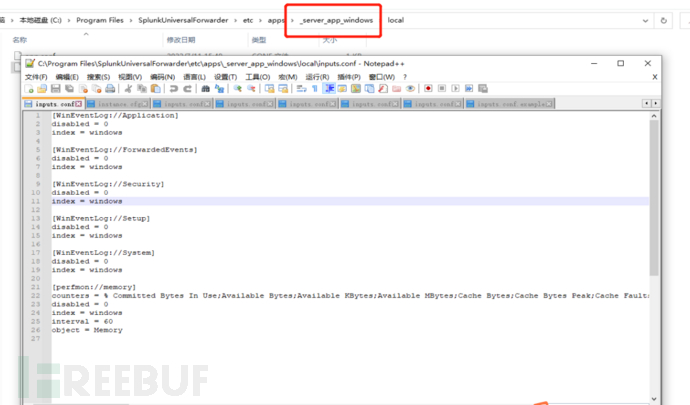
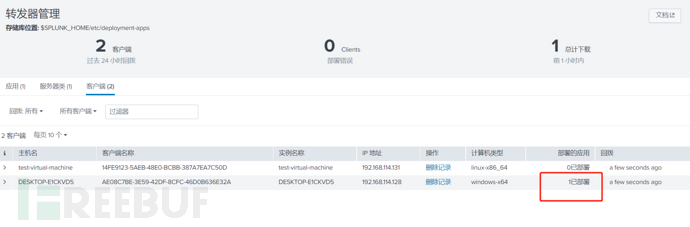
通过搜索可以看到windows的日志事件分类有19种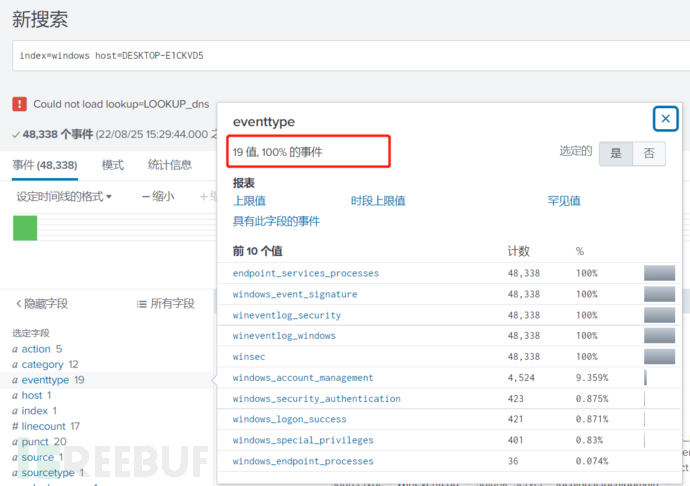
收集网络流日志
在Centos上部署了宝塔,安装web服务,后续将安装各种靶场,利用kali自带的工具产生大量攻击日志,传到splunk以作分析,毕竟安全分析,不了解攻击方式,不了解攻击payload,看日志也是看个寂寞。
网络流日志和上面各种方式导入syslog之类的日志最大的不同是能实时观察交互数据,一览网络全貌。而apache或nginx他们记录的日志是非常简略的。
其实一开始想着干脆找个开源waf似乎更香。只需要设置下代理即可,waf还有规则匹配更友好的展示出攻击告警,然而找了一圈是在没有找到简单好用又能白嫖的(:
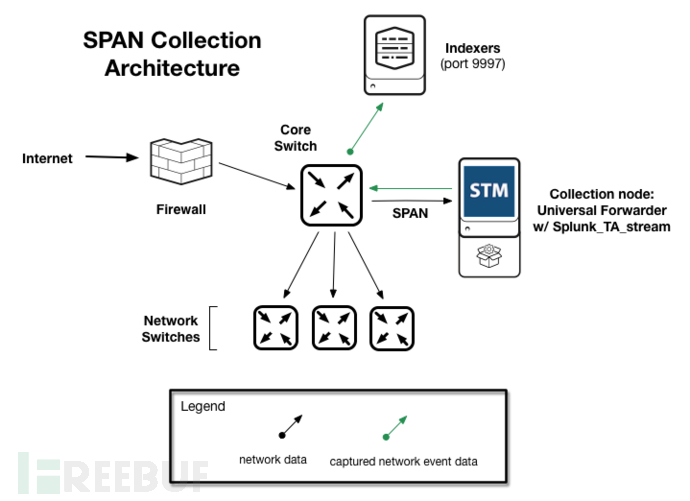
splunk是可以采集netflow的。那我只需要采集kali主机和web服务器之间的交互流量传给splunk实例进行存储索引即可,此时,需要在splunk实例安装stream应用以及在web服务器上安装流转发器软件并配置通信(用两个字形容splunk的组织方式,那就是灵活,很特么灵活)
splunk有三个stream应用插件,如果是单机模式,采集splunk实例本身的网络流日志,就三个都装,这里只需要装stream应用,splunk实例的角色是接收流并处理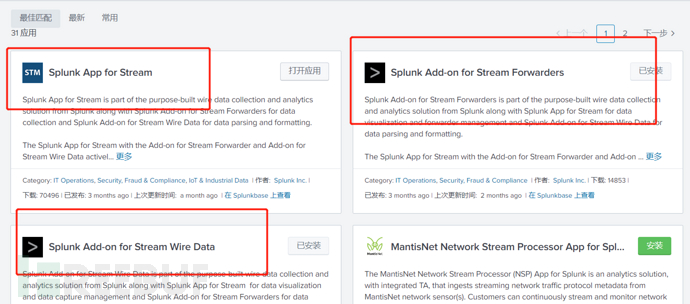

