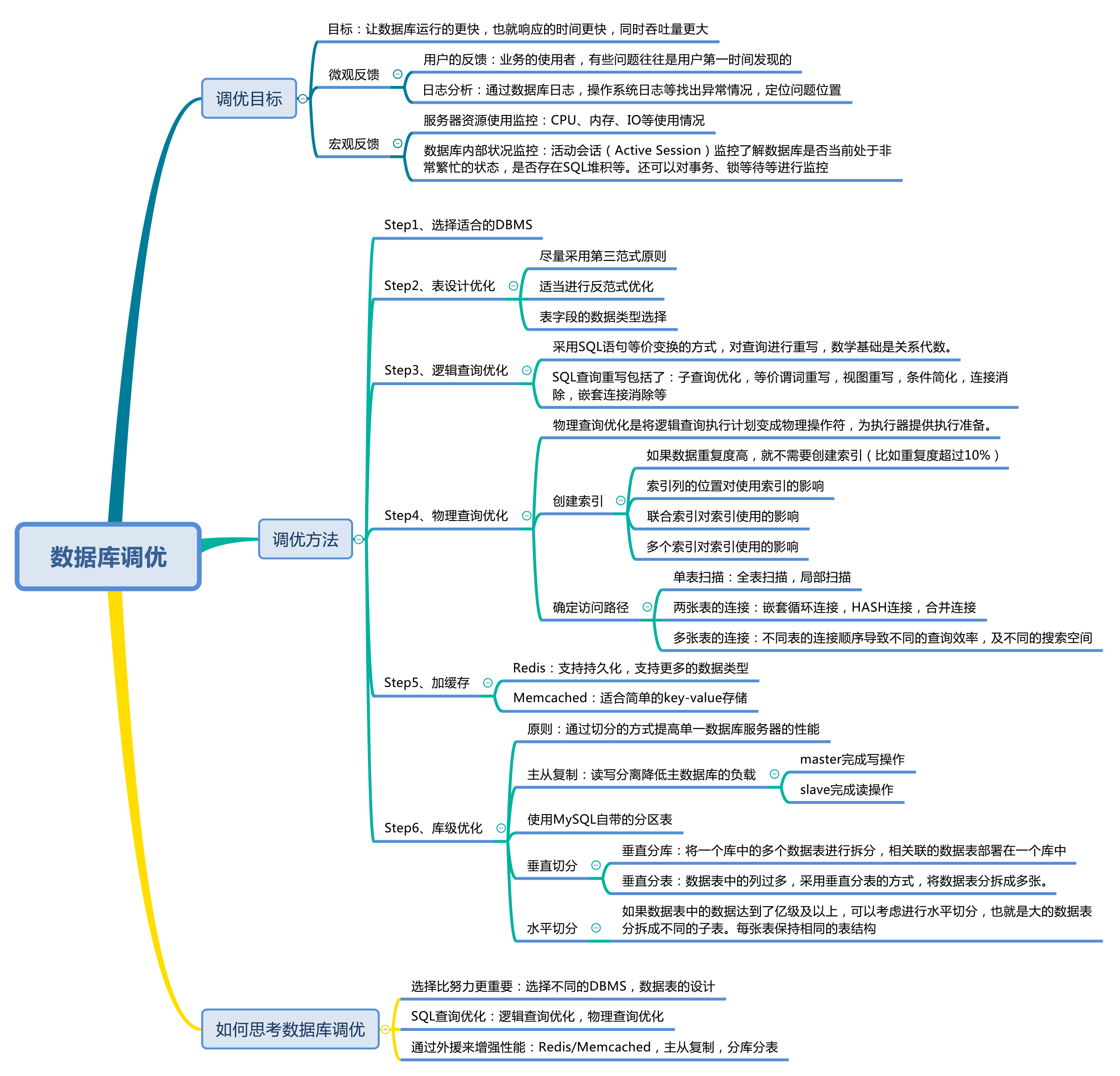
数据库调优的目标
对数据库进行调优,都有哪些维度可以进行选择?
