从任意数据结构生成 XML
原文: https://docs.oracle.com/javase/tutorial/jaxp/xslt/generatingXML.html
本节使用 XSLT 将任意数据结构转换为 XML。
以下是该过程的概述:
修改读取数据的现有程序,使其生成 SAX 事件。 (该程序是真正的解析器还是仅仅是某种数据过滤器,目前无关紧要)。
使用 SAX“解析器”为转换构造
SAXSource。使用与上一个练习中创建的相同的
StreamResult对象来显示结果。 (但请注意,您可以轻松创建DOMResult对象以在内存中创建 DOM)。使用变换器对象将源连接到结果以进行转换。
对于初学者,您需要一个要转换的数据集和一个能够读取数据的程序。接下来的两节创建一个简单的数据文件和一个读取它的程序。
创建一个简单的文件
此示例使用地址簿的数据集PersonalAddressBook.ldif 。如果你还没有这样做, download the XSLT examples 并将它们解压缩到 install-dir / jaxp-1_4_2- 发布日期 ] / samples目录。此处显示的文件是通过在 Netscape Messenger 中创建新的地址簿,为其提供一些虚拟数据(一个地址卡),然后以 LDAP 数据交换格式(LDIF)格式导出它来生成的。在解压缩 XSLT 示例后,它包含在目录xslt / data中。
以下图显示已创建的通讯簿条目。
图地址簿条目
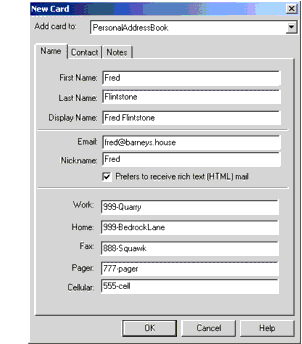
导出地址簿会生成如下所示的文件。我们关心的文件部分以粗体显示。
dn: cn=Fred Flintstone,mail=fred@barneys.housemodifytimestamp: 20010409210816Zcn: Fred Flintstonexmozillanickname: Fredmail: Fred@barneys.housexmozillausehtmlmail: TRUEgivenname: Fredsn: Flintstonetelephonenumber: 999-Quarryhomephone: 999-BedrockLanefacsimiletelephonenumber: 888-Squawkpagerphone: 777-pagercellphone: 555-cellxmozillaanyphone: 999-Quarryobjectclass: topobjectclass: person
请注意,文件的每一行都包含一个变量名,一个冒号和一个空格,后跟一个变量值。 sn变量包含人的姓氏(姓氏),变量cn包含来自地址簿条目的DisplayName字段。
创建一个简单的解析器
下一步是创建一个解析数据的程序。
注:本节讨论的代码位于AddressBookReader01.java中,解压缩 XSLT examples 后可在xslt目录中找到]进入 install-dir / jaxp-1_4_2- 发布日期 /样例目录。
该程序的文本如下所示。这是一个非常简单的程序,甚至不会为多个条目循环,因为毕竟它只是一个演示。
import java.io.*;public class AddressBookReader01 {public static void main(String argv[]) {// Check the argumentsif (argv.length != 1) {System.err.println("Usage: java AddressBookReader01 filename");System.exit (1);}String filename = argv[0];File f = new File(filename);AddressBookReader01 reader = new AddressBookReader01();reader.parse(f);}// Parse the input filepublic void parse(File f) {try {// Get an efficient reader for the fileFileReader r = new FileReader(f);BufferedReader br = new BufferedReader(r);// Read the file and display its contents.String line = br.readLine();while (null != (line = br.readLine())) {if (line.startsWith("xmozillanickname: "))break;}output("nickname", "xmozillanickname", line);line = br.readLine();output("email", "mail", line);line = br.readLine();output("html", "xmozillausehtmlmail", line);line = br.readLine();output("firstname","givenname", line);line = br.readLine();output("lastname", "sn", line);line = br.readLine();output("work", "telephonenumber", line);line = br.readLine();output("home", "homephone", line);line = br.readLine();output("fax", "facsimiletelephonenumber", line);line = br.readLine();output("pager", "pagerphone", line);line = br.readLine();output("cell", "cellphone", line);}catch (Exception e) {e.printStackTrace();}}}
该程序包含三种方法:
main
main方法从命令行获取文件的名称,创建解析器的实例,并将其设置为解析文件。当我们将程序转换为 SAX 解析器时,此方法将消失。 (这是将解析代码放入单独方法的一个原因)。