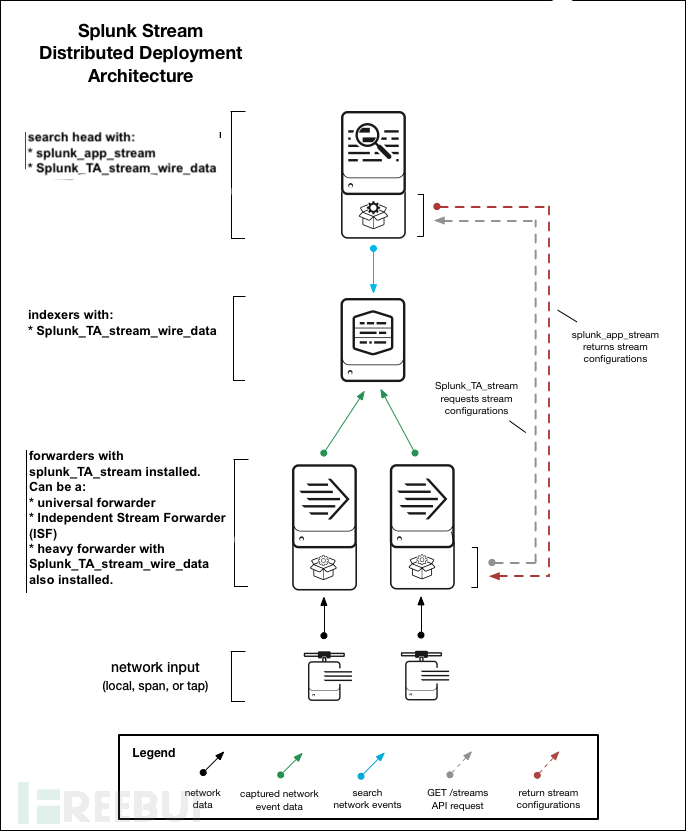
如图:
- splunk app for stream,主要的应用,主要提供了界面管理,提供仪表板
- Splunk Add-on for Stream Forwarders,主要的流采集传送插件,安装到被采集的服务器上
Splunk Add-on for Stream Wire Data,主要是用在搜索头上。提供知识对象。上面提到,splunk的核心功能是导入,索引,存储,搜索,一般分布式都会把搜索功能独立出来给一台服务器,所以叫搜索头。
收集流日志步骤
web服务器IP: 192.168.114.140
- splunk IP: 192.168.114.129
- kali IP: 192.168.114.100
进入splunk实例,从左上角选择应用进入stream应用:
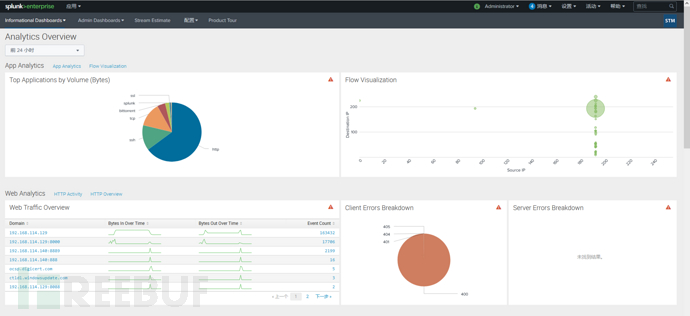
在配置页面点击install stream forwarders,出现一个弹窗,复制相关shell指令到web服务器,安装isf(独立流转发器),可以直接配置下这些主机的主机名互解析,在/etc/hosts下:
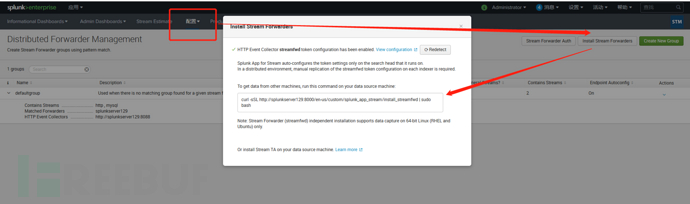
执行命令,安装到web服务器的opt目录下,目录名为streamfwd,流转发器的意思:

在splunk实例上查找主机名称以及http令牌(因为这些流日志是以http的方式传递给splunk的,对于http协议传输日志,则需要一个token,待会需要在web服务器上进行配置):
