- 一、难点
- 1.2 整体架构
- 二、智能信息填写系统
- 内部数据库配置, 这是由数仓工程师提供的
sql_config = {
“host”: “172.17.0.93”,
“user”: “ai_test”,
“password”: “DNdDxZ#jgLncWTH7”,
“database”: “ai”,
} - 打开数据库连接
db = pymysql.connect(**sql_config) - 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor() - 使用 execute() 方法执行 SQL 查询
# 编写sql语句,根据id取出指定范围的内容查看, 这里取前1000条
cursor.execute(“SELECT * fromt_aiWHERE 0 < id < 1000”) - 使用 fetchall() 方法获取全部数据.
data = cursor.fetchall() - 输出成csv或excel文件,这里是输出csv
# 输出excel使用df.to_excel API即可
df = pd.DataFrame(data)
df.to_csv(“./corpus.csv”) - 关闭数据库连接
db.close() - 设置显示风格
plt.style.use(“fivethirtyeight”) - 这里以给定的excel表格为输入
# 该数据可以在给定的原始代码中找到
# 可以将该段代码和数据拷贝到本地运行,查看可视化效果
path = “/data/coItcastBrain/原始数据已脱敏.xlsx” - 读取excel表格
original_data = pd.read_excel(path, “Sheet4”) - 我们会将”客户”的消息内容和”咨询师”的消息内容分开统计
# 分别获得对应的内容
user_original_data = original_data[original_data[“消息发送人”] == “客户”]
employee_original_data = original_data[original_data[“消息发送人”] == “咨询师”] - 分别在数据中添加新的句子长度列
user_original_data[“sentence_length”] = list(
map(lambda x: len(str(x)), user_original_data[“内容”])
) - 绘制客户对话句子的长度分布图
sns.distplot(user_original_data[“sentence_length”])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show() - 绘制客户对话句子的长度分布图
sns.distplot(employee_original_data[“sentence_length”])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show() - 先对长度超过50的句子进行过滤
user_original_data = user_original_data[user_original_data[“sentence_length”] <= 50] - 再去除多余的列,只留下“会话ID”和“内容”
df = user_original_data.drop(
[
“时间”,
“时间戳”,
“sentence_length”,
“姓名”,
“手机号”,
“QQ”,
“微信”,
“意向学科”,
“意向校区”,
“消息发送人”,
“专题页标题”,
“地区”,
],
axis=1,
) - 将DataFrame转成列表
# 形如[[会话ID1, 对应的内容1], [会话ID1, 对应的内容2],
# [会话ID2, 对应的内容1], [会话ID2, 对应的内容2]]
temp = df.values.tolist() - 使用以下过程将temp转换为[[会话ID1, 对应的内容1, 对应的内容2],
