论文
基于特征聚类的海量恶意代码在线自动分析模型
以下内容仅为全文的部分信息,建议自己查看原文
针对传统海量恶意代码分析方法中自动特征提取能力不足以及家族判定时效性差等问题,通过动静态方法对大量样本行为构成和代码片段分布规律的研究,提出了基于特征聚类的海量恶意代码在线自动分析模型,包括基于API行为和代码片段的特征空间构建方法、自动特征提取算法和基于LSH的近邻聚类算法。
实验结果表明该模型具有大规模样本自动特征提取、支持在线数据聚类、家族判定准确率高等优势,依据该模型设计的原型系统实用性较强。
引言
随着互联网的迅猛发展,伴随而来的网络安全局面日益复杂,网络用户受到的安全威胁日益加大,用户利益受到损害的安全事件不断增多,其中由恶意代码引发的用户信息泄漏、网银被盗、主机被控等问题层出不穷。恶意代码主要包括计算机病毒、蠕虫、木马、僵尸程序等。
恶意代码分析一直是业界最为关注的热点,病毒源代码公开、自动生成机的普及、黑客工具的肆意传播使得其已经形成灰色产业链,导致恶意代码数量爆炸式增长,为分析工作带来严峻挑战。
主要表现在2个方面:
一是如何能自动提取反映代码本质的特征,为下一步进行自动分析或人工分析提供更为全面描述信息;
一是在面对实时出现的大量未知恶意代码,如何能更加快速对未知样本作出家族判定,从而提升处置速度或提高人工分析效率。
本文针对恶意代码分析工作中自动特征提取能力不足和家族判定时效性差问题,通过对大量样本的深入研究,提出了基于特征聚类的海量恶意代码在线自动分析模型(OAM,online analytical model of massive malware)。
该模型主要由特征空间构建、自动特征提取及快速聚类分析3个部分组成。
特征空间构建:提出了基于统计和启发式的代码特征空间构建方法,自动特征提取部分提出了由API行为和代码片段构成的样本特征向量描述方法,快速聚类分析部分提出了基于位置敏感散列(LSH,locality-sensitive hashing)的快速近邻聚类算法。
该模型可自动完成未知样本的行为及代码特征分析,并快速识别该样本是否为已知家族或新增家族。依据该模型设计的原型系统在海量样本数据集上进行了测试,结果表明可自动提取更为全面的行为和代码特征,家族判定准确率高,聚类速度快。
国内外研究现状
分析恶意代码的功能和危害是恶意代码分析的基础,目前主要有静态分析法和动态分析方法。
静态分析:不运行恶意代码而是通过文件结构分析、反汇编、反编译等方法对恶意代码的可执行文件进行分析的方法。该方法可以了解恶意代码的程序流程和功能,获取用于检测和查杀恶意代码的静态特征。
动态分析:在一个可控的环境内运行恶意代码,分析恶意代码与运行环境之间交互行为的方法。该方法通过捕捉环境在运行恶意代码前后发生的变化,在不同层次上给出恶意代码的指令或系统调用描述,从而近似还原恶意代码实际功能。Egele[1]总结并分析了当前主流的动静态分析工具,例如静态分析方法常用的反汇编工具IDA和SAFE开发的PE文件解析器,动态分析方法常用的Anubis、CWSandbox、NormanSandbox、Joebox等均可以从系统调用、API操作、文件系统操作等角度对恶意代码进行分析。
为了能从本质刻画恶意码特点和行为模式,研究人员采用了不同的恶意代码特征提取方法用于表示恶意代码样本。
Kephart Griffin[2]等人:最早提出了从样本提取二进制字符串作为样本特征的方法,该方法基于5-gram马尔可夫模型选出48byte字符串代表恶意代码并用其检测终端是否感染恶意代码。
SATHYANARAYAN V S、谷歌[3,4]:提出用API作为恶意代码特征的方法,即通过分析源码或者监测系统调用提取恶意代码样本的API集合或序列,辅以调用次数或参数构成表示样本的特征向量。
Kolbitsch Clemens[5]:提出用指令间调用关系作为表示样本特征的方法。随着恶意代码网络行为的增多,一些研究人员采用网络行为[6,7]作为恶意代码特征。