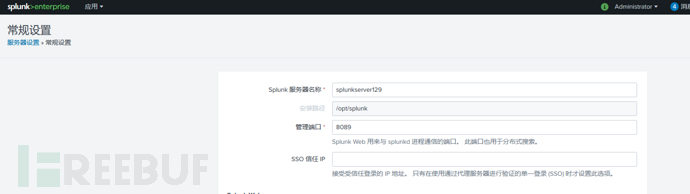

配置web服务器的/opt/streamfwd/local/inputs.conf,设定自身主机名和splunk 应用地址:

配置抓包地址,http采集器的令牌,indexer地址(接收地址)/opt/streamfwd/local/streamfwd.conf:
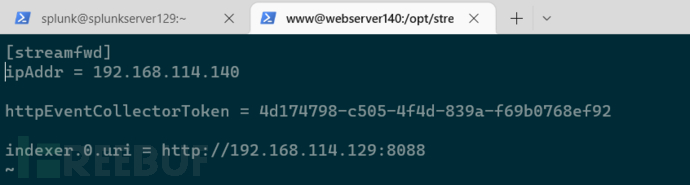
service streamfwd restart 重启streamfwd服务,去splunk实例可以看到已经识别到了这台流转发器,有个error,不管他,还可以看到默认收了54种stream,是属于转发器的默认组: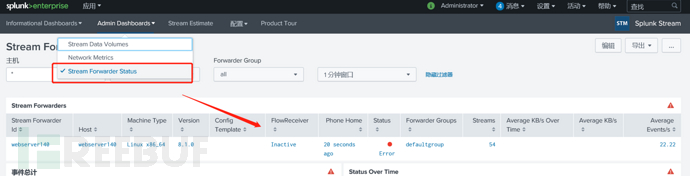
访问流转发器主机的8889端口,可以看到流转发器的数据捕获状态,可以看到在工作了,能看到也是对应可以收集54种流:
好了,现在已经配置了通信了,那么需要设置,抓哪些包,以及收哪些包,在流配置这里可以看到stream应用已经内置了几十种各种流,我这里全部开启: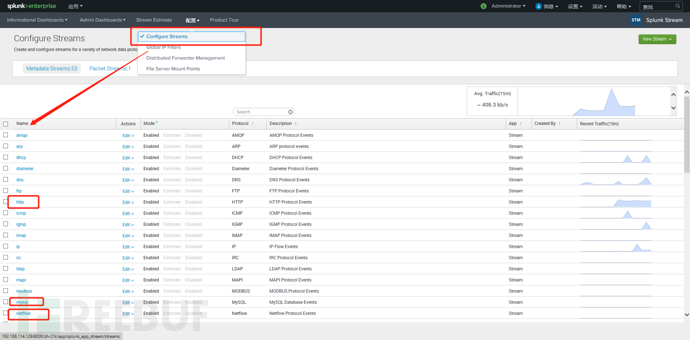
在组配置这里可以看到内置的默认组,已经识别了web服务器webserver140,可以编辑想收什么流,我这里收全部:
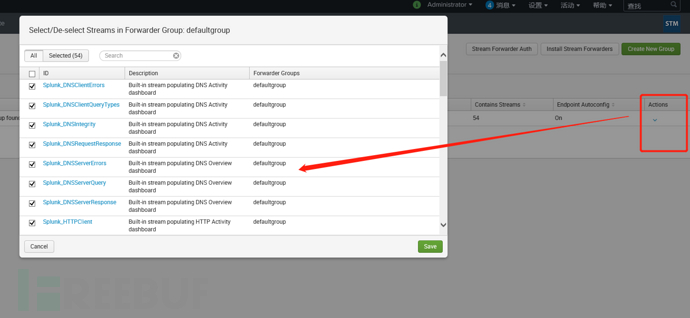
验证数据
使用kali的burp对web服务器进行简单的密码爆破攻击,验证一下,简单来个100-999的密码集,只要splunk实例能搜索到这些http日志即可成功:
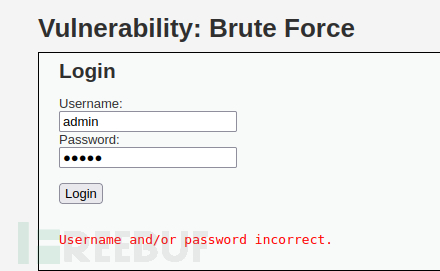

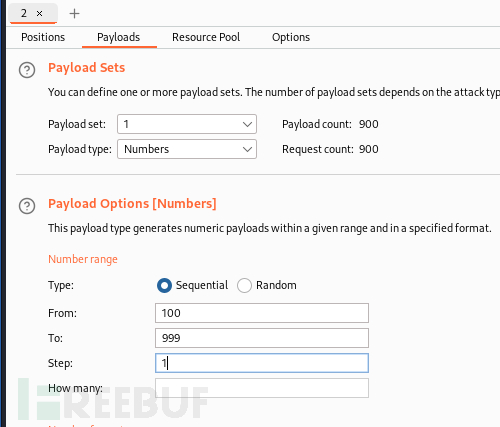
收到了:
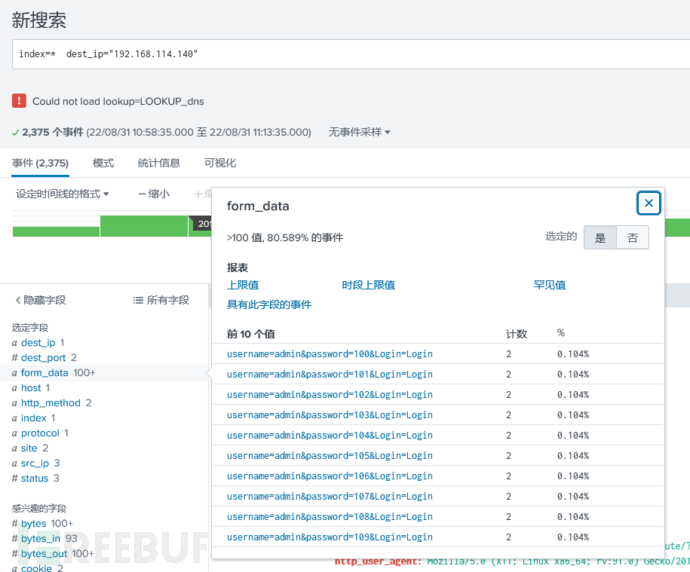
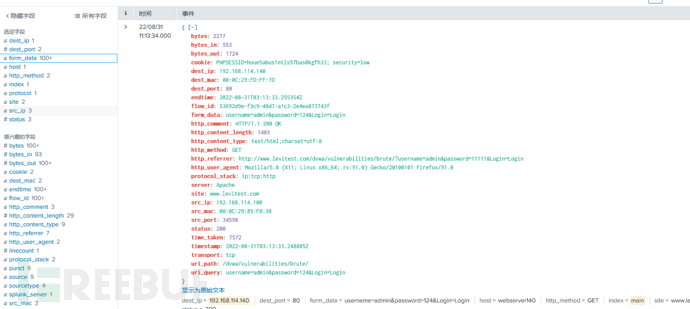
日志长这样,json格式是最爽的。因为是键值对,splunk范式化自动完成。左边一堆字段选择,想看啥都行。那么现在,数据导入最终完成了:
总结
splunk一如既往地灵活,特别是在数据导入方面,真的是啥都收,怎么收都行。日志文件、流量、指标数据等等
soc运营很大程度上不仅是收日志,还要出告警。出告警就是涉及到我该如何通过他的SPL搜索语言,搜索出我想要知道的信息。(想知道什么信息?这很重要,先按下不表)
告警出来了,研判依然很重要。这就涉及漏洞的学习
名词解释
indexer:索引器,splunk实例,接收各路来的数据用作解析,存储、索引、被搜索
search head:搜索头,splunk实例,用作分布式搜索,知识管理,告警报表管理,仪表板展示
universal forwarder:通用转发器,没有web的简单splunk实例,占用资源少,只做收发
deploy-server:部署服务器,专门管理转发器,统一下发各种配置
heavy forwarder:重型转发器,完整的splunk实例
independence stream forwarder:独立的流转发器,专门捕获数据流
SPL:splunk搜索语言

若有收获,就点个赞吧
0 人点赞
