事务需要满足 ACID, 而事务隔离控制的是事务间的行为.
事务并发处理可能存在的异常都有哪些?
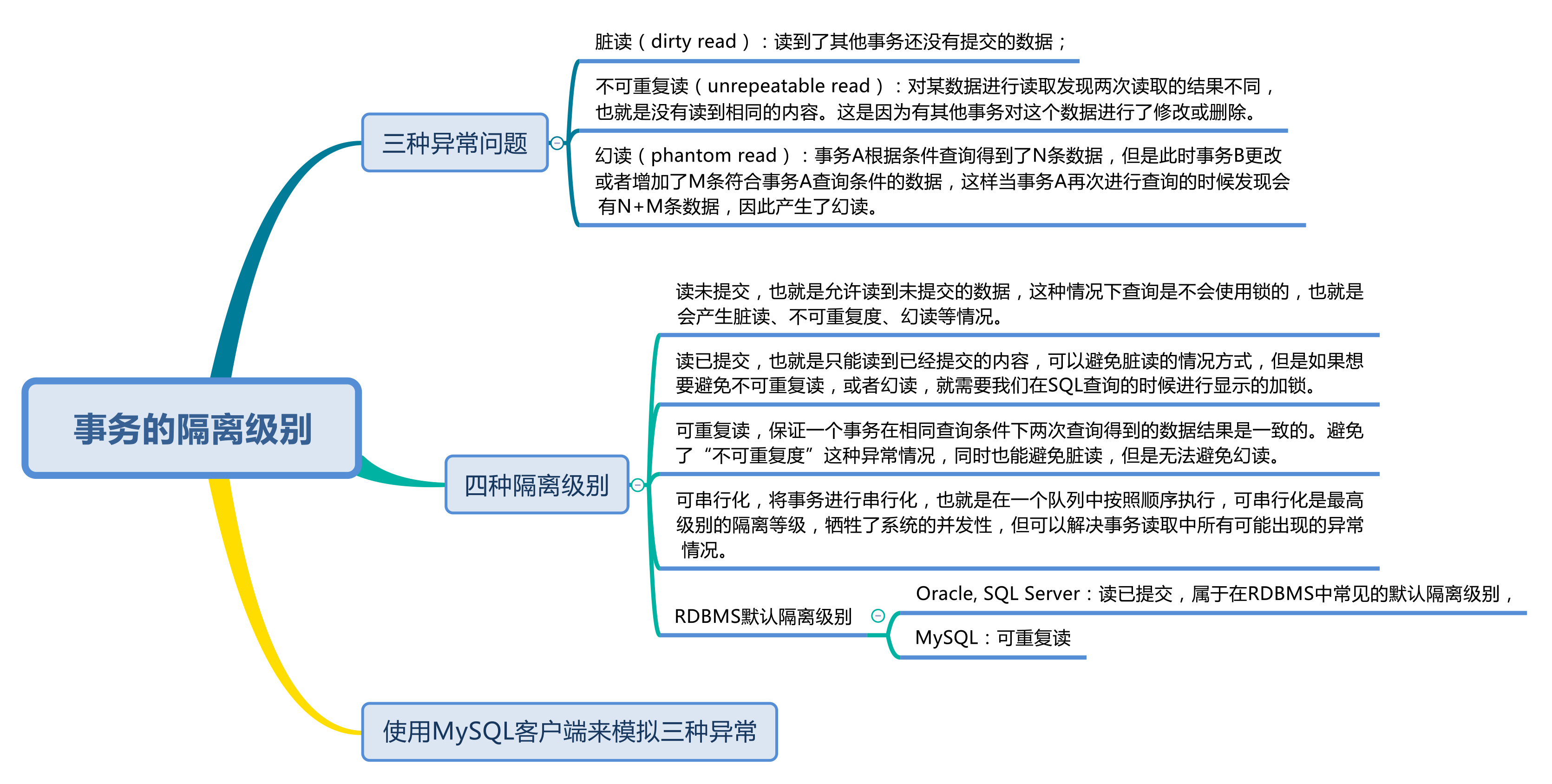
SQL-92 标准中已经对 3 种异常情况进行了定义,这些异常情况级别分别为脏读(Dirty Read)、不可重复读(Nnrepeatable Read)和幻读(Phantom Read)。
脏读
读到未提交数据.