Morales[8]:针对2000余个样本分析了DNS、NetBIOS、TCP、UDP、ICMP等网络协议,分析发现其和正常代码的网络行为有较大不同。Perdisci[9]则捕获恶意代码发出的HTTP请求并从中提取URL结构信息作为恶意代码特征。随着恶意代码的不断增多和演变,为了便于描述和定性,主流安全厂商对其可检测的恶意代码均赋予一个名字,虽然各自的命名规则不同,但其相同点都是将有类似行为或特点的恶意代码归为一个家族,即大量恶意代码间存在类别关系[10,11]。
Rieck Konrad[12]等人:针对新增代码通过SVM分类器判断其是否属于已知家族或不属于恶意代码。SATHYANARAYAN V S [13]:通过统计恶意代码和白代码样本关键API及其频度的卡方值,从而判断未知代码是否为恶意代码。
以上方法或系统均选取了不同的恶意代码特征提取方法,并通过分类或聚类方法实现未知代码的家族判定,但也存在一些问题,主要表现在:
- 提取的特征过多依赖人工经验,在适应更多尤其是未知恶意代码类型时有一定局限性;
- 提取方法和流程较为复杂不利于将其自动化,无法较快完成大规模样本的自动特征提取;
- 大多数分类或聚类算法不适合海量高维的样本集,无法快速完成大规模未知样本的家族判定。
针对上述问题,在分析了大量恶意代码后,提出了恶意代码特征由API行为和代码片段构成,其中API行为作为决定恶意代码功能的主要因素往往也是区分不同类别(即家族)的主要因素,而代码片段特征由于其反应了代码编写环境或编写习惯则在更精确地区分变种方面有较好表现。
针对API行文和代码特征,基于动态行为和DUMP文件分析方法,结合统计技术,设计了自动化程度更高的特征提取算法。
由于需要对大规模的未知样本进行家族判定,采用聚类分析方法就要求尽可能只对数据处理一次,因此要求聚类算法具备较低的时间空间复杂度、能够处理高速数据流[17~19],在Bayer等人提出[20]高速层次聚类算法基础上,结合划分聚类提出了基于LSH近邻聚类算法。
综合上述三点,本文设计了基于特征聚类的海量恶意代码在线自动分析模型。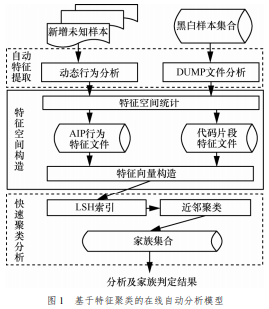
特征空间构造
通常恶意代码的行为特征主要依靠启发式方法依靠人工和经验总结,其确定的可疑API相对固定也缺乏在大数据集上的验证。为了能更加合理地确定API行为集合和代码片段,基于统计方法设计了通过大量黑白样本集进行特征集合自动选择的构造方法。
- 针对行为特征采用的构造方法
定义1:白样本为一个软件其静态特征与其所在的系统环境及其活动对系统不会产生威胁,不会对系统造成破坏、没有信息窃取行为的软件样本。
定义2:黑样本为一个软件对其所在环境如系统和网络产生威胁,比如常见的病毒、木马蠕虫、间谍件、广告件等。
定义3:样本特征S是指所有行为特征和关键代码片段特征的集合,s指集合中的某个元素。
定义4:PMs()指某个特征s在黑样本集合M中出现的概率。
定义5:PTs()指某个特征s在白样本集合T出现的概率。
定义6:
6.2 针对关键代码片段特征采用的构造方法提取代码片段的方法借鉴了语言统计模型思想,代码片段即二进制文件里一段连续的二进制串。
其想法源于静态分析方法,源代码分析是静态分析中最常用的方法,分析人员通过IDA进行反汇编后查看字符串可以迅速了解程序的流程和功能,但是该方法依赖反汇编手段,针对加壳样本或非PE文件的样本等问题都无法很好解决。
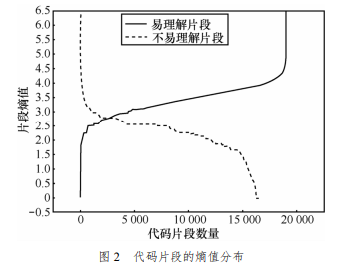
为了能够尽可能自动提取可用于聚类的代码片段,基于统计语言模型的思想,自动提取样本中由26个英文字母和数字组成的连续字符串,分别计算其在可理解和难理解字符串集合中的熵值。
易理解代码片段和难理解代码片段集合通过选取一定数量的文件进行代码片段提取,然后对结果进行人工标注。
通过实验发现易理解代码片段熵主要分布在2~5之间,表明熵值过低的代码片段确实无意义,但熵值过高也不是易于理解的,因此在提取时选取熵值在2~5之间的易理解代码片段。
样本特征向量化