# [会话ID2, 对应的内容1, 对应的内容2]]
# 创建存储结果的空列表
result = [] - 对temp进行循环遍历
for index, item in enumerate(temp):
# 使对话列表中的每个元素都是字符串类型
item[1] = str(item[1])
# 遍历的第一个列表直接装进结果列表
if index == 0:
result.append(item)
else:
# 接下来遍历的每个列表中的会话ID要与已进入结果列表中的最后一个列表会话ID做比较
# 如果相同,说明是同一个对话块中的内容
if item[0] == result[-1][0]:
# 则将内容存到结果列表中的最后一个列表中
result[-1].append(item[1])
else:
# 否则说明是不同的对话块,则带着会话ID直接存进结果列表
result.append(item) - 打印转化后的结果
print(result) - 在正式编写获取意向学科函数之前,
# 我们需要编写两个辅助函数_get_resubject_config和_search_entity - 第二个辅助函数_search_entity
def _search_entity(info: str, resubject) -> list:
“””
根据反转的学科字典配置,在一段文本中找到可能的学科
:param info: 要查找是否存在学科实体的字符串
:param resubject: 反转的学科字典配置
return: 文本中可能存在的标准学科名字组成的列表
“””
# 首先遍历反转学科字典的key,并将在info中出现的key存入列表
entity = list(filter(lambda x: x in info, resubject.keys()))
# 之后根据这些key在字典中,找到他们对应的value,
entity = list(map(lambda x: resubject[x], entity))
return entity - 获取意向学科的函数
def get_subject(fromTitle, user_dialog_list, subject_config):
“””
获取意向学科函数
:param fromTitle: 专题页标题,这是咨询师系统能够采集到的辅助信息
:param user_dialog_list: 客户的每一次对话组成的列表
:param subject_config: 学科配置字典
return: 意向学科字典,形如: {‘subject’: NAME}, NAME为具体学科名
“””
# 与意向校区类似,首先初始化结果字典
subject_res = {“subject”: “unknown”}
# 使用辅助函数_get_resubject_config获得反转后的学科配置字典
resubject = _get_resubject_config(subject_config)
# 将输入的客户对话列表转换成字符串,与反转配置字典一同作为参数传给_search_entity
# 这样就可以得到在客户对话中可能存在的标准学科实体名字
entity = _search_entity(“ “.join(user_dialog_list), resubject)
# 因为我们最终的标准学科只能填写一个,所以对于entity列表需做一些处理
# 按照大学科优先的原则,我们会选择在列表中出现的第一个学科
if len(entity) >= 1:
subject_res[“subject”] = entity[0] - 使用规则识别人名
- 定义变量
teacher_dialog_list_with_index = [[“您好”, 1], [“您贵姓”, 2]]
user_dialog_list_with_index = [[“周”, 2]]
user_dialog_list = [“周”]
name_res = get_name_with_server(
user_dialog_list, user_dialog_list_with_index, teacher_dialog_list_with_index