parse
该方法对主程序发送给它的File对象进行操作。如您所见,它非常简单。效率的唯一让步是使用BufferedReader ,当你开始操作大文件时,它会变得很重要。
output
输出方法包含行结构的逻辑。它需要三个参数。第一个参数赋予方法显示的名称,因此它可以输出html作为变量名,而不是xmozillausehtmlmail 。第二个参数给出了存储在文件中的变量名称( xmozillausehtmlmail )。第三个参数给出包含数据的行。然后,例程从行的开头剥离变量名称,并输出所需的名称和数据。
运行AddressBookReader01样例
导航至
样例目录。%cd install-dir / jaxp-1_4_2- 释放日期 /样例。
Download the XSLT examples by clicking this link并将它们解压缩到 install-dir/ jaxp-1_4_2-释放日期/样例目录。导航到
xslt目录。cd xslt
Compile the
AddressBookReader01sample.键入以下命令:
% javac AddressBookReader01.java
Run the
AddressBookReader01sample on a data file.在下面的例子中,
AddressBookReader01在上面显示的文件PersonalAddressBook.ldif上运行,在解压缩样例包后找到xslt / data目录。% java AddressBookReader01 data/PersonalAddressBook.ldif
您将看到以下输出:
nickname: Fredemail: Fred@barneys.househtml: TRUEfirstname: Fredlastname: Flintstonework: 999-Quarryhome: 999-BedrockLanefax: 888-Squawkpager: 777-pagercell: 555-cell
这比创建简单文件中显示的文件更具可读性。
创建生成 SAX 事件的分析器
本节说明如何使解析器生成 SAX 事件,以便您可以将其用作 XSLT 转换中SAXSource对象的基础。
注:本节讨论的代码位于AddressBookReader02.java中,解压缩 XSLT examples 后可在xslt目录中找到]进入 install-dir / jaxp-1_4_2- 发布日期 /样例目录。 AddressBookReader02.java改编自AddressBookReader01.java ,因此这里仅讨论两个示例之间的代码差异。
AddressBookReader02需要以下突出显示的类,这些类未在AddressBookReader01中使用。
import java.io.*;import org.xml.sax.*;import org.xml.sax.helpers.AttributesImpl;
该应用程序还扩展了XmlReader 。此更改将应用程序转换为生成适当 SAX 事件的解析器。
public class AddressBookReader02 implements XMLReader { /* ... */ }
与AddressBookReader01示例不同,此应用程序没有主方法。
以下全局变量将在本节后面使用:
public class AddressBookReader02 implements XMLReader {ContentHandler handler;String nsu = "";Attributes atts = new AttributesImpl();String rootElement = "addressbook";String indent = "\n ";// ...}
SAX ContentHandler是获取解析器生成的 SAX 事件的对象。为了使应用程序进入XmlReader ,应用程序定义了setContentHandler方法。处理器变量将保存对setContentHandler被调用时发送的对象的引用。
当解析器生成 SAX 元素事件时,它将需要提供命名空间和属性信息。因为这是一个简单的应用程序,所以它为这两个应用程序定义了空值。
应用程序还定义了数据结构的根元素(地址簿)并设置了缩进字符串以提高输出的可读性。
此外,修改了解析方法,以便将InputSource (而不是文件)作为参数,并考虑它可以生成的异常:
public void parse(InputSource input) throws IOException, SAXException
现在,不是像AddressBookReader01那样创建一个新的FileReader实例,而是由InputSource对象封装阅读器:
try {java.io.Reader r = input.getCharacterStream();BufferedReader Br = new BufferedReader(r);// ...}
注:下一节将介绍如何创建输入源对象,放入其中的内容实际上是一个缓冲读取器。但AddressBookReader可能被其他人使用,在某个地方。无论您获得何种读者,此步骤都可确保处理效率。
下一步是修改 parse 方法,为文档的开头和根元素生成 SAX 事件。以下突出显示的代码可以做到:
public void parse(InputSource input) {try {// ...String line = br.readLine();while (null != (line = br.readLine())) {if (line.startsWith("xmozillanickname: "))break;}if (handler == null) {throw new SAXException("No content handler");}handler.startDocument();handler.startElement(nsu, rootElement, rootElement, atts);output("nickname", "xmozillanickname", line);// ...output("cell", "cellphone", line);handler.ignorableWhitespace("\n".toCharArray(),0, // start index1 // length);handler.endElement(nsu, rootElement, rootElement);handler.endDocument();}catch (Exception e) {// ...}}