比如说我们有个英雄表 heros_temp,如下所示:
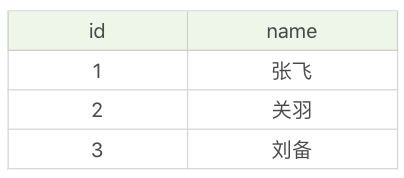
第一天,小张访问数据库,正在进行事务操作,往里面写入一个新的英雄“吕布”:
SQL> BEGIN;SQL> INSERT INTO heros_temp values(4, '吕布');
当小张还没有提交该事务的时候,小李又对数据表进行了访问,他想看下这张英雄表里都有哪些英雄:
SQL> SELECT * FROM heros_temp;
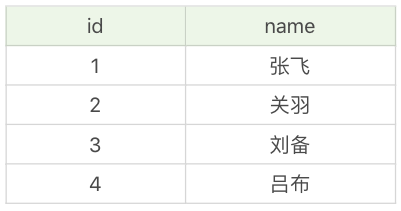
这个时候小张还没有提交事务,但是小李却读到了小张还没有提交的数据,这种现象我们称之为“脏读”。
不可重复读
同一搜索条件, 前后两次结果不同. “不同” 一词在字面上范围很大, 但是在该异常情况下要注意前提是 “同一搜索条件”, 而结果变化了 (结果条数没变)
第二天,小张想查看 id=1 的英雄是谁,于是他进行了 SQL 查询:
SQL> BEGIN;SQL> SELECT name FROM heros_temp WHERE id = 1;

然而此时,小李开始了一个事务操作,他对 id=1 的英雄姓名进行了修改,把原来的“张飞”改成了“张翼德”:
SQL> BEGIN;SQL> UPDATE heros_temp SET name = '张翼德' WHERE id = 1;
然后小张再一次进行查询,同样也是查看 id=1 的英雄是谁:
SQL> SELECT name FROM heros_temp WHERE id = 1;

从这个例子中,我们能看到小张和小李,分别开启了两个事务,针对客户端 A 和客户端 B,我用时间顺序的方式展示下他们各自执行的内容:

幻读
相同查询条件, 第二次查询结果比第一次查询结果多了, 且包含第一次查询结果.
第三天,小张想要看下数据表里都有哪些英雄,他开始执行下面这条语句:
SQL> SELECT * FROM heros_temp;
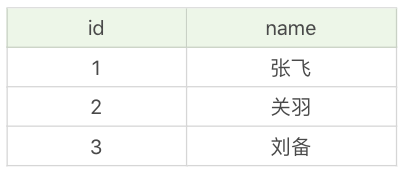
这时当小张执行完之后,小李又开始了一个事务,往数据库里插入一个新的英雄“吕布”:
SQL> BEGIN;SQL> INSERT INTO heros_temp values(4, '吕布');
不巧的是,小张这时忘记了英雄都有哪些,又重新执行了一遍查询:
SQL> SELECT * FROM heros_temp;
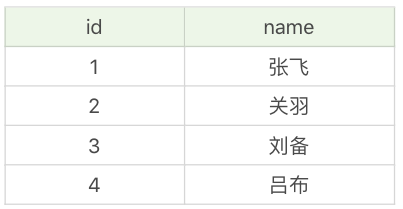
区别总结
总结下这三种异常情况的特点:
- 脏读:读到了其他事务还没有提交的数据。
- 不可重复读:对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为有其他事务对这个数据同时进行了修改或删除。
- 幻读:事务 A 根据条件查询得到了 N 条数据,但此时事务 B 更改或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候发现会有 N+M 条数据,产生了幻读。
事务隔离的级别有哪些?