)
print(name_res) - 消息发送人分为:
# 咨询师 —> employee
# 客户 —> customer - 引入同目录下的api.py和config.py
from . import api
from . import config - 接受POST请求,也就是url.py中指向的get_info函数
@api_view([“POST”])
def get_info(request):
“””
服务中获取系统结果的主函数
request为请求体,其中包含之前定义的标准输入JSON格式
我们将返回一个响应体,包含之前定义的标准输出JSON格式
“””
# 解析请求体, 获得标准的输入数据
data = json.loads(request.body.decode()) - 咨询师对话中每条允许的最大长度
teacher_length_limit = 100 - 客户在对话字典中对应的key
user_key = “customer” - 咨询师在对话字典中对应的key
teacher_key = “employee” - 传智现有学科及其常见的名称
subjects = {
“JavaEE”: [“Java”, “JAVA”, “jave”, “java”, “JavaEE”],
“Python”: [“python”, “pythen”, “PY”, “PYTHON”],
“大数据”: [“大数据”],
“C++”: [“C++”, “c”, “C”, “c++”, “c+”],
“UI设计”: [“ui”, “UI”, “Ui”, “uI”],
“产品经理”: [“产品”, “产品经理”],
“视觉设计”: [“视觉设计”],
“前端与移动开发”: [“前端”, “移动开发”],
“软件测试”: [“测试”],
“影视制作”: [“影视制作”],
“PMP认证”: [“PMP认证”],
“在线学习”: [“在线学习”],
“物联网区块链”: [“物联网”, “区块链”],
“机器人开发”: [“机器人”],
“微信小程序”: [“微信小程序”],
“全栈”: [“全栈”],
“新媒体”: [“新媒体”, “短视频”],
“电商运营”: [“电商运营”],
“PHP”: [“PHP”, “php”, “Php”],
“Linux运维”: [“Linux”, “运维”],
“Go区块链”: [“Go”, “go”],
“Java架构师”: [“架构师”, “Java架构师”],
} - 传智现有校区
schools = [
“北京”,
“深圳”,
“广州”,
“上海”,
“郑州”,
“杭州”,
“武汉”,
“西安”,
“南京”,
“长沙”,
“成都”,
“济南”,
“合肥”,
“厦门”,
“太原”,
“石家庄”,
“重庆”,
“沈阳”,
“天津”,
] - 最常见的100个姓氏
baijiaxing = [‘李’, ‘张’, ‘冯’, ‘王’, ‘刘’, ‘杨’, ‘陈’, ‘赵’, ‘黄’,
‘周’, ‘吴’, ‘徐’, ‘郑’, ‘马’, ‘朱’, ‘胡’, ‘郭’, ‘何’,
‘高’, ‘林’, ‘罗’, ‘孙’, ‘梁’, ‘谢’, ‘宋’, ‘唐’, ‘许’,
‘韩’, ‘邓’, ‘曹’, ‘彭’, ‘曾’, ‘萧’, ‘田’, ‘董’, ‘潘’,
‘袁’, ‘于’, ‘蒋’, ‘蔡’, ‘余’, ‘杜’, ‘叶’, ‘程’, ‘苏’,
‘魏’, ‘吕’, ‘丁’, ‘任’, ‘沈’, ‘姚’, ‘卢’, ‘姜’, ‘崔’,
‘钟’, ‘谭’, ‘陆’, ‘汪’, ‘范’, ‘金’, ‘石’, ‘廖’, ‘贾’,
‘夏’, ‘韦’, ‘傅’, ‘方’, ‘白’, ‘邹’, ‘孟’, ‘熊’, ‘秦’,
‘邱’, ‘江’, ‘尹’, ‘薛’, ‘阎’, ‘段’, ‘雷’, ‘侯’, ‘龙’,
‘史’, ‘陶’, ‘黎’, ‘贺’, ‘顾’, ‘毛’, ‘郝’, ‘龚’, ‘邵’,
‘万’, ‘钱’, ‘严’, ‘覃’, ‘河’, ‘戴’, ‘莫’, ‘孔’, ‘向’, ‘汤’] - http://0.0.0.0:8087/api/v1/get_info“