根据上述方法,在十万规模的黑白样本集上针对API行为进行训练后,遴选出相对固定的API特征空间集合。针对代码片段在万级规模的样本机上训练后,确定熵的取值范围。比如样本A和样本B的字符串提取结果分别为A(TObject,Sender,Integer,kernel32.dll,SelfDel)、B(Integer,kernel32.dll,Boolean,Height,GetProcAddress,SelfDel),X(kernel32.dll,Boolean,Height,GetProcAddress,SelfDel),由API行为和代码片段构成样本的描述文件。由于描述文件不利于后续聚类计算,因此针对所有字符串形式的API和代码段采用CRC64进行转换排序构成总的向量空间,每个样本的描述文件可以转换成01的向量。实际计算时由于其占用空间过大,实际采用索引形式向量。那么由A、B构成的总结果集将以“字符串-索引”形式存储,即(TObject-0,Sender-1,Integer-2,kernel32.dll-3,Boolean-4,Height-5,GetProcAddress-6,SelfDel-7,copyself-8)。向量形式:A111100010、B001111110、X000111110。索引形式:A(0,1,2,3,7)、B(2,3,4,5,6,7)、X(3,4,5,6,7)。
快速聚类算法
算法描述
算法的基本思想是:每一个样本和与之最近的样本属于同一家族的概率最大。针对新增样本在已聚类样本集中查询其最近邻,计算新增样本与其所有最近邻所在家族的距离,其中最短距离如果超过设定阈值就将新增样本归为最短近邻所在家族,否则形成新家族。
step1:根据新样本特征向量计算LSH值。
step2:根据LSH值查询其最近邻集合。
step3:分别计算新样本与集合中每个样本所在类的距离。
step4:比较得到最小距离,如果其超过阈值,将新样本归为最近相似样本所在类,否则单独形成一个新类。
step5:重新计算发生变化的类中心点。伪代码如下:
输入:新样本特征向量FV1,FV2,…,FVn。
输出:聚类后的簇和各簇的中心点。
Begin
end
LSH函数描述
由于经过自动提取的样本API行为特征集合规模庞大,样本特征向量中仅API行为部分的维度超过27000,如果样本数量也较大时,采用分裂聚类法需要两两计算样本距离其计算复杂度是无法满足实时性的要求。
LSH算法的基本思想是基于散列函数无需两两计算即可快速得到某样本的近邻,从而大幅降低计算规模。
需要根据度量样本相似度的距离标准选择适合的LSH函数,而该函数只要满足单调递增映射关系即可[21]。
Charikar提出了随机投影位置敏感散列函数族适用于高维数据同计算余弦距离判定相似度的场景[22]。
OMA模型中确定2个样本是否为同一家族时通过计算其Jaccard距离的度量标准,即如果Jaccard距离小于R即为同一家族,否则为不同家族,由于基于抽样(bitsampling)的散列函数构建方法适用于原始特征向量每一维的取值为{0,1}的特征串,本文采用了这个方法。其散列函数是一组随机选取d维特征向量中的一个K维子向量。按照索引集中的每个索引,从每个结果对应的原始向量中取出对应的值(0或1),拼接成子向量。
这样每个结果在一次随机子向量计算之后又会有一个对应的长度为K子向量,如果2个结果对应的子向量相同,即可认为2个向量相似;再选取L个这样的函数。例如样本A、B和X的原始API特征向量分别为:111100010、001111110和000111110,随机选取L=4的索引(3,4,7,8)作为子向量,A的向量子集为1010、B的向量子集是1110、X子集为1110,则A不是X的最近邻而B是X的最近邻。
算法分析
假设系统目前需要聚类的数据集总数n、样本特征向量维度d,针对每个向量求其LSH值的时间为t,则预处理复杂度为O()nLkt;最近邻集合逐一计算Jacarrd距离的复杂度为O()ncd,其中,c是最近邻集合的元素数目,由于随着样本集的不同c并不是一个固定值,但是实际测试时其远小于n,因此总的复杂度O(nLkt+ncd),一般情况下远小于O(n²),最坏情况下c趋于n,即每个样本都差异过大独自聚成一类。

若有收获,就点个赞吧
0 人点赞
