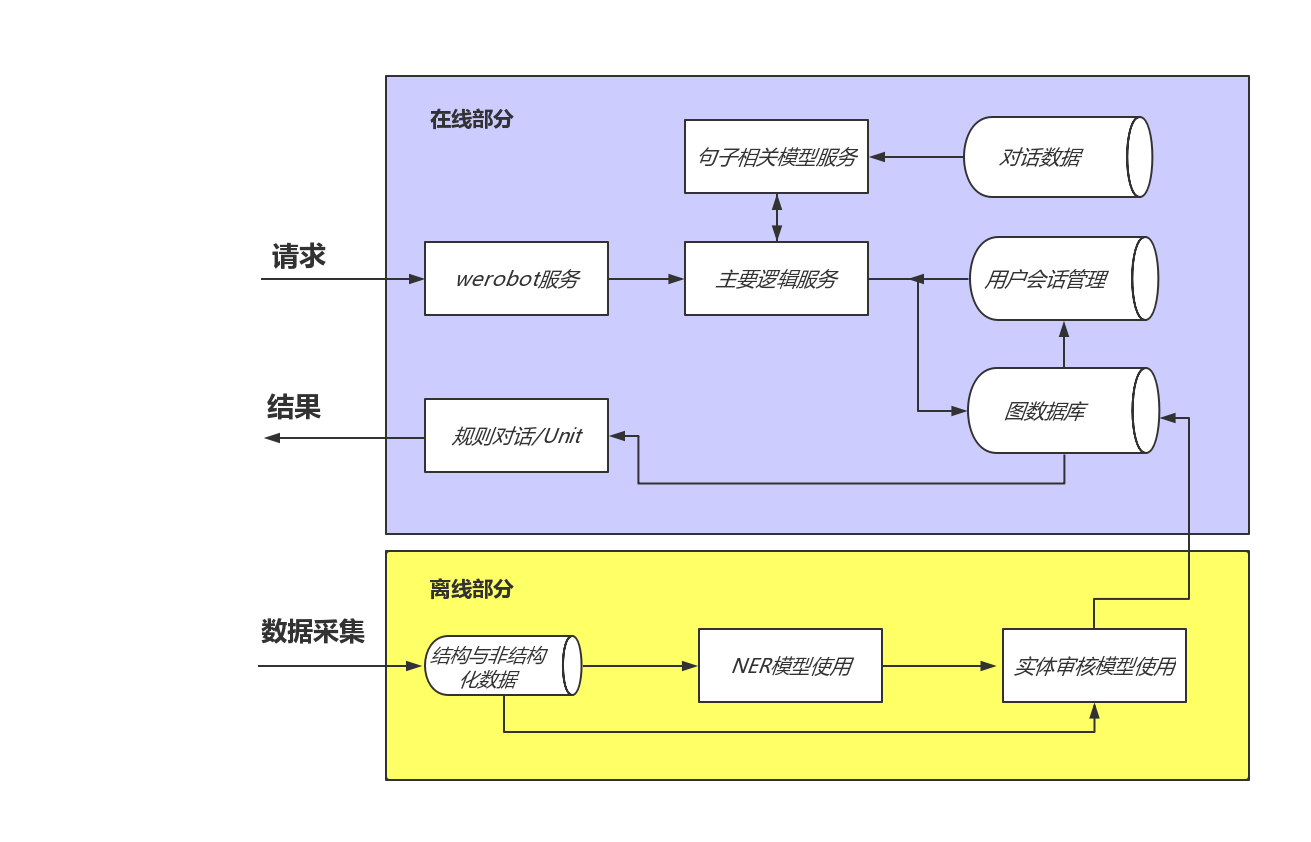
- 离线部分架构图:
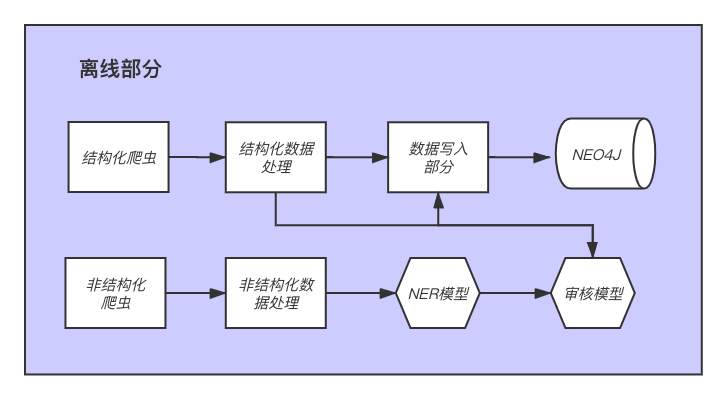
- 离线部分架构展开图:
- 离线部分简要分析:
- 根据架构展开图图,离线部分可分为两条数据流水线,分别用于处理结构化数据和非结构化数据. 这里称它们为结构化数据流水线和非结构化数据流水线.
- 结构化数据流水线的组成部分:
- 结构化数据爬虫: 从网页上抓取结构化的有关医学命名实体的内容.
- 结构化数据的清洗: 对抓取的内容进行过滤和清洗, 以保留需要的部分.
- 命名实体审核: 对当前命名实体进行审核, 来保证这些实体符合我们的要求.
- 命名实体写入数据库: 将审核后的命名实体写入数据库之中, 供在线部分使用.
- 非结构化数据流水线的组成部分:
- 非结构化数据爬虫: 从网页上抓取非结构化的包含医学命名实体的文本.
- 非结构化数据清洗: 对非结构化数据进行过滤和清洗, 以保留需要的部分.
- 命名实体识别: 使用模型从非结构化文本中获取命名实体.
- 命名实体审核: 对当前命名实体进行审核, 来保证这些实体符合我们的要求.
- 命名实体写入数据库: 将审核后的命名实体写入数据库之中, 供在线部分使用.
- 说明:
- 因为本项目是以AI为核心的项目, 因为结构化与非结构化的数据爬虫和清洗部分的内容这里不做介绍, 但同学们要知道我们的数据来源.

若有收获,就点个赞吧
0 人点赞