第一步,选择适合的 DBMS
第二步,优化表设计
- 遵循第三范式的原则
- 需要进行多表联查的时候,可以采用反范式进行优化
- 表字段的数据类型选择,关系到了查询效率的高低以及存储空间的大小。一般来说,如果字段可以采用数值类型就不要采用字符类型;字符长度要尽可能设计得短一些。针对字符类型来说,当确定字符长度固定时,就可以采用 CHAR 类型;当长度不固定时,通常采用 VARCHAR 类型。
第三步,优化逻辑查询
SQL 查询优化,可以分为逻辑查询优化和物理查询优化。
逻辑查询优化就是通过改变 SQL 语句的内容让 SQL 执行效率更高效,采用的方式是对 SQL 语句进行等价变换,对查询进行重写。重写查询的数学基础就是关系代数。
SQL 的查询重写包括了:
- 子查询优化
- 等价谓词重写
- 视图重写
- 条件简化
- 连接消除
- 嵌套连接消除
例子:
# 在 WHERE 中使用函数会导致慢SELECT comment_id, comment_text, comment_time FROM product_comment WHERE SUBSTRING(comment_text, 1,3)='abc'# 查询重写SELECT comment_id, comment_text, comment_time FROM product_comment WHERE comment_text LIKE 'abc%'
第四步,优化物理查询
物理查询优化是将逻辑查询的内容变成可以被执行的物理操作符,从而为后续执行器的执行提供准备。它的核心是高效地建立索引,并通过这些索引来做各种优化。
根据实际情况来创建索引:
- 如果数据重复度高,就不需要创建索引。通常在重复度超过 10% 的情况下,可以不创建这个字段的索引。比如性别这个字段(取值为男和女)。
- 要注意索引列的位置对索引使用的影响。比如我们在 WHERE 子句中对索引字段进行了表达式的计算,会造成这个字段的索引失效。
- 要注意联合索引对索引使用的影响。我们在创建联合索引的时候会对多个字段创建索引,这时索引的顺序就很重要了。比如我们对字段 x, y, z 创建了索引,那么顺序是 (x,y,z) 还是 (z,y,x),在执行的时候就会存在差别。
- 要注意多个索引对索引使用的影响。索引不是越多越好,因为每个索引都需要存储空间,索引多也就意味着需要更多的存储空间。此外,过多的索引也会导致优化器在进行评估的时候增加了筛选出索引的计算时间,影响评估的效率。
查询所采用的路径:
- 单表扫描: 对于单表扫描来说,我们可以全表扫描所有的数据,也可以局部扫描。
- 两张表的连接: 常用的连接方式包括了嵌套循环连接、HASH 连接和合并连接。
- 多张表的连接: 多张数据表进行连接的时候,顺序很重要,因为不同的连接路径查询的效率不同,搜索空间也会不同。
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等),通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。在这个部分中,我们需要掌握的重点是对索引的创建和使用。
**
第五步,使用 Redis 或 Memcached 作为缓存
优缺点
第六步,库级优化
库级优化是站在数据库的维度上进行的优化策略,比如控制一个库中的数据表数量。另外我们可以采用主从架构优化我们的读写策略。
- 读和写的业务量都很大, 可以采用读写分离的方式降低主数据库的负载,比如用主数据库(master)完成写操作,用从数据库(slave)完成读操作。
- 数据量级达到亿级以上, 可以对数据库分库分表
- MySQL 自带的分区表功
- 垂直切分和水平切分
- 如果数据库中的数据表过多,可以采用垂直分库的方式,将关联的数据表部署在一个数据库上。
- 如果数据表中的列过多,可以采用垂直分表的方式,将数据表分拆成多张,把经常一起使用的列放到同一张表里。
- 如果数据表中的数据达到了亿级以上,可以考虑水平切分,将大的数据表分拆成不同的子表,每张表保持相同的表结构。
我们该如何思考和分析数据库调优这件事
- 首先,选择比努力更重要。
- 通过外援来增强数据库的性能

若有收获,就点个赞吧
0 人点赞