data = {
“sessionId”: “23243”,
“ip”: “中国 北京 北京”,
“fromTitle”: “黑马程序员C/C++与网络攻防培训官网-C/C++培训|C/C++与网络攻防培训机构”,
“content”: [
{“employee”: “你好,你是想了解哪个课程呢?¥还在么同学?”, “customer”: “价格?”},
{“employee”: “您好¥您想了解哪个专业的学费呢¥专业不同,学时学费也不一样”, “customer”: “C++”},
{“employee”: “贵姓”, “customer”: “周”},
{“employee”: “好的,可以给您发送一份C++的课程资料,学时学费和学习路线,您可以先了解看下”, “customer”: “好”},
],
}">请求路径,8087端口已经在nginx的配置中指定
# 它将代理uwsgi的5000端口
url = “http://0.0.0.0:8087/api/v1/get_info“
data = {
“sessionId”: “23243”,
“ip”: “中国 北京 北京”,
“fromTitle”: “黑马程序员C/C++与网络攻防培训官网-C/C++培训|C/C++与网络攻防培训机构”,
“content”: [
{“employee”: “你好,你是想了解哪个课程呢?¥还在么同学?”, “customer”: “价格?”},
{“employee”: “您好¥您想了解哪个专业的学费呢¥专业不同,学时学费也不一样”, “customer”: “C++”},
{“employee”: “贵姓”, “customer”: “周”},
{“employee”: “好的,可以给您发送一份C++的课程资料,学时学费和学习路线,您可以先了解看下”, “customer”: “好”},
],
} - 2.5 针对数据监控部门的反馈调整
- 初始化采集结果的列表
result = [] - 以下是四个示例函数:
一、难点
项目背景与需求
- AI平台的建设即是所谓”互联网产业化”的需求,又是一个公司AI成果落地的重要标志。
- 市面上,除了像BAT这样的大型企业有自己的AI平台外,像旷视(视觉),标贝(语音),图灵机器人(NLP)等中型科技公司也正在积极参与垂直领域AI平台的建设。
- 公司作为中国头部建筑机构,内部众多软件系统需要AI支持,同时,公司内又开设众多主流学科,如 java,python,前端等,这些所有学科在项目研发中也越来越需要AI赋能,生产更多能够复原企业化的项目产品。因此,”此”项目应运而生。
市场上的主流的AI平台
- 百度开放平台:
- 地址: https://ai.baidu.com/
- 试用接口: 自然语言处理 —> 情感倾向分析 —> 功能演示
- 标贝科技:
- 地址: https://www.data-baker.com/tts.html
- 试用接口: 语音合成 —> 产品体验
- 旷视科技:
- 地址: https://www.faceplusplus.com.cn/sdk/face-landmarks/
- 试用接口: 免费测试 —> 人脸识别功能 —> API演示
- 此平台:
- 地址: https://www. -ai.cn
- 试用接口: 自然语言处理 —> 文本标签化 —> API演示
1.2 整体架构
整体架构与分析
- 此整体架构简图:
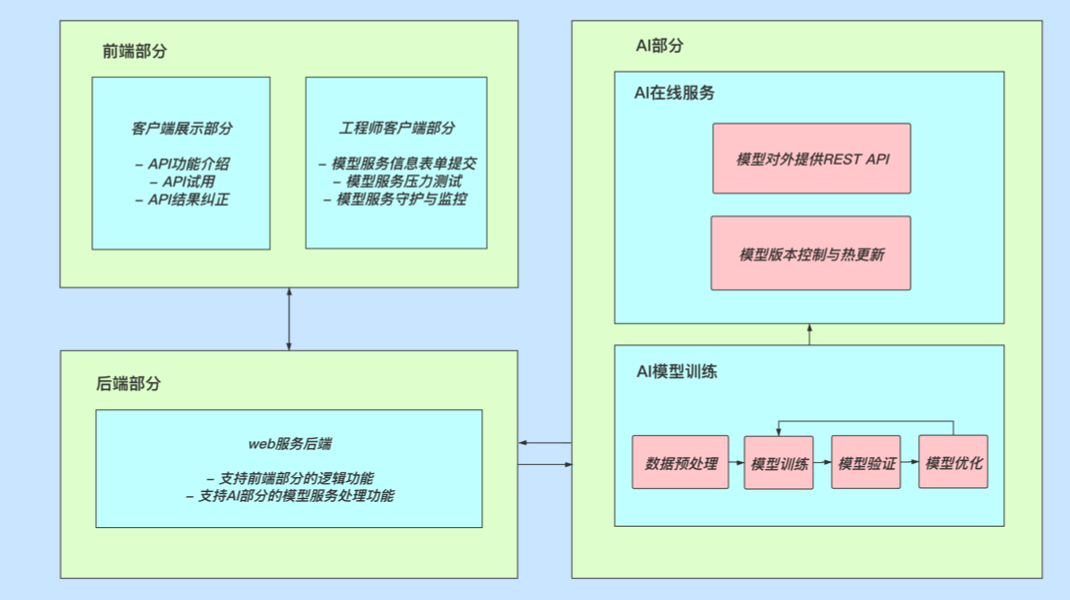
- 架构图分析:
- 首先,此由三个部分构成,分别是前端部分,后端部分和AI部分。
- 前端部分提供两个客户端,一是为普通用户展示和试用API的界面;二是为AI工程师提供模型服务提交和测试监控的界面。
- 后端部分是连接前端部分和AI部分的重要桥梁,实现除AI功能部分的全部逻辑,如用户请求逻辑,数据反馈逻辑,模型服务测试等。