脏读、不可重复读和幻读这三种异常情况,是在 SQL-92 标准中定义的,同时 SQL-92 标准还定义了 4 种隔离级别来解决这些异常情况。
解决异常数量从少到多的顺序(比如读未提交可能存在 3 种异常,可串行化则不会存在这些异常)决定了隔离级别的高低,这四种隔离级别从低到高分别是:
- 读未提交(READ UNCOMMITTED )
- 读已提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 可串行化(SERIALIZABLE)
这些隔离级别能解决的异常情况如下表所示:
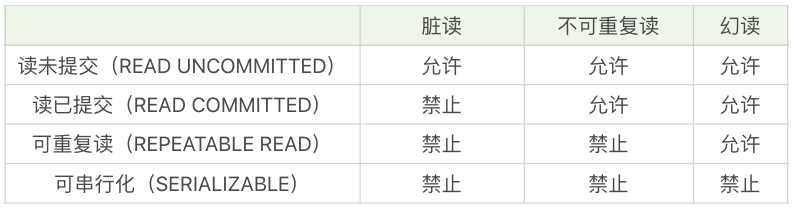
- MySQL 默认的隔离级别就是可重复读。
- 可串行化牺牲了系统的并发性
使用 MySQL 客户端来模拟三种异常
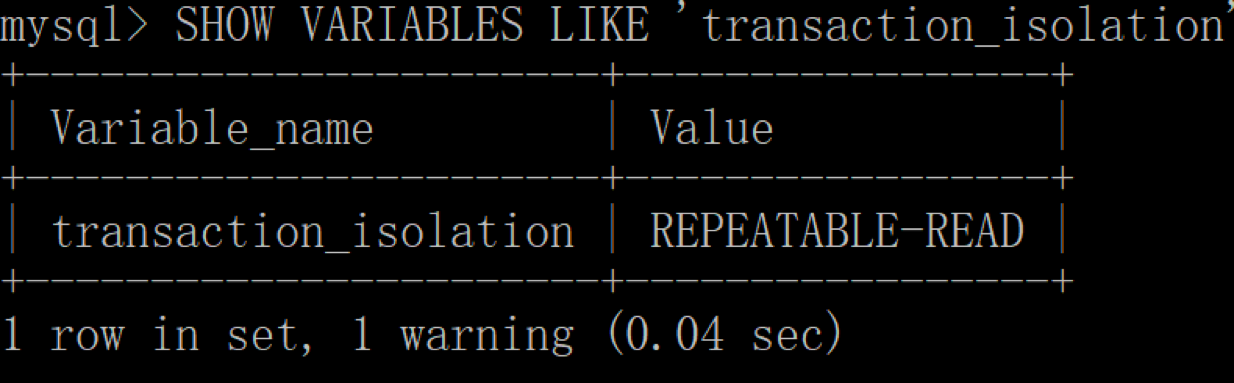
查看下当前会话的隔离级别:
mysql> SHOW VARIABLES LIKE 'transaction_isolation';
把隔离级别降到最低:
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
总结
隔离级别的实现满足了下面的两个条件:
- 正确性:只要能满足某一个隔离级别,一定能解决这个隔离级别对应的异常问题。
- 与实现无关:实际上 RDBMS 种类很多,这就意味着有多少种 RDBMS,就有多少种锁的实现方式,因此它们实现隔离级别的原理可能不同,然而一个好的标准不应该限制其实现的方式。
隔离级别越低,意味着系统吞吐量(并发程度)越大,但同时也意味着出现异常问题的可能性会更大。在实际使用过程中我们往往需要在性能和正确性上进行权衡和取舍
精选留言
LJK
老师好,对幻读有些迷惑,从网上看到幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,结果显示不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
作者回复: 你说的这种情况属于幻读。 当你INSERT的时候,也需要隐式的读取,比如插入数据时需要读取有没有主键冲突,然后再决定是否能执行插入。如果这时发现已经有这个记录了,就没法插入。
官方对幻读的定义是:The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times.
For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row. (详见:
https://dev.mysql.com/doc/refman/8.0/en/innodb-next-key-locking.html )
需要说明下,不可重复读 VS 幻读的区别:
不可重复读是同一条记录的内容被修改了,重点在于UPDATE或DELETE
幻读是查询某一个范围的数据行变多了或者少了,重点在于INSERT
所以,SELECT 显示不存在,但是INSERT的时候发现已存在,说明符合条件的数据行发生了变化,也就是幻读的情况,而不可重复读指的是同一条记录的内容被修改了。
参考

若有收获,就点个赞吧
0 人点赞