这里,应用程序检查以确保使用ContentHandler正确配置解析器。 (对于这个应用程序,我们不关心任何其他事情)。然后,它生成文档开始和根元素的事件,并通过发送根元素的结束事件和文档的结束事件来完成。
此时有两项值得注意:
setDocumentLocator事件尚未发送,因为这是可选的。如果重要的话,该事件将在startDocument事件之前立即发送。在根元素结束之前生成
ignorableWhitespace事件。这也是可选的,但它会大大提高输出的可读性,这很快就会看到。 (在这种情况下,空格由单个换行符组成,其发送方式与将字符发送到字符方法的方式相同:作为字符数组,起始索引和长度)。
现在正在为文档和根元素生成 SAX 事件,下一步是修改输出方法以为每个数据项生成适当的元素事件。删除对System.out.println(名称+“:”+文本)的调用并添加以下突出显示的代码可实现:
void output(String name, String prefix, String line)throws SAXException {int startIndex =prefix.length() + 2; // 2=length of ": "String text = line.substring(startIndex);int textLength = line.length() - startIndex;handler.ignorableWhitespace (indent.toCharArray(),0, // start indexindent.length());handler.startElement(nsu, name, name /*"qName"*/, atts);handler.characters(line.toCharArray(),startIndex,textLength;);handler.endElement(nsu, name, name);}
因为ContentHandler方法可以将SAXExceptions发送回解析器,所以解析器必须准备好处理它们。在这种情况下,没有预期的,因此如果发生任何应用程序,则只允许应用程序失败。
然后计算数据的长度,再次生成一些可忽略的空白以便于阅读。在这种情况下,只有一个级别的数据,因此我们可以使用固定缩进字符串。 (如果数据更加结构化,我们必须计算缩进的空间,具体取决于数据的嵌套)。
注:缩进字符串对数据没有影响,但会使输出更容易阅读。没有该字符串,所有元素将端到端连接:
<addressbook><nickname>Fred</nickname><email>...
接下来,以下方法使用ContentHandler配置解析器,以接收它生成的事件:
void output(String name, String prefix, String line)throws SAXException {// ...}// Allow an application to register a content event handler.public void setContentHandler(ContentHandler handler) {this.handler = handler;}// Return the current content handler.public ContentHandler getContentHandler() {return this.handler;}
必须实现其他几种方法才能满足XmlReader接口。出于本练习的目的,将为所有这些方法生成 null 方法。但是,生产应用程序需要实现错误处理器方法以生成更强大的应用程序。但是,对于此示例,以下代码为它们生成 null 方法:
// Allow an application to register an error event handler.public void setErrorHandler(ErrorHandler handler) { }// Return the current error handler.public ErrorHandler getErrorHandler() {return null;}
然后,以下代码为XmlReader接口的其余部分生成空方法。 (它们中的大多数对真正的 SAX 解析器很有价值,但对像这样的数据转换应用程序几乎没有影响)。
// Parse an XML document from a system identifier (URI).public void parse(String systemId) throws IOException, SAXException{ }// Return the current DTD handler.public DTDHandler getDTDHandler() { return null; }// Return the current entity resolver.public EntityResolver getEntityResolver() { return null; }// Allow an application to register an entity resolver.public void setEntityResolver(EntityResolver resolver) { }// Allow an application to register a DTD event handler.public void setDTDHandler(DTDHandler handler) { }// Look up the value of a property.public Object getProperty(String name) { return null; }// Set the value of a property.public void setProperty(String name, Object value) { }// Set the state of a feature.public void setFeature(String name, boolean value) { }// Look up the value of a feature.public boolean getFeature(String name) { return false; }