- AI部分即AI工程师需要负责完成的部分,里面有两大模块:AI在线服务(模型部署)和AI模型训练。在模型部署时,我们需要考虑版本控制和热更新,以及对外提供可被调用的REST API。在模型训练部分,我们会进行标准的数据预处理,模型训练,模型验证,以及根据不同需求的模型优化。
- 在架构图分析中,重点是明确AI工程师负责的AI部分。
此当前版本提供的AI功能
- 此v1.0 AI功能简图:
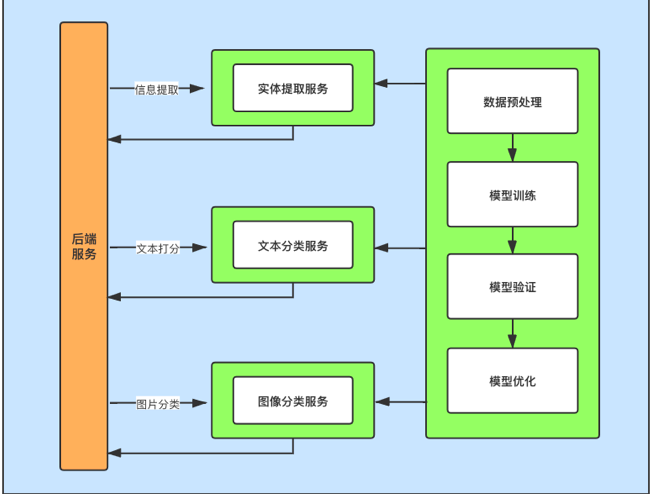
- AI功能简图分析:
- v1.0版本共对外开放三个AI功能,分别是信息提取,文本分类,图片分类。
- 每个AI功能背后都是对应的AI服务和标准模型训练过程。并且每个功能服务又对应不同的项目场景需求。
- 信息提取功能是NLP的功能之一,主要支持 公司信息中心网络咨询部门的需求,帮助他们在客户咨询过程中自动提取关键信息,提升信息填写效率。
- 文本分类功能是NLP的功能之一,主要用于支持 公司考试中心的教辅系统,帮助教师自动批阅相关的填空题。
- 图片分类功能是CV的功能之一,主要用于 公司数据分析对全国咨询情况的统计,通过对咨询照片的分析来进行推断线上咨询还是线下咨询。
二、智能信息填写系统
2.1 背景需求与分析
学习目标
- 了解该系统的背景需求。
-
背景需求
信息中心信息填写部门每天需要完成大量的网络咨询任务,他们需要与客户进行沟通,并且在完成对话后,提取意向报名客户的相关信息,比如:客户姓名,客户意向学科,客户意向校区,客户的电话/微信/QQ号等。而这些工作当前都是需要在对话结束后人工完成。
- 在实际工作中,咨询师们并不能专心填写这些信息,因为他们需要同时和其他客户聊天,因此很容易导致信息的错填/漏填,对后续回访工作带来麻烦,并且很大程度影响了与其他客户的沟通质量。
- 正因如此,信息中心希望我们能够帮助解决这一问题,利用人工智能等相关技术自动提取重要信息,实现表单填写的自动化,我们称这一系统为智能信息填写系统。
需求分析
通过上述背景需求,我们首先明确以下几点:
- 系统输入: 咨询师和客户的一次完整对话块(包括双方的每轮对话内容)。
- 系统输出: 输入对话块中包含的客户信息,如客户姓名,客户意向学科,客户意向校区,客户的电话/微信/QQ号等。
- 在线服务: 咨询师在每次完成对话后请求服务并获得结果,因此系统处理过程需要实时响应。又因为我们当前的咨询师具有一定规模,因此系统服务需要承受一定的并发压力。
- 根据调研,我们的系统处理过程能够保持在100ms左右即可满足用户实时需求。又因为我们的咨询师总数在500名左右,因此我们服务能够满足QPS(每秒请求数)大于500即可满足并发要求。
以上这些也是我们最终需要交付系统的要求。
小节总结
- 学习了系统背景需求:
- 利用人工智能等相关技术自动提取重要信息,实现表单填写的自动化,提升信息填写工作效率。
- 学习了交付系统要求:
- 明确了输入,输出和在线需求。
2.2 产品形态与效果展示
学习目标
- 了解系统的最终产品形态。
- 了解系统的产品设计逻辑。
产品形态
- 在原有的客户表单填写页面多出了一”自动填写”按钮,点击按钮后即可获得填充信息。
产品设计逻辑
- 以下图片由产品经理提供:
小节总结
- 学习了产品的最终形态。
- 学习了系统的输入输出过程,让我们对系统有了更加直观的认识。
2.3 整体解决方案初定
学习目标
- 了解初始整体解决方案的作用。
- 了解初始整体解决方案的各个步骤。
初始整体解决方案的作用
初始整体解决方案一般是在与产品,运营讨论需求后制定技术解决方案。在这个时间点上,AI工程师往往还没有拿到真实线上数据,只能通过需求描述来假设数据情况,并根据这种情况制定方案。
- 该方案主要基于我们之前的类似项目经验,一方面帮助我们初步梳理整个处理思路和流程,另一方面给合作部门人员彰显我们是可以胜任这项工作的(这对于团队之间的合作来讲至关重要,我们需要先有一定的表示才能获得信任)。
初始整体解决方案一般是一个细节不够完善的方案,但是它已经有了一个大体的解决框架,在之后的真实数据下和开发过程中不断优化。
初始整体解决方案的环节
- 第一步: 明确问题并提出数据要求
- 第二步: 对原始数据进行数据分析
- 第三步: 使用AI模型判断咨询师对话中的问题类型
- 第四步: 使用不同规则/模型匹配目标实体
- 第五步: 模型部署服务概述
- 第六步: 总结与改进
第一步: 明确问题并提出数据要求
- 明确问题:
- 从对话块文本中提取关键信息(也可以叫做”实体”,如:姓名,微信,意向学科,意向校区等)
- 数据要求:
- 为了保证数据时效性,要求数据方提供近期(半个月内)对话块数据及其标注的目标实体,对话块数量至少10000个。(真实企业环境下,我们要求的数据量越多,操作起来的审批流程就会越麻烦,因此前期的数据量要求一般少于10000,随着我们将模型服务建成,让大家体验到效果,再去申请大量数据才可以被接受,这也是部门间合作的过程。)
第二步: 对原始数据进行数据分析
数据分析指标:
1,统计文本长度分布
- 作用: 通过分布情况决定长度合法性检验的范围(为了保证实时,需要限定每次解析的文本长度)。
2,统计文本中各个主要实体真实出现频率
- 作用: 用于确定各个实体识别的优先等级。
第三步:使用模型判断咨询师对话中的问题类型
根据对话的有序性,即答案一定出现在问题之后。通过快速定位问题来缩小目标实体(答案)搜索范围,避免使用大量文本进行匹配,降低延迟时间。
- 根据当前的硬件设备和在线需求,我们将选择具有快速推断优势的模型,简单过程如下:
- 1,采集并标注不同类型问题的样本数据
- 2,训练并验证fasttext进行模型多分类
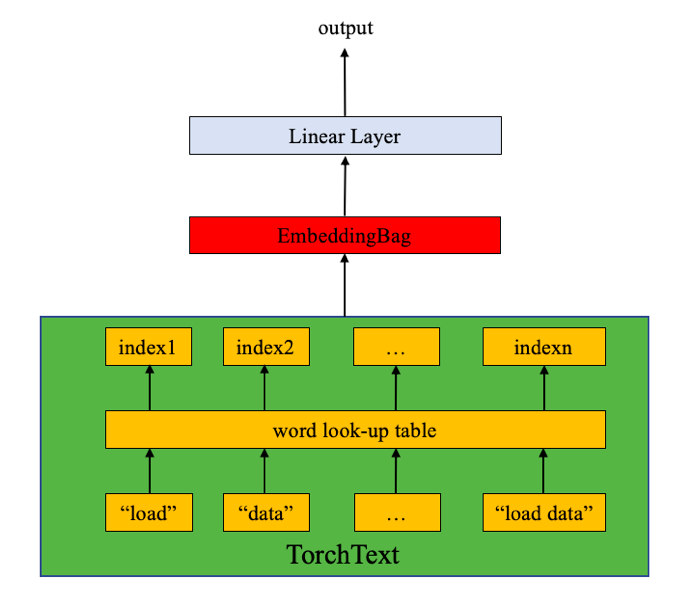
第四步:使用不同规则/模型匹配目标实体
根据第二步问题所在位置,在接下来的有限范围内(一般取该问题后客户回答的三句文本)进行实体匹配/识别。
- 1,姓名识别:
- 使用公开的人名识别模型(中文人名识别是比较成熟的任务)
- 2,手机/微信/QQ号匹配:
- 使用正则表达式进行匹配
- 3,意向校区/学科匹配:
- 因为校区和学科都是有限集,可以直接使用规则匹配
第五步: 模型部署服务概述
- 总体服务架构设计
- 使用基于Django的服务框架。
- 使用nginx作为反向代理和负载均衡。
- 使用supervisor作为单服务守护与监控。
- 使用uwsgi作为高性能web server。
- 模型服务封装
- 基于tensorflow/keras框架开发的模型使用tf-serving进行封装,以保证服务健壮性以及模型热更新。
- 基于pytorch框架开发的模型使用flask框架进行封装,使用交替双服务保证模型热更新。
- 系统联调与测试
- 与外界服务使用REST API(http)进行交互。
- 输入与输出为规范json格式。
- 根据实际接口调用情况,进行并发压力测试。
- 灰度发布,进行可用性测试。
服务器资源
模型训练服务器:
- CPU: 8C,16G内存,100G硬盘
模型部署服务器:
- CPU: 8C,16G内存,100G硬盘,1M带宽
第六步: 总结与改进
- 上述方案皆基于在对话过程中以信息填写为主导的假设情况,而在实际数据中可能存在大量非该类数据,之后将通过对真实数据的分析提出更加具有普适性的解决方案。
- 所有基于规则的方法皆可根据性能和覆盖率进行模型拓展。
- 学习了初始整体解决方案的各个步骤:
- 第一步: 明确问题并提出数据要求
- 第二步: 对原始数据进行可视化数据分析
- 第三步: 使用AI模型判断咨询师对话中的问题类型
- 第四步: 使用不同规则/模型匹配目标实体
- 第五步: 模型部署服务概述
- 第六步: 总结与改进
2.4 整体解决方案实施与调整
学习目标
- 掌握整体解决方案的实施步骤和代码实现。
- 掌握根据真实数据情况作出的一些方案调整和代码实现。
整体解决方案的实施步骤
- 第一步: 获取指定数据并进行数据分析
- 第二步: 根据分析结果进行非模型识别部分代码实现
- 第三步: 进行模型识别部分分析和部署实现
- 第四步: 整体服务部署与联调测试
第一步: 获取指定数据并进行数据分析