您现在有一个可用于生成 SAX 事件的解析器。在下一节中,您将使用它来构造一个 SAX 源对象,该对象将允许您将数据转换为 XML。
使用 Parser 作为SAXSource
给定一个 SAX 解析器用作事件源,您可以构造一个转换器来生成结果。在本节中,将更新TransformerApp以生成流输出结果,尽管它可以轻松生成 DOM 结果。
注:注意:本节讨论的代码位于TransformationApp03.java中,解压缩 XSLT examples后可在xslt目录中找到进入 install-dir / jaxp-1_4_2- 发布日期 /样例目录。
首先, TransformationApp03与TransformationApp02的不同之处在于它需要导入以构造SAXSource对象。这些类在下面突出显示。此时不再需要 DOM 类,因此已被丢弃,尽管将它们留在其中不会造成任何伤害。
import org.xml.sax.SAXException;import org.xml.sax.SAXParseException;import org.xml.sax.ContentHandler;import org.xml.sax.InputSource;import javax.xml.transform.sax.SAXSource;import javax.xml.transform.stream.StreamResult;
接下来,应用程序创建一个 SAX 解析器,而不是创建 DOM DocumentBuilderFactory实例,它是AddressBookReader的一个实例:
public class TransformationApp03 {static Document document;public static void main(String argv[]) {// ...// Create the sax "parser".AddressBookReader saxReader = new AddressBookReader();try {File f = new File(argv[0]);// ...}// ...}}
然后,以下突出显示的代码构造SAXSource对象
// Use a Transformer for output// ...Transformer transformer = tFactory.newTransformer();// Use the parser as a SAX source for inputFileReader fr = new FileReader(f);BufferedReader br = new BufferedReader(fr);InputSource inputSource = new InputSource(br);SAXSource source = new SAXSource(saxReader, inputSource);StreamResult result = new StreamResult(System.out);transformer.transform(source, result);
这里, TransformationApp03构造一个缓冲读取器(如前所述)并将其封装在输入源对象中。然后它创建一个SAXSource对象,将读取器和InputSource对象传递给它,并将其传递给变换器。
当应用程序运行时,变换器将自身配置为 SAX 解析器的ContentHandler ( AddressBookReader )并告诉解析器对inputSource对象进行操作。解析器生成的事件然后转到变换器,变换器执行适当的操作并将数据传递给结果对象。
最后, TransformationApp03不会产生异常,因此TransformationApp02中的异常处理代码不再存在。
运行TransformationApp03示例
导航至
样例目录。%cd install-dir / jaxp-1_4_2- 释放日期 /样例。
Download the XSLT examples by clicking this link并将它们解压缩到 install-dir/ jaxp-1_4_2-释放日期/样例目录。导航到
xslt目录。cd xslt
Compile the
TransformationApp03sample.键入以下命令:
% javac TransformationApp03.java
Run the
TransformationApp03sample on a data file you wish to convert to XML.在下面的例子中,
TransformationApp03运行在PersonalAddressBook.ldif文件上,在解压缩样例包后找到xslt / data目录。% java TransformationApp03data/PersonalAddressBook.ldif
您将看到以下输出:
<?xml version="1.0" encoding="UTF-8"?><addressbook><nickname>Fred</nickname><email>Fred@barneys.house</email><html>TRUE</html><firstname>Fred</firstname><lastname>Flintstone</lastname><work>999-Quarry</work><home>999-BedrockLane</home><fax>888-Squawk</fax><pager>777-pager</pager><cell>555-cell</cell></addressbook>
如您所见,LDIF 格式文件
PersonalAddressBook已转换为 XML!

若有收获,就点个赞吧
0 人点赞