根据之前的”数据要求”,请参见初始整体解决方案的环节: 明确问题并提出数据要求,我们将从数仓人员手中获得指定数据,一般情况下,每个对话块包含10条左右的句子,10000个对话块就是十万条文本,公司的数仓工程师会为我们建立一个特定的sql数据库,为了保证数据安全,这样的数据库都会建在公司内网服务器上,然后将数据存入其中,我们根据需求自己获取。(如果数据要求再少一些的话,可能直接给你一个excel表格)
- 从特定sql数据库中获得指定数据:
#!/usr/bin/python3
# 请安装mysql工具:pip install pymysql
import pandas as pd
import pymysql
内部数据库配置, 这是由数仓工程师提供的
sql_config = {
“host”: “172.17.0.93”,
“user”: “ai_test”,
“password”: “DNdDxZ#jgLncWTH7”,
“database”: “ai”,
}
打开数据库连接
db = pymysql.connect(**sql_config)
使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
使用 execute() 方法执行 SQL 查询
# 编写sql语句,根据id取出指定范围的内容查看, 这里取前1000条
cursor.execute(“SELECT * from t_ai WHERE 0 < id < 1000”)
使用 fetchall() 方法获取全部数据.
data = cursor.fetchall()
输出成csv或excel文件,这里是输出csv
# 输出excel使用df.to_excel API即可
df = pd.DataFrame(data)
df.to_csv(“./corpus.csv”)
关闭数据库连接
db.close()
- 代码位置:
- 内网服务器的/data/coItcastBrain/fetch_data.py
输出效果:
- 在当前目录下生成corpus.csv或corpus.xlsx文件
- 文件内容如下图所示(这里为了清晰显示和说明使用excel打开)
- 内网机器IP:172.17.0.228
数据说明:
- 由于数据涉及用户隐私,学生无法请求内网数据库,但是可以直接使用给定的部分脱敏数据(如上图excel形式)。
- 通过上图表格,我们可以看到共有13列(13个字段),分别是”会话ID”,”时间”,”时间戳”,”内容”,”消息发送人”,”姓名”,”手机号”,”QQ”,”微信”,”意向校区”,”意向学科”,”专题页标题”,”地区”。下面对每个字段分别解释。
- 会话ID:整个对话块的唯一标识,用于区分消息内容是否为同一次对话。
- 时间:该条消息发送出去的具体结构化时间。
- 时间戳:该条消息发送出去的时间戳。
- 内容:该条消息的具体内容。
- 消息发送人:该条消息是由谁发送的,这里只有”客户”和”咨询师”两种。
- 姓名:咨询师通过对话获得的客户姓名。从”姓名”字段开始为非对话块本身的字段,而是咨询师通过对话块填写的客户信息或其他辅助信息。
- 手机号:咨询师通过对话获得的客户手机号。
- QQ:咨询师通过对话获得的客户QQ号。
- 微信:咨询师通过对话获得的客户微信号。
- 意向校区:咨询师通过对话获得的客户意向校区。
- 意向学科:咨询师通过对话获得的客户意向学科。
- 专题页标题:这是一个咨询师辅助信息,代表客户通过官网中哪个页面进行咨询的。这个信息咨询师使用的系统是可以获得的。
- 地区:这也是一个辅助信息,代表客户使用的终端所在IP地区。这个信息咨询师使用的系统也是可以获得的。
- 根据初始整体解决方案的环节: 对原始数据进行数据分析进行数据分析:
- 统计文本长度分布的实现:
# 导入必备工具包
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
设置显示风格
plt.style.use(“fivethirtyeight”)
这里以给定的excel表格为输入
# 该数据可以在给定的原始代码中找到
# 可以将该段代码和数据拷贝到本地运行,查看可视化效果
path = “/data/coItcastBrain/原始数据已脱敏.xlsx”
读取excel表格
original_data = pd.read_excel(path, “Sheet4”)
我们会将”客户”的消息内容和”咨询师”的消息内容分开统计
# 分别获得对应的内容
user_original_data = original_data[original_data[“消息发送人”] == “客户”]
employee_original_data = original_data[original_data[“消息发送人”] == “咨询师”]
分别在数据中添加新的句子长度列
user_original_data[“sentence_length”] = list(
map(lambda x: len(str(x)), user_original_data[“内容”])
)
employee_original_data[“sentence_length”] = list(
map(lambda x: len(str(x)), employee_original_data[“内容”])
)
print(“绘制客户对话句子长度分布图:”)
# 绘制客户对话句子长度的数量分布图
sns.countplot(“sentence_length”, data=user_original_data)
# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看
plt.xticks([])
plt.show()
绘制客户对话句子的长度分布图
sns.distplot(user_original_data[“sentence_length”])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show()
print(“绘制咨询师对话句子长度分布图:”)
# 绘制咨询师对话句子长度的数量分布图
sns.countplot(“sentence_length”, data=employee_original_data)
# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看
plt.xticks([])
plt.show()
绘制客户对话句子的长度分布图
sns.distplot(employee_original_data[“sentence_length”])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show()
- 代码位置:
- /data/coItcastBrain/data_analysis.py
- 输出效果:
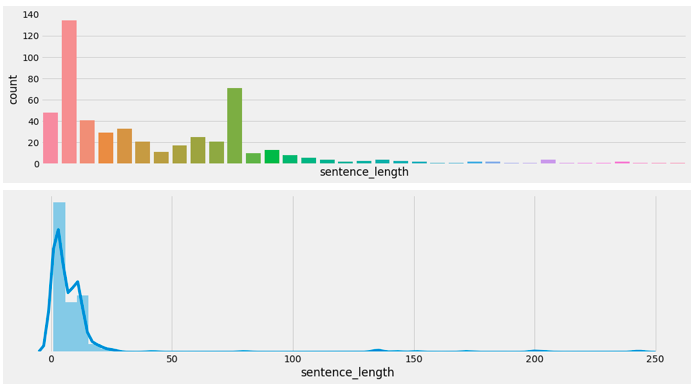
- 绘制客户对话句子数量-长度分布图:
- 绘制咨询师对话句子数量-长度分布图:
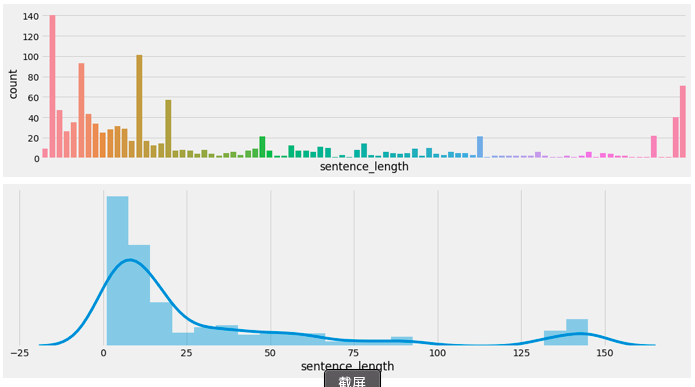
- 分析:
- 根据对话句子长度分布图分析,大多数情况下,客户单次对话长度限定在小于50的位置即可覆盖90%左右的情况;咨询师单次对话长度限定在小于100的位置即可覆盖90%左右的情况。意味着在之后超过限定长度的句子将不再被处理,用以减少计算压力。
- 为了验证被忽略的句子确实作用不大,我们可以在找到限定长度后进行超限句子抽样查看。通过以下代码进行打印查看:
# 对客户和咨询师的超限句子进行抽样查看, 这里抽样10条数据
print(“客户超限句子查看:”)
print(user_original_data[user_original_data[“sentence_length”] > 50][“内容”][:10])
print(“咨询师超限句子查看:”)
print(employee_original_data[employee_original_data[“sentence_length”] > 100][“内容”][:10])
- 输出效果:
- 客户超限句子查看:
17 来源:<a target='_blank' href='http://www.itheima...
50 会话来源于

若有收获,就点个赞吧
0 人点赞
